 百木园
百木园前言
嗨喽~大家好呀,这里是魔王呐 !
在这平凡的一日,我决定~
干一件平凡的事~让我们开动起我们的小手

来做一个小小的颜值检测叭~

开发环境:
-
Python 3.8
-
Pycharm 2021.2
模块使用:
-
requests >>> pip install requests
-
tqdm >>> pip install tqdm 简单实现进度条效果
-
os
-
base64
本次分为两部分:
第一部分 采集主播照片数据
第二部分 实现颜值检测 进行排名
基本流程思路:
一. 数据来源分析:
1、明确需求, 采集那个网站上面什么数据
2、通过开发者工具进行抓包分析, 分析我们想要照片数据来源
- F12 或者 鼠标右键点击检查 选择 network 打开
二. 代码实现步骤:
1、发送请求, 模拟浏览器对于url地址发送请求
2、获取数据, 获取服务器返回响应数据 ---> 开发者工具当中 response
3、解析数据, 提取我们想要数据内容 图片url 以及 主播名字
4、保存数据, 照片图片保存本地
代码
导入模块
# 导入数据请求模块 --> 第三方模块 需要 在cmd里面 pip install requests import requests # 导入格式化输出模块 ---> 内置模块 不需要安装 from pprint import pprint import base64 import os from tqdm import tqdm
采集图片
\"\"\" 1. 发送请求, 模拟浏览器对于url地址发送请求 - 当你请求url地址, 是长链接的时候, 我们是可以分段写 https://www..com/cache.php? m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&callback=getLiveListJsonpCallback&page=2 - 如何实现批量替换 选中替换的内容, 输入 ctrl + r 输入正则命令 (.*?): (.*) \'$1\': \'$2\', - 模拟伪装浏览器 ---> 请求头参数 可以直接在开发者工具里面进行复制 - 加文章下方老师VX 1. 领取python常用单词词汇汇总 2. 领取一个插件 翻译插件 - 等号左边都是属于自定义变量, 你自己定义变量 - 不能以数字开头 - 不推荐使用关键字命名 - 最好是见明知意 \"\"\" # 确定请求url地址 url = \'https://www..com/cache.php\' # 请求参数 ---> 字典数据类型, 构建完整键值对形式 data = { \'m\': \'LiveList\', \'do\': \'getLiveListByPage\', \'gameId\': \'2168\', \'tagAll\': \'0\', # \'callback\': \'getLiveListJsonpCallback\', \'page\': \'2\', } # 模拟浏览器 ---> 请求头 headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36\' } # 发送请求 ---> <Response [200]> 响应对象 200状态码表示请求成功 response = requests.get(url=url, params=data, headers=headers) \"\"\" 2. 获取数据, 获取服务器返回响应数据 response.text 获取文本数据 ---> 字符串数据类型 为了更加方便提取数据, 可以获取json字典数据 如果你想要获取json数据, 但是请求参数里面有 callback 可以删除 callback response.json() 获取json数据 ---> 字典数据类型 3. 解析数据, 提取我们想要数据内容 - 当你的数据是字典数据, 可以使用pprint模块 进行格式化输出打印, 效果更好 如果你print打印字典数据, 呈现一行 如果你pprint打印字典数据, 呈现多行, 展开的效果 更加方便取值 - 字典取值 ---> 键值对取值, 根据冒号左边的内容[键], 提取冒号右边的内容[值] \"\"\" # for循环遍历 一个一个提取列表里面元素 for index in response.json()[\'data\'][\'datas\']: # 获取名字 name = index[\'nick\'] # 获取图片url img_url = index[\'screenshot\'].split(\'?\')[0] \"\"\" 4. 保存数据 ---> 对于图片url地址发送请求, 获取数据 - FileNotFoundError: [Errno 2] No such file or directory: \'img知恩丶小晴天.jpg\' 没有文件夹 ---> 1. 手动创建 2. 自动创建 \"\"\" # 获取图片二进制数据 img_content = requests.get(url=img_url, headers=headers).content # 保存数据内容 with open(\'img\' + name + \'.jpg\', mode=\'wb\') as f: # 写入数据 f.write(img_content) print(name, img_url)
颜值检测
def get_beauty(img_base64): # client_id 为官网获取的AK, client_secret 为官网获取的SK host = \'https://aip.baidubce.com/oauth/2.0/token\' # 【官网获取的AK】 和 【官网获取的SK】 在百度云创建好应用之后, 就有的 params = { \'grant_type\': \'client_credentials\', \'client_id\': \'quXbPEiGM2bKK77NV2vwsd53\', \'client_secret\': \'hRa4ox5WYLgU1cCm5bP2kU0GWnOqos76\', } response = requests.get(url=host, params=params) # 获取 access_token 值 access_token = response.json()[\'access_token\'] request_url = f\"https://aip.baidubce.com/rest/2.0/face/v3/detect?access_token={access_token}\" data = { # 传入图片 base64内容 \"image\": img_base64, \"image_type\": \"BASE64\", \"face_field\": \"beauty\" } headers = {\'content-type\': \'application/json\'} json_data = requests.post(request_url, data=data, headers=headers).json() try: beauty = json_data[\'result\'][\'face_list\'][0][\'beauty\'] return beauty except: return \'识别失败\' # img_file = open(\'img\\\\悦欣-玻璃.jpg\', mode=\'rb\') # img_base64 = base64.b64encode(img_file.read()) # beauty = get_beauty(img_base64) # print(f\'颜值评分是:\', beauty) lis = [] files = os.listdir(\'img\\\\\') print(\'正在颜值检测中, 请稍后.......\') for file in tqdm(files[:10]): img_file = \'img\\\\\' + file img = open(img_file, mode=\'rb\') img_base64 = base64.b64encode(img.read()) beauty = get_beauty(img_base64) name = file.split(\'.\')[0] if beauty != \'识别失败\': dit = { \'主播\': name, \'颜值\': beauty, } lis.append(dit) lis.sort(key=lambda x:x[\'颜值\'], reverse=True) num = 1 for li in lis: print(f\'颜值排名第{num}的是: {li[\"主播\"]}, 颜值评分是{li[\"颜值\"]}\') num += 1
我弄的前十的排名数据,你们的可以自己修改哦~
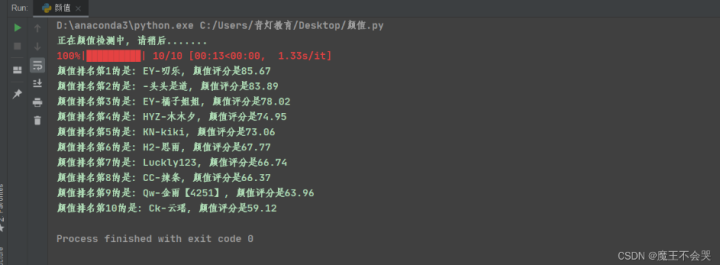
让我们来看一看前十小姐姐的颜值吧~
系统检测颜值前十




咋到后面成这样了!!!! 怀疑人生。。。。
终究是我跟不上时代了~

我不信这个邪,我要继续,啊啊啊啊啊


终于有一个小姐姐不错的了,呜呜呜,太难了~


我喜欢的小姐姐
前面出现过的我这里不会出现哦~(即使我认为好看,嘿嘿嘿)







还有一些我就不发出来了~你们自己去看叭
尾语
人的一生就像在攀登高峰,勤奋是你踏实稳健的双脚,
信念是你指引前行的向导,勇敢是你孜孜追寻的恒心。
开心日到了,愿你站稳双脚,确定方向,向着你的理想巅峰勇敢前行,
不用怕,未来就在你的脚下。
—— 心灵鸡汤
本文章到这里就结束啦~希望这篇文章你喜欢,欢迎大家评论区讨论哦😝
对啦!!记得三连哦~ 💕 另外,欢迎大家阅读我往期的文章呀~

来源:https://www.cnblogs.com/Qqun261823976/p/16588783.html
本站部分图文来源于网络,如有侵权请联系删除。