 百木园
百木园数据量 (Data Stream) 是在 Elasticsearch 7.9 版推出的一项功能,它可以很方便的处理时间序列数据。
1、简介
1.1、什么是 Time Series Data
TSD 始终与时间戳关联,该时间戳标识创建事件时该数据的时间点事件。 例如,它可以是传感器数据(温度测量)或安全设备日志,这些数据有什么共同点? 随着时间的流逝,它的重要性趋于松散,与过去事件相关的旧文档不如与新事件相关的文档重要。 你可能不再对上个月的传感器相关数据感兴趣,尤其是非常精确的数据。
因此,在 ES 中,在弹性搜索中处理此数据的最佳选择是使用基于时间的索引。
time Series Data 具有以下的特点:
它可以是来自一些服务器的日志或者是一些设施的指标,社交媒体流,基于时间的事件
由时间戳 + 数据组成
通常搜索最近事件
旧文件变得不太重要
基于时间的索引是最佳选择
每天,每周,每月,每年...创建一个新索引
1.2、处理 Time Series Data 的挑战
当我们处理 TSD 数据时,会临很多的挑战:
从数据的有效性来说,数据会随着时间的流失而失去它的重要性,并且对旧的数据的查询率会变低。我们需要使用新的存储模式来对数据进行保存,比如,删除时间很久的数据,或者对稍微久一点的数据保存于一些价格较为便宜的存储设备上以节省成本,并同时设置该索引为只读。我们甚至对一些历史更久的索引进行 close/frozen 操作从而更加进一步节省运行资源。
另外从控制索引的大小来说,我们很难预测索引的大小。当我们开始收集数据时,我们只有很少量的数据:

随着数据量的增加:
最终,我们可能看到更多的数据被收集上来:

这对于我们计划集群的大小和分片的个数带来挑战。我们需要按照我们需求针对每天,或者每周来分别创建索引来满足自己业务的需求。我们甚至删除一些不需要的时间久一些的索引数据。这个就是我们通常所说的 ILM (索引生命周期管理)。
避免过大的单个索引,而是把一个大的索引分为多个小的索引来进行存储:
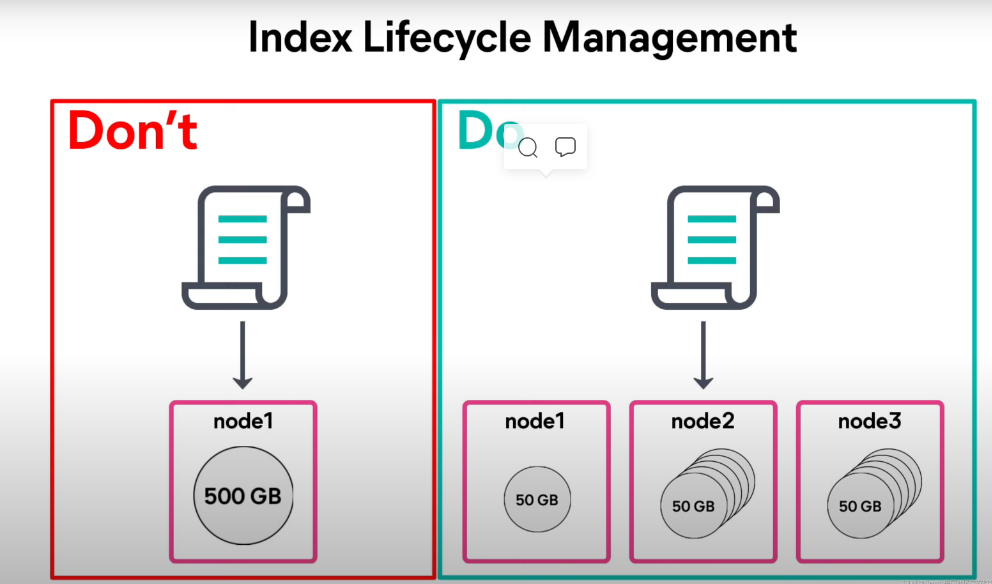
不要让一个索引的大小过大,但是也不要让一个索引的大小过小:

1.3、Data Stream
Data stream (数据流)是 Elastic Stack 7.9 的一个新的功能。Data stream 使你可以跨多个索引存储只追加数据的时间序列数据,同时为请求提供唯一的一个命名资源。 data stream 非常适合日志,事件,指标以及其他持续生成的数据。
你可以将索引和搜索请求直接提交到 data stream。 stream 自动将请求路由到存储流数据的后备索引。 你可以使用索引生命周期管理(ILM)来自动管理这些后备索引。 例如,你可以使用 ILM 自动将较旧的后备索引移动到较便宜的硬件上,并删除不需要的索引。 随着数据的增长,ILM 可以帮助你降低成本和开销。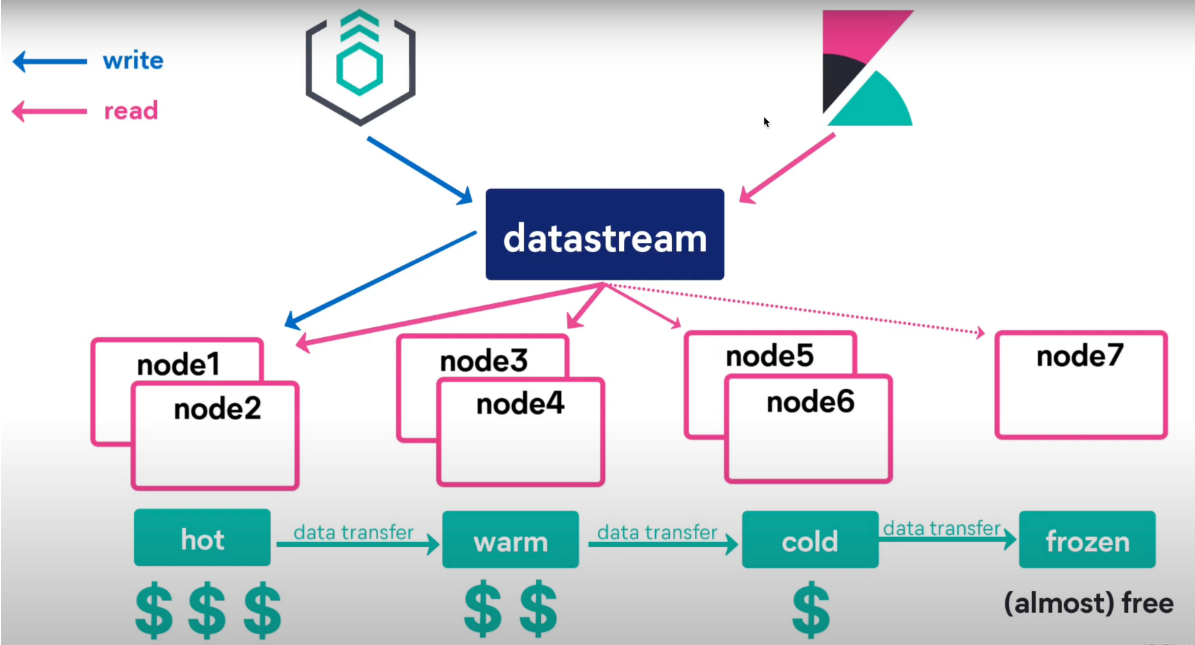

请注意,并非所有数据集都以相同的方式老化。 数据层不适用于产品搜索或全文搜索用例,例如,随着文档的老化,查询的频率会降低。 通常,数据生命周期概念适用于时间序列数据,但某些用例可能会有所不同。随着索引的老化而移动索引的过程由称为索引生命周期管理的功能管理。
1.3.1、后备索引(Backing indices)
数据流由一个或多个 hidden 的自动生成的后备索引(Backing indices)组成。
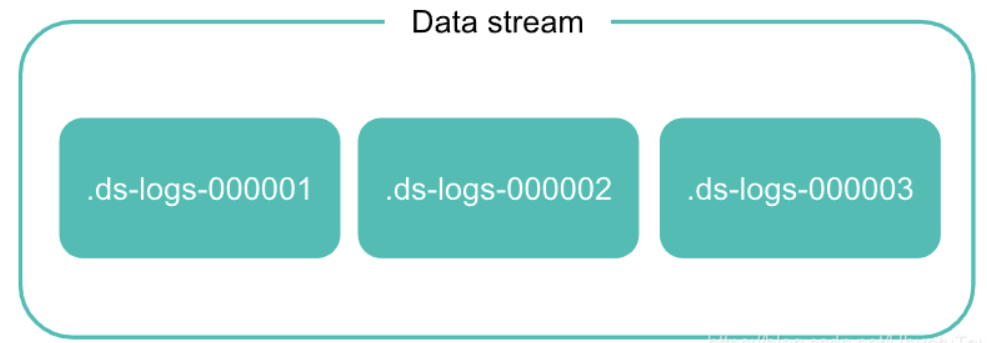
每个数据流都需要一个匹配的索引模板。 该模板包含用于配置流的后备索引的映射和设置。
索引到数据流的每个文档都必须包含一个 @timestamp 字段,该字段映射为 date 或 date_nanos 字段类型。 如果索引模板未为 @timestamp 字段指定映射,则 Elasticsearch 将@timestamp 映射为具有默认选项的日期字段。
同一个索引模板可用于多个数据流。 你不能删除数据流正在使用的索引模板。
1.3.2、读请求
当你向数据流提交读取请求时,该流会将请求路由到其所有后备索引。
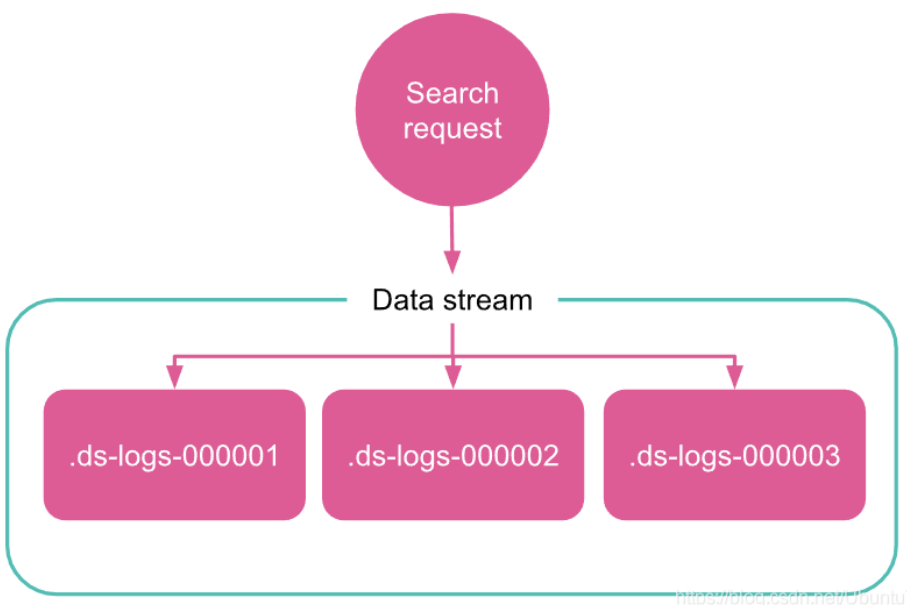
1.3.4、写索引
最新创建的后备索引是数据流的写索引。 流仅将新文档添加到该索引。

你不能将新文档添加到其他支持索引,即使直接将请求发送到索引也是如此。
你也不能对可能阻碍写索引执行如下的操作:
- Clone
- Close
- Delete
- Freeze
- Shrink
- Split
1.3.5、Rollover
创建数据流时,Elasticsearch 会自动为该流创建一个后备索引。 该索引还充当流的第一个写入索引。 rollover 会创建一个新的后备索引,该后备索引将成为流的新写入索引。
我们建议当写入索引达到指定的使用期限或大小时,使用 ILM 自动翻转数据流。 如果需要,你还可以手动将数据 rollover。
1.3.6、Data Stream 生成
每个数据流都跟踪其生成:一个六位数,零填充的整数,用作该流的 rollover 的累积计数,从 000001 开始。
创建支持索引时,将使用以下约定来命名该索引:
.ds-<data-stream>-<date>-<generation>
具有更高 generation 的后备索引包含更新的数据。 例如,web-server-logs 数据流有一个 generation 为 34。该流的最新后备索引名为 .ds-web-server-logs-000034。
某些操作(例如 shrink 或 restore)可以更改后备索引的名称。 这些名称更改不会从其数据流中删除后备索引。
1.3.7、只追加
数据流专为很少更新现有数据(如果有的话)的用例而设计。 你不能将对现有文档的更新或删除请求直接发送到数据流。 而是使用 update by query 和 delete by query 删除。
如果需要,你可以通过直接向文档的后备索引提交请求来更新或删除文档。
提示:如果您经常更新或删除现有文档,请使用索引别名和索引模板,而不要使用数据流。 你仍然可以使用 ILM 管理别名的索引。
2、Data Stream 演示
2.1、启动 Elasticsearch 集群
启动三个节点(10.49.196.10、10.49.196.11、10.49.196.12)的集群,其中两个为 hot 节点(存放 hot 阶段的数据),一个为 warm 节点(存放 warm 阶段的数据)。
在 10.49.196.10、10.49.196.11 上运行:
bin/elasticsearch -d -E node.attr.data=hot
在 10.49.196.12 上运行:
bin/elasticsearch -d -E node.attr.data=warm
查看 node 属性信息:
GET _cat/nodeattrs?v

2.2、创建 Index Lifecycle Policy
PUT _ilm/policy/demo-policy { \"policy\": { \"phases\": { \"hot\": { \"actions\": { \"rollover\": { \"max_size\": \"10mb\", \"max_age\": \"1d\", \"max_docs\": 5 } } }, \"warm\": { \"min_age\": \"5m\", \"actions\": { \"shrink\": { \"number_of_shards\": 1 }, \"allocate\": { \"number_of_replicas\": 0, \"require\": { \"data\": \"warm\" } } } }, \"delete\": { \"min_age\": \"10m\", \"actions\": { \"delete\": {} } } } } }
这里定义的 policy 意思为:
热阶段
索引创建 1 天后、索引大小达到 10MB 或 索引文档数达到 5(符合任何一个即可),该索引将滚动更新,系统将创建一个新索引。该新索引将重新启动策略,而当前的索引(刚刚滚动更新的索引)将在滚动更新后等待 5 分钟进入温阶段。
温阶段
索引进入温阶段后,ILM 会将索引收缩到 1 个分片 0 个副本,通过分配操作将索引移动到温节点。完成该操作后,索引将再等待 5 分钟 (时间都是从滚动跟新算起,10 - 5 = 5)后进入删除阶段。
删除阶段
删除阶段具有用于删除索引的删除操作。在删除阶段,您将始终需要有一个 min_age 条件,以允许索引在给定时段内待在热、温或冷阶段。
2.3、创建 Index template
PUT _index_template/demo-template { \"index_patterns\": [\"demo-*\"], \"data_stream\": {}, \"template\": { \"settings\": { \"index.lifecycle.name\": \"demo-policy\", \"index.lifecycle.rollover_alias\": \"demo-alias\", \"index.routing.allocation.require.data\": \"hot\", \"index\": { \"number_of_shards\": 2, \"number_of_replicas\": 1 } }, \"mappings\": { \"properties\": { \"@timestamp\": { \"type\": \"date\", \"format\": \"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis\" }, \"age\": { \"type\": \"integer\" }, \"name\": { \"type\": \"keyword\" }, \"poems\": { \"type\": \"text\", \"analyzer\": \"ik_max_word\", \"search_analyzer\": \"ik_smart\" }, \"about\": { \"type\": \"text\", \"analyzer\": \"ik_max_word\", \"search_analyzer\": \"ik_max_word\" }, \"success\": { \"type\": \"text\", \"analyzer\": \"ik_max_word\", \"search_analyzer\": \"ik_max_word\" } } } } }
上面创建了一个名字为 demo-template 的 index template。data_stream 为一个空的 object;新建的索引在 hot 节点,分片为 2,副本为 1。
2.4、创建 Data Stream
PUT _data_stream/demo-ds
由于在上面已经创建了以 demo-* 为 index_pattern 的 index template,所以创建成功。
2.5、查看 Data Stream
GET _data_stream/demo-ds
{ \"data_streams\": [ { \"name\": \"demo-ds\", \"timestamp_field\": { \"name\": \"@timestamp\" }, \"indices\": [ { \"index_name\": \".ds-demo-ds-2022.07.12-000001\", \"index_uuid\": \"6YhZxvQLRpuiE14rbeUl4g\" } ], \"generation\": 1, \"status\": \"GREEN\", \"template\": \"demo-template\", \"ilm_policy\": \"demo-policy\", \"hidden\": false, \"system\": false, \"allow_custom_routing\": false, \"replicated\": false } ] }
2.6、发送数据到 Data Stream
POST /demo-ds/_bulk { \"create\":{\"_id\":\"1\"} } {\"@timestamp\":\"2022-07-07 10:51:21\",\"age\": 30,\"name\": \"李白1\",\"poems\": \"静夜思\",\"about\": \"字太白\",\"success\": \"创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度\"} { \"create\":{\"_id\":\"2\"} } {\"@timestamp\":\"2022-07-07 10:51:22\",\"age\": 30,\"name\": \"李白2\",\"poems\": \"静夜思\",\"about\": \"字太白\",\"success\": \"创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度\"} { \"create\":{\"_id\":\"3\"} } {\"@timestamp\":\"2022-07-07 10:51:23\",\"age\": 30,\"name\": \"李白3\",\"poems\": \"静夜思\",\"about\": \"字太白\",\"success\": \"创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度\"} { \"create\":{\"_id\":\"4\"} } {\"@timestamp\":\"2022-07-07 10:51:24\",\"age\": 30,\"name\": \"李白4\",\"poems\": \"静夜思\",\"about\": \"字太白\",\"success\": \"创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度\"} { \"create\":{\"_id\":\"5\"} } {\"@timestamp\":\"2022-07-07 10:51:25\",\"age\": 30,\"name\": \"李白5\",\"poems\": \"静夜思\",\"about\": \"字太白\",\"success\": \"创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度\"}
2.7、rollover
已经有超过 5 个文档了,将会 rollover;rollover 扫描间隔默认时 10 分钟,可以通过修改 indices.lifecycle.poll_interval 参数来改变默认的间隔时间。

PUT _cluster/settings
{
\"transient\": {
\"indices.lifecycle.poll_interval\": \"30s\"
}
}
rollover 后会生成新的索引:

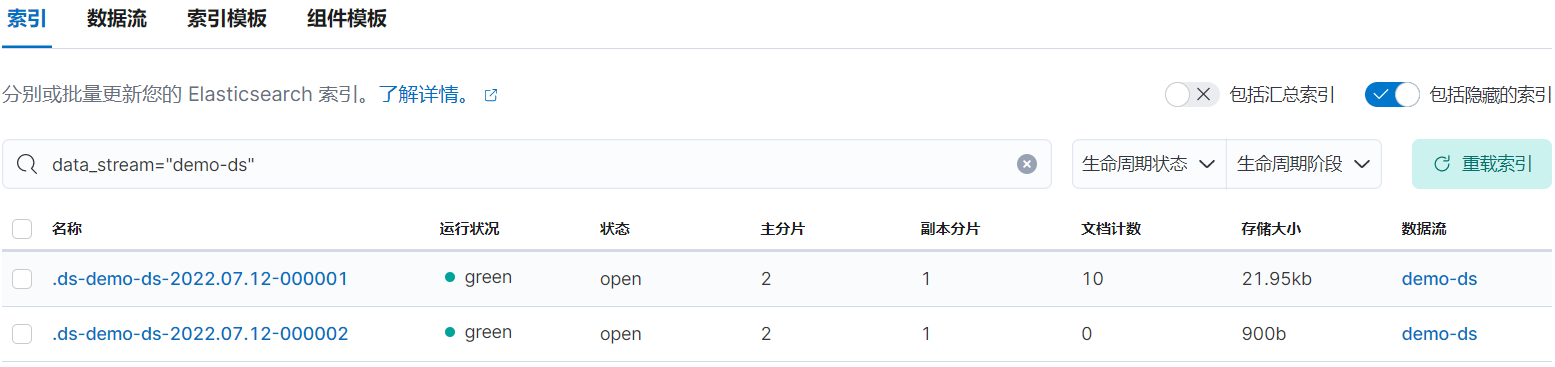
2.8、进入 warm 阶段
rollover 后,索引 .ds-demo-ds-2022.07.12-000001 等待 5 分钟左右后将会进入 warm 阶段。
rollover 后的情况:
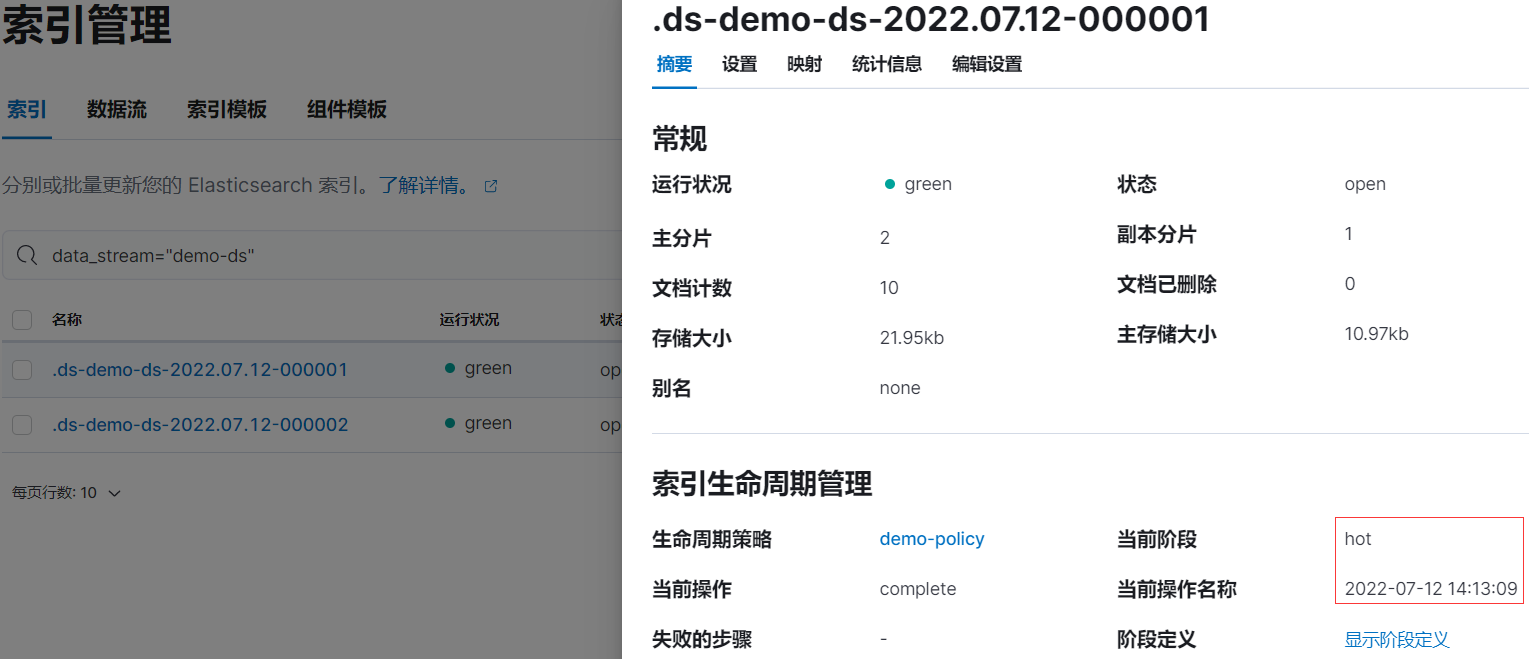
rollover 后等待 5 分钟左右后,索引 .ds-demo-ds-2022.07.12-000001 已被重命名为 shrink-fshz-.ds-demo-ds-2022.07.12-000001:

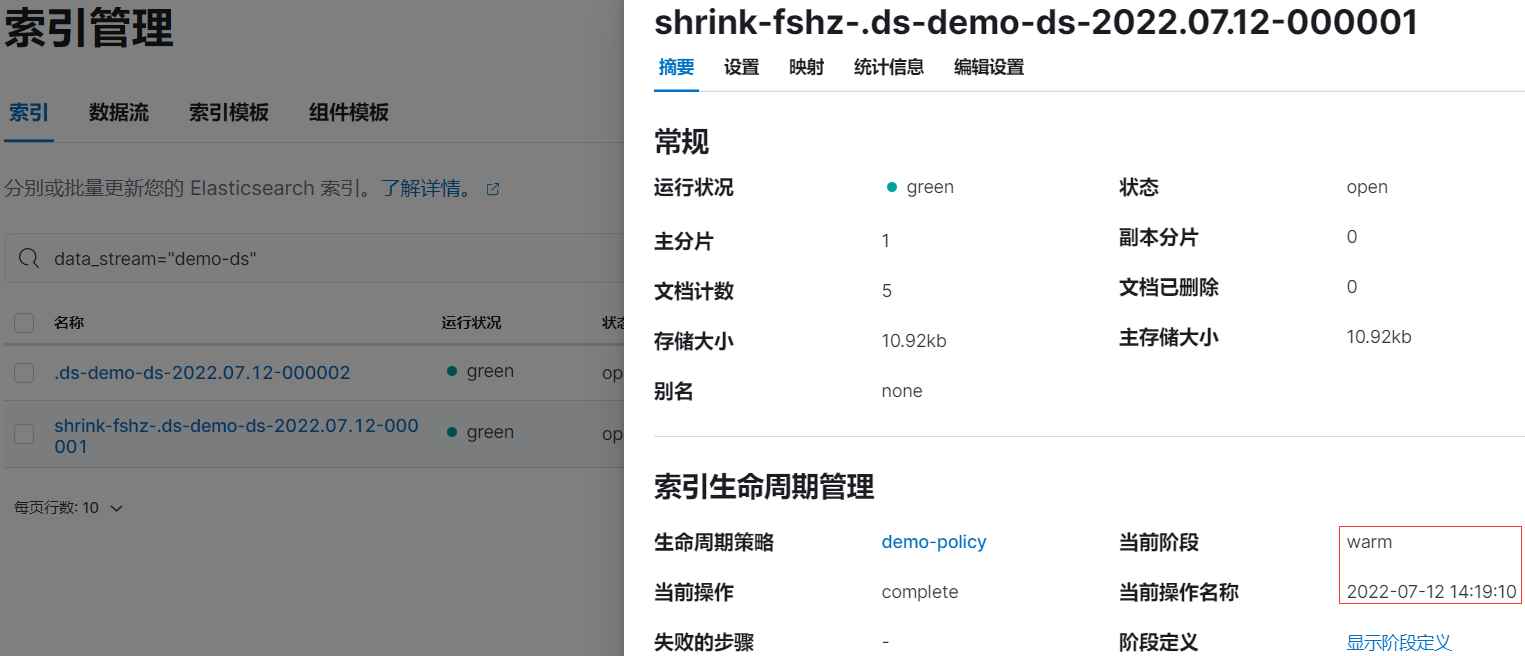
2.7、进入 delete 阶段
在 warm 阶段再等待 5 分钟(10m - 5m)左右后, shrink-fshz-.ds-demo-ds-2022.07.12-000001 进入 delete 阶段,索引将被删除。
参考:https://blog.csdn.net/UbuntuTouch/article/details/110528838
来源:https://www.cnblogs.com/wuyongyin/p/16468864.html
本站部分图文来源于网络,如有侵权请联系删除。