 百木园
百木园之前一哥们在国外面试的时候,就是要他做的这个,直接给他说,做出来了给你15K,做不出来就拜拜~
大兄弟当时就不服了,这不是看不起我么,分分钟就给整完了~

唠唠叨叨
那我们直接开整,像我们练手的话,装好Python和pycharm就OK了,没安装的话先安装好,这里我就不写了。
1、主要知识点
- 爬虫基本流程
- 非结构化数据解析
- 表格类型数据保存
2、第三方库安装的几种方法
requests
parsel
直接pip安装即可
1)、cmd中使用pip命令安装
win+r打开搜索出入cmd 按回车确认

然后在弹出来的命令提示符窗口输入pip安装指令加上模块,比如安装requests , 输入 pip install requests 按回车即可 。

2)、在pycharm设置里安装


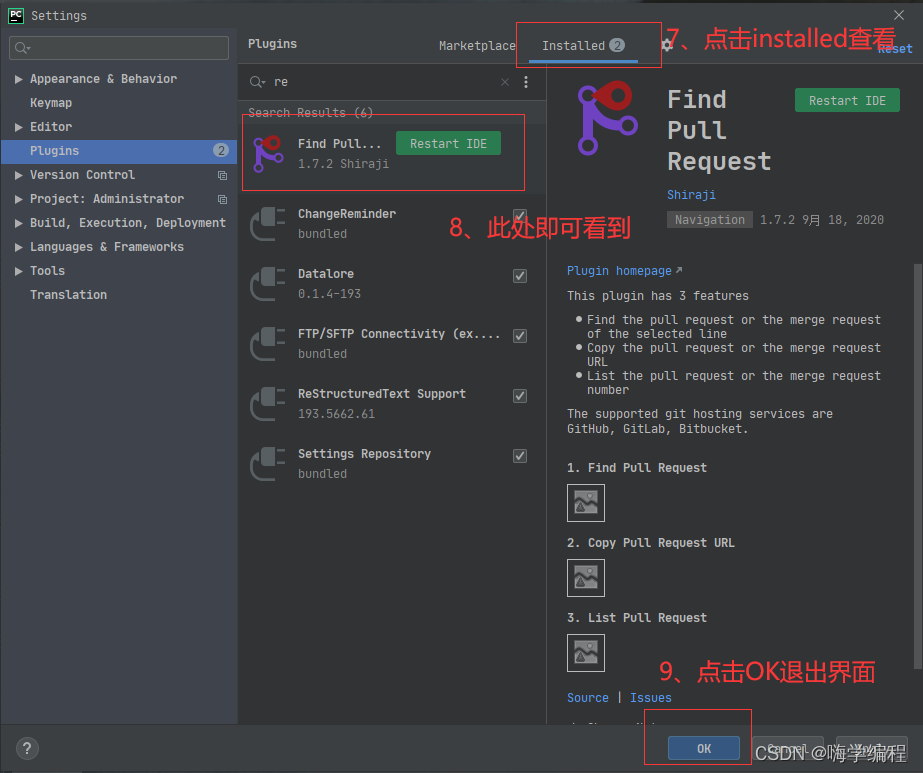
3)、在pycharm使用pip命令安装
输入 pip install requests 按回车即可

代码部分
1、代码实现流程
- 发送请求(访问网站)
- 获取数据(网页源代码)
- 解析数据(提取我们想要的数据内容 详情页链接)
- 发送请求(访问所有的详情页链接) 获取数据
- 解析数据(提取到我们想要的数据内容)
- 保存数据
2、代码展示
导入模块
import requests import parsel import re import csv
伪装
headers = { \'cookie\': \'TADCID=foOmU9bDp6JGIXg2ABQCFdpBzzOuRA-9xvCxaMyI12wTEaQSQ4euq_1sNSDmJybFCMezFLrAnKRGZ_uvGNNO_9cSzuJeK8RQlE4; TAUnique=%1%enc%3AHARC1EMLan58P07MI4ZMcqI%2BzHGWuLGBt6TE6zQDNwk%3D; TASSK=enc%3AAL%2Bm9xwFy7%2BjYONIRS%2F2kEbA%2FtOrlDbcW%2FwCSHs44XP9R3ddE%2BKJxi3FiDuozLe0Ov2ujtnFah8i0sN%2FRdUxZGis0TClwsaz7%2B7Uv8dh%2BvHM%2FfH9C%2FcEYLBYBtn1yLmBNg%3D%3D; ServerPool=A; PMC=V2*MS.2*MD.20220311*LD.20220311; TART=%1%enc%3AfD9OzCOGTHLKxR1qLNfmGZurd9xliidHT5bmQw2z505WnDQeBJdPDWc64WFlxikpNox8JbUSTxk%3D; TATravelInfo=V2*A.2*MG.-1*HP.2*FL.3*RS.1; TASID=9CCF4EA45B4141A8B5E4F03D36821474; ak_bmsc=31083286436C157F558D959D23D94849~000000000000000000000000000000~YAAQqF1kX6lPsVF/AQAAhTyqdw8F4+OoWZwjJCqsKUS/ykkFQHkXml5We7WY4q6KDUeIkm36a0Fs41jt7Jx6MFwnzloND2Iry1Iuwnj5I7oPxsI1RTjfGXSr408rscnzKPJHpRIXwuuiL+SNZxp233DOhrqrbTQ2cDTiGPk8qAYcLYq1OHpyOjLpc6L2zPbiSdvfDAuz2ujLUbWZV33YVrUd1UcmBMKJOSS/C12JeFdLCcjOihJvc4Zlu5HMYQUBdjTaV4zll3YO9YWxdm5pUT57vjI3WjxNhLwOXS93F3ogo/VOzmvk2n4rptCDH1vffz7Dpmp4yRn0dnX8RtiKiolFV00rBs0yC9Nxa67F0qPkJMMS6t6pNo+08PIre7VIiAIxQoWUNNiBiNDXeQ==; PAC=AHc5Ocqizh5jbN81AnjCtcF7k5P54vojrezhxeu8s4DdhkIZSMBuxXUioaVGVVo99Ysr_IbYXqNKjsddfzI8psluCp1NwuwQiBOvmdhP_r8ntVPeHXBc5u782Y8i4KrpV0a29aTnmykzihOxeEfilEfHZOGZxkWN8GRLwHay1MUpBazo7e4Pdtl3tndoYnNIDWcRtHzZJIDE9odWhqOzUE0%3D; TAReturnTo=%1%%2FRestaurants-g188590-Amsterdam_North_Holland_Province.html; roybatty=TNI1625!AJyUZ5ejQVombB9Jv3PVhqqhyMhwsanzT2C6omYz8l6mQNt%2FP5v6CLnnlymNXfhMwolnHznm%2BAmT81YSeygcVxnWHERn16eR747rX9fmWmeCMoris6ffxKTbJ6%2BjObZ6rmffv7I5wEGZ009WzKMlVA%2BXJAheGoIKHOD3gUDLVYlY%2C1; TATrkConsent=eyJvdXQiOiIiLCJpbiI6IkFMTCJ9; TASession=V2ID.9CCF4EA45B4141A8B5E4F03D36821474*SQ.9*LS.PageMoniker*GR.82*TCPAR.12*TBR.1*EXEX.98*ABTR.74*PHTB.27*FS.67*CPU.8*HS.recommended*ES.popularity*DS.5*SAS.popularity*FPS.oldFirst*LF.en*FA.1*DF.0*TRA.false*LD.188590*EAU._; TAUD=LA-1646980142821-1*RDD-1-2022_03_11*LG-863371-2.1.F.*LD-863372-.....; _pbjs_userid_consent_data=3524755945110770; _li_dcdm_c=.tripadvisor.com; _lc2_fpi=b140173de591--01fxvvhm5q52dte42gshbn1234; __gads=ID=887c76ae8964a5bc:T=1646981079:S=ALNI_MYwTZNsJPdidCGF3BTM3pOV79wAUg; _lr_sampling_rate=100; _lr_retry_request=true; _lr_env_src_ats=false; __li_idex_cache=%7B%7D; pbjs_li_nonid=%7B%7D; __vt=bI5Nl4_3wIiyQqd-ABQCIf6-ytF7QiW7ovfhqc-AvRvwyUuxl21BvNUgBcewLtYtxhD9pK8plYHHUPpFuGJQzlL9HjsNiQXGwLu0f-XidRXohA9m08ary-La12XkjuKCU2QeR3ijnhWjQ8bnjvOcAaUKoA; bm_sv=867C80B13B2E8AE707E1A411B950E849~HDnKV8jbSFu9eHNiLb/p3fK3KqcxdMjPpLXFMD9YvvwLoQEuDGPgZZwEDhQeezJZJhdrUxX02mvzmDqkV7615Fm508wASvLcLsXmW/6+1K9pDp2UuCDIYbuZgv/2m76YS7Og/SBcU6xkIVnHhMVqpxWfro/1T3kO1LdXuFuprhA=; OptanonConsent=isGpcEnabled=0&datestamp=Fri+Mar+11+2022+14%3A53%3A51+GMT%2B0800+(%E4%B8%AD%E5%9B%BD%E6%A0%87%E5%87%86%E6%97%B6%E9%97%B4)&version=6.30.0&isIABGlobal=false&hosts=&consentId=cc7e2f72-5007-428f-a72e-392f9741b69d&interactionCount=1&landingPath=https%3A%2F%2Fwww.tripadvisor.com%2FRestaurants-g188590-Amsterdam_North_Holland_Province.html&groups=C0001%3A1%2CC0002%3A1%2CC0003%3A1%2CC0004%3A1\', \'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36\', }
发送请求(访问网站)
response = requests.get(url, headers=headers) # Python学习交流群 815624229
获取数据(网页源代码)
html_data = response.text
解析数据(提取我们想要的数据内容 详情页链接)
selector = parsel.Selector(html_data)
提取标签的属性内容 ::attr(href) 链接
link_list = selector.css(\'.bHGqj.Cj.b::attr(href)\').getall() for link in link_list: link = \'tripadvisor/\' + link
发送请求(访问所有的详情页链接) 获取数据
detail_html = requests.get(link, headers=headers).text
解析数据
detail_selector = parsel.Selector(detail_html) store_name = detail_selector.css(\'.fHibz::text\').get() comment_count = detail_selector.css(\'.eSAOV.H3:nth-child(2) .eBTWs::text\').get() address = detail_selector.css(\'.eSAOV.H3:nth-child(3) .dyeJW.dUpPX:nth-child(1) .fhGHT::text\').get() city = detail_selector.css(\'.breadcrumbs li:nth-child(4) span::text\').get() phone = detail_selector.css(\'.eSAOV.H3:nth-child(3) .dyeJW.dUpPX:nth-child(2) .fhGHT a::text\').get() score = detail_selector.css(\'.eEwDq .fdsdx::text\').get() website = re.findall(\',\"website\":\"(http.*?)\"\', detail_html)[0] print(store_name, comment_count, city, address, phone, score, link, website)
保存数据
with open(\'tripadvisor.csv\', mode=\'a\', newline=\'\', encoding=\'utf-8\') as f: csv_writer = csv.writer(f) csv_writer.writerow([store_name, comment_count, city, address, phone, score, link, website])
翻页
for page in range(0, 131, 30): print(f\'-------------------正在爬取第{page+1}页-------------------\') url = f\'tripadvisor/RestaurantSearch?Action=PAGE&ajax=1&availSearchEnabled=true&sortOrder=popularity&geo=188590&itags=10591&eaterydate=2022_03_11&date=2022-03-12&time=20%3A00%3A00&people=2&o=a{page}\'
地址我都屏蔽了,大家自己补全一下www. .com
兄弟们,帮我动动小手,点个赞+收藏,还可以顺便评论一下,下次给大家弄个Python 30k 岗位的面试题补充一下点赞花掉的体力,嘿嘿~

来源:https://www.cnblogs.com/hahaa/p/16010026.html
本站部分图文来源于网络,如有侵权请联系删除。