 百木园
百木园一、MMDB简介
MMDB(MaxMind Database) 是MaxMind推出的一个数据存储和检索的数据库格式,用于旗下针对IP检索和存储的Geo产品。
IP格式由二进制比特数组组成,很容易想到每个比特对应二叉树一个节点,可以说二叉树检索特别适合于IP格式。
MMDB的构造过程正是把一颗数据位于叶子节点的二叉树进行序列化。
序列化后是字节数组,和其他检索格式都是反序列化为结构化的内存形式不同,MMDB检索时把整个mmdb文件加载为一个字节数组即可。
检索过程在字节数组上操作,由于每个节点大小固定,通过简单内存计算即可完成节点定位,不需要额外生成其他中间结构,可以说非常简洁和高效。
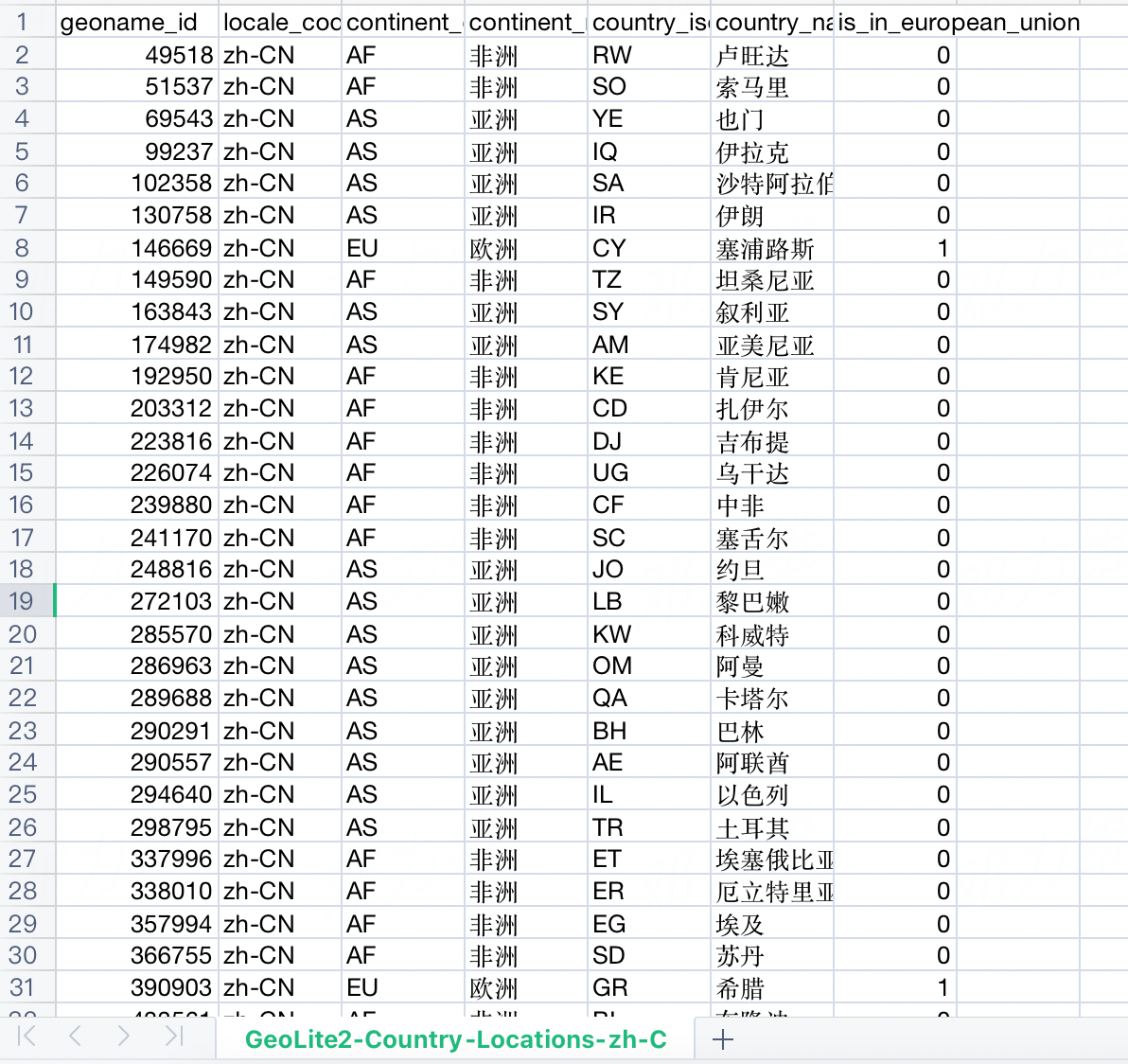
Maxmind的GeoIP产品用于检索以下网段的geo信息,其中最左一列是网段,第二列是geoname_id。根据网段找到geoname_id,再根据geoname_id找到下图的数据。

二、构造过程
构造过程是生成一颗二叉检索树的过程。
假设只存储一个网段“110”的数据,则可以得到二叉树为:
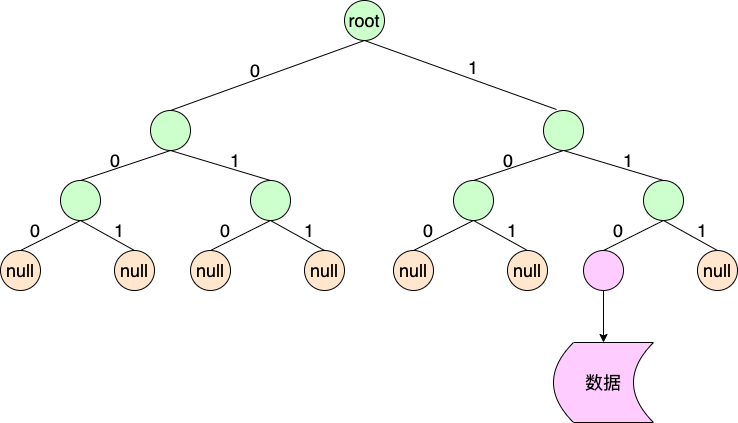
只有叶子节点会存储指向数据的引用。
三、MMDB总体格式
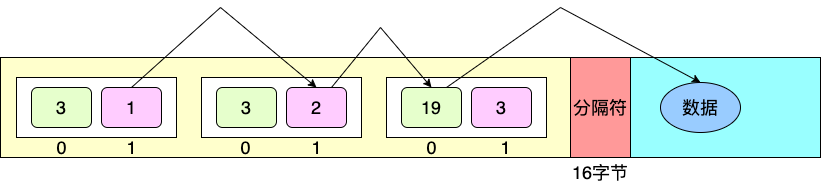
二叉树经过序列化会得到一个字节数组,数据格式如下图:

节点序列存储二叉树的节点,数据信息则存储在数据序列中,数据使用MMDB序列化格式(类似json)。
第三部分为元数据,存储版本号、生成时间、数据库类型、IP版本、语言、节点个数、节点记录规格等。检索过程需要使用这些进行内存寻址来完成节点位置的计算。
第一个分隔符为16字节的\"NULL\",即16个0。
第二个分隔符为\"\\xAB\\xCD\\xEFMaxMind.com\"。
四、节点序列说明
节点序列等于一个节点数组,每个节点由两个记录组成,分别对应二叉树的左孩子和右孩子。
在IP检索中,比特0对应第一个记录,比特1对应第二个记录。

如上图所示,包含3个节点,第一个节点的两个记录为3和1,第二个节点为3和2,第三个节点为19和3。
当记录数等于节点数3时,表示没找到数据。当记录数大于节点数3时,则为数据节点的记录值。
数据偏移量的计算公式:数据偏移量 = 记录值 - 节点个数 - 16(分隔符的长度)。
第三个节点记录19表示数据偏移量为0,19-3(节点数)-16。
五、检索算法
在一个总节点数为3的mmdb数据库上,网段“110”的检索过程
六、数据段说明
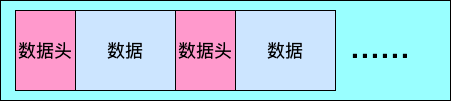
数据序列由数据头和数据组成,数据头记录数据类型和数据大小,目前MMDB支持多种数据类型,包括int, string, map, bytes等。
程序读到字节数组后通过反序列化得到实际数据。
七、实验例子
1、构造一个网段为“192.2.10.0/3”,对应二进制网络“110”的节点,数据为{\"iso\":156,\"country_name\":\"China\"},生成的节点序列为:

注意:上图每三个字节存储一个记录,中间16个0是分隔符。格式化打印后得到下图,符号“-”表示空节点:
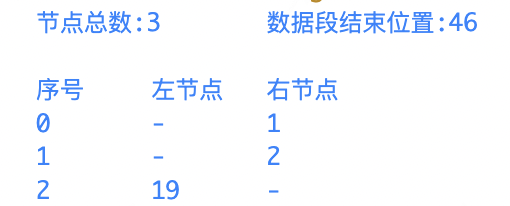
可以看到“110”网段根据二叉树检索算法得到数据段的偏移量19,则数据段偏移量为19-3(节点数)-16=0。
2、再加入一个网段为“64.2.10.0/3”,对应二进制网络“010”的节点,数据为{\"iso\":826,\"country_name\":\"England\"},生成的节点序列为:

格式化打印后得到下图,符号“-”表示空节点:

可以看到“010”网段根据二叉树检索算法得到数据段的偏移量21,则数据段偏移量为21-5(节点数)-16=0。而此时“110”网段的数据段的偏移量变成了50,则数据段偏移量为50-5(节点数)-16=29。
八、总结
1、生成过程使用二叉树。
2、存储和检索都是序列化字节数组格式。
3、MMDB是内存数据库 。
参考链接
MaxMind DB File Format Specification
Enriching MMDB files with your own data using go
Building your own MMDB database for fun and profit
来源:https://www.cnblogs.com/leavygood/p/17109967.html
本站部分图文来源于网络,如有侵权请联系删除。