 百木园
百木园索引的本质
MySQL索引或者说其他关系型数据库的索引的本质就只有一句话,以空间换时间。
索引的作用
索引关系型数据库为了加速对表中行数据检索的(磁盘存储的)数据结构
索引的分类
数据结构上面的分类
-
HASH 索引
- 等值匹配效率高
- 不支持范围查找
-
树形索引
-
二叉树,递归二分查找法,左小右大
-
平衡二叉树,二叉树到平衡二叉树,主要原因是左旋右旋
- 缺点1,IO次数过多
- 缺点2,IO利用率不高,IO饱和度
-
多路平衡查找树(B-Tree)
- 特点,大大的减少了树的高度
-
B+树
-
特点,采用左闭合的比较方式
-
根节点支节点没有数据区,只有叶子结点才包含数据区(说白了就是即便在根节点和子节点已经定位到,因为没有数据区的原因也不会停留,会一直找到叶子结点为止。)
- 当我们搜索13这条数据时,在根节点和子节点 都能定位,但是一直会找到叶子结点。

-
二叉树平衡二叉树,B树对比
如图显示如果是自增主键情况下:
二叉树显然不适合做关系型数据库索引(和全表扫描没什么区别)。
平衡二叉树呢,虽然解决了这种情况,但是同样会导致这棵树,又瘦又高,这同样会造成上文所提到查询IO次数过多以及IO利用率不高。
B树呢,显然已经解决了这两个问题,所以下文来解释,为什么在这种情况下MySQL还用了B+树,又做了那些增强。
-


B树和B+树比较

-
B+树在B树上面的优化
-
IO效率更高(B树每个节点都会保留数据区,而B+树则不会,假设我们查询一条数据要遍历三层,那么显然B+树查询中IO消耗更小)
-
范围查找效率更高(如图,B+树已经形成了一个天然链表形式,只需要根据最结尾的链式结构查找)

-
基于索引的数据扫描效率更高。
-

索引类型的分类
-
索引类型可分为两类:
- 主键索引
- 辅佐索引(二级索引)
- 唯一性索引
- 复合索引
- 普通索引
- 覆盖索引
主键索引相对来说性能是最好的,但是对于SQL优化,其实大多时候我们都在辅佐索引上面做一些改进和补充。
B+树在储存引擎层面落地
-
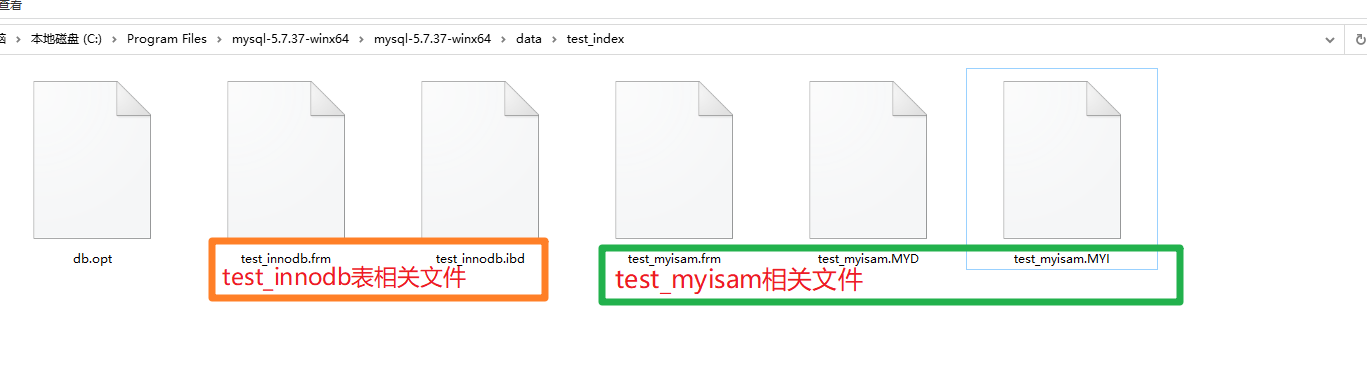
我们创建两个表分别为test_innodb(采用InnoDB作为储存引擎)test_myisam(采用MyISAM作为储存引擎)下图是两张表磁盘落地的相关文件,这两个储存引擎在B+树磁盘落地式截然不同的。

B+树在MyISAM落地
- *.frm文件是表格骨架文件比如这个表中的id字段name字段是什么类型的存储在这里
- *.MYD(D=data)则储存数据
- *.MYI (I=index)则储存索引

-
比如现在执行如下sql语句 ,那么在MyISAM中他就是先在test_myisam.MYI中查找到103然后拿到0x194281这个地址然后再去test_myisam.MYD中找到这个数据返回。
SELECT id,name from test_myisam where id =103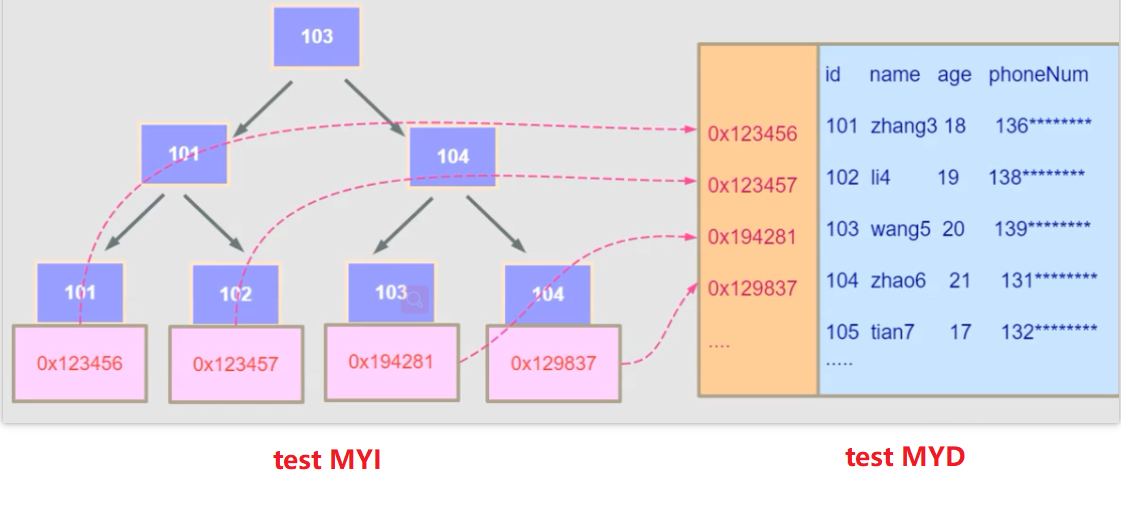
-
如果test_myisam表中,id为主键索引,name也是一个索引,那么在test_myisam.MYI中则会有两个平级的B+树,这也导致MyISAM引擎中主键索引和二级索引是没有主次之分的,是平级关系。因为这种机制在MyISAM引擎中,有可能使用多个索引,在InnoDB中则不会出现这种情况。

B+树在InnoDB落地


-
InnoDB不像MyISAM来独立一个MYD 文件来存储数据,它的数据直接存储在叶子结点关键字对应的数据区在这保存这一个id列所有行的详细记录。
-
InnoDB 主键索引和辅助索引关系
我们现在执行如下SQL语句,他会先去找辅助索引,然后找到辅助索引下101的主键,再去回表(二次扫描)根据主键索引查询103这条数据将其返回。
SELECT id,name from test_myisam where name =\'zhangsan\'这里就有一个问题了,为什么不像MyISAM在辅助索引下直接记录磁盘地址,而是要多此一举再去回表扫描主键索引,这个问题在下面相关面试题中回答,记一下这个问题是这里来的。

相关面试题
-
为什么MySQL选择B+树作为索引结构
这个就不说了,上文应该讲清楚了。
-
B+树在MyISAM和InnoDB落地区别。
这个可以总结一下,MyISAM落地数据储存会有三个类型文件 ,.frm文件是表骨架文件,.MYD(D=data)则储存数据 ,.MYI (I=index)则储存索引,MyISAM引擎中主键索引和二级索引平级关系,在MyISAM引擎中,有可能使用多个索引,InnoDB则相反,主键索引和二级索有严格的主次之分在InnoDB一条语句只能用一个索引要么不用。
-
如何判断一条sql语句是否使用了索引。
可以通过执行计划来判断 可以在sql语句前explain/ desc
set global optimizer_trace=\'enabled=on\' 打开执行计划开关他将会把每一条查询sql执行计划记录在information_schema 库中OPTIMIZER_TRACE表中
-
为什么主键索引最好选择自增列?
自增列,数据插入时整个索引树是只有右边在增加的,相对来说索引树的变动更小。
-
为什么经常变动的列不建议使用索引?
和上一个问题原因一样,当一个索引经常发生变化,那么就意味这,这个缩印树也要经常发生变化。4
-
为什么说重复度高的列,不建议建立索引?
这个原因是因为离散性,比如说,一张一百万数据的表,其中一个字段代表性别,0代表男1代表女,把这字段加了索引,那么在索引树上,将会有大量的重复数据。而我们常见的索引建立一般都是驱动型的。其目的是,尽可能的删减数据的查询范围,这个显然是不匹配的。
-
什么是联合索引
联合索引是一个包含了多个功效的索引,他只是一个索引而不是多个,
其次,单列索引是一种特殊的联合索引
联合索引的创立要遵循最左前置原则(最常用列>离散度>占用空间小)
-
什么是覆盖索引
通过索引项信息可直接返回所需要查询的索引列,该索引被称之为覆盖索引,说白了就是不需要做回表操作,可以从二级索引中直接取到所需数据。
-
什么是ICP机制
索引下推,简单点来说就是,在sql执行过程中,面对where多条件过滤时,通过一个索引,完成数据搜索和过滤条件其,特点能减少io操作。
-
在InnoDB表中不可能没有主键对还是不对原因是什么?
- 首先这句话是对的,但是情况有三种:
- 就是在你手动显式指定这一个字段为主键时候,会以这一个字段为聚集索引。
- 在没有显式指定主键时候有两种情况:
- 他会寻找第一个UK(unique key)作为主键索引组织索引编排。
- 如果既没有指定主键也没有UK的情况下,此时会以rowId(在InnoDB表中每一个记录都会有一个隐藏(6byte)的rowId)为聚集索引。
- 首先这句话是对的,但是情况有三种:
-
什么是回表操作
在InnoDB 中基于辅助索引查询的内容,从辅助索引中无法直接获取,需要基于主键索引的二次扫描的操作叫做回表操作。
-
为什么在InnoDB 中辅助索引叶子结点数据区记录的是主键索引的值而不是像MyISAM中去记录磁盘地址。
- 这个原因其实很简单,因为主键索引的数据结构是会经常发生变化的,如果在辅助索引数据区记录磁盘地址,那么假设我们有10个辅助索引,当我们主键索引结构发生变化后,还要一个个去通知辅助索引,且主键索引结构是经常发生变化的,增删都有可能影响他的
数据结构。
- 这个原因其实很简单,因为主键索引的数据结构是会经常发生变化的,如果在辅助索引数据区记录磁盘地址,那么假设我们有10个辅助索引,当我们主键索引结构发生变化后,还要一个个去通知辅助索引,且主键索引结构是经常发生变化的,增删都有可能影响他的
版权归属: 泪梦红尘
本文链接: https://www.bss2.com/archives/mysql-opt-index
来源:https://www.cnblogs.com/lmhcblog/p/16009320.html
本站部分图文来源于网络,如有侵权请联系删除。