 百木园
百木园一、安装Spark
- 检查基础环境hadoop,jdk
- 下载spark
- 解压,文件夹重命名、权限
- 配置文件
- 环境变量
- 试运行Python代码
1.jdk、hadoop环境
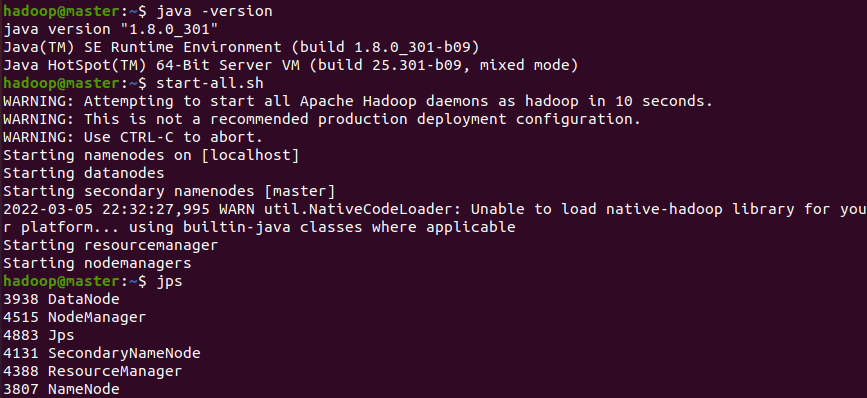
2.spark环境

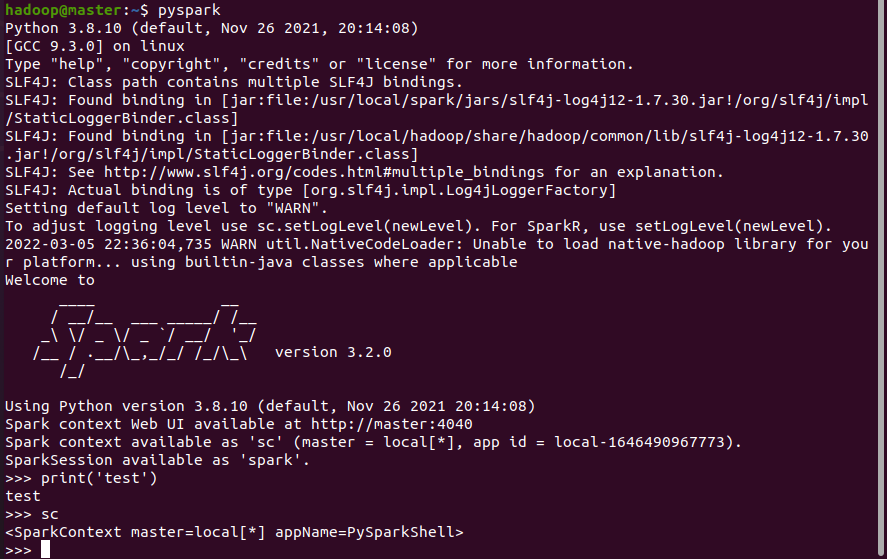
二、Python编程练习:英文文本的词频统计
- 准备文本文件
- 读文件
- 预处理:大小写,标点符号,停用词
- 分词
- 统计每个单词出现的次数
- 按词频大小排序
- 结果写文件
1.准备文本文件
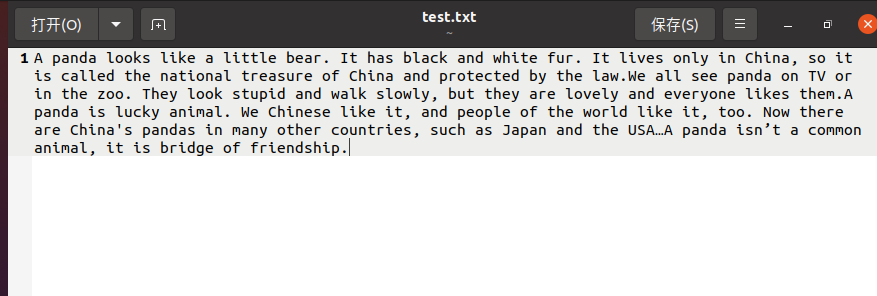
2.读文本
text = open(\'test.txt\',\'r\',encoding=\'utf-8\').read() len(text)
3.预处理:大小写,标点符号,停用词、分词、统计词频
#全部字符变成小写字符
text = text.lower()
#读取停用词,创建停用词表
stwlist = [line.strip() for line in open (\'test1.txt\',encoding=\'utf-8\').readlines()]
#先进行分词
words = jieba.cut(text,cut_all = False,HMM = True)
#cut_all:是否采用全模式
#HMM:是否采用HMM模型
#去停用词,统计词频
word_ = {}
for word in words:
if word.strip() not in stwlist:
if len(word) > 1:
if word != \'\\t\':
if word != \'\\r\\n\':
#计算词频
if word in word_:
word_[word] += 1
else:
word_[word] = 1
#将词汇和词频以元组的形式保存
word_freq = []
for word,freq in word_.items():
word_freq.append((word,freq))
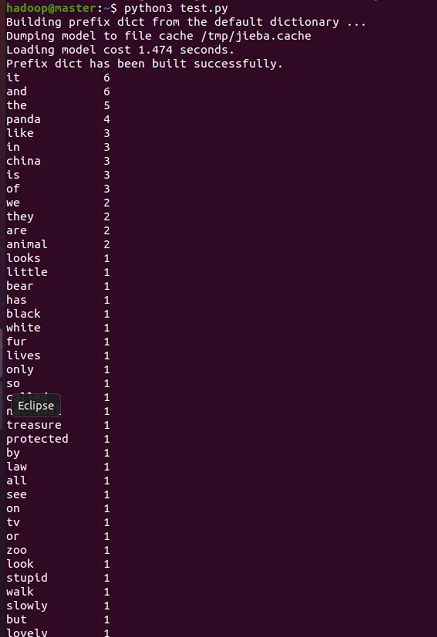
4.词频排序
#进行降序排列 word_freq.sort(key = lambda x:x[1],reverse = True)
5.写入文件
txt = open(\"test11.txt\", \"w\", encoding=\'UTF-8\') txt.write(str(word_freq))

来源:https://www.cnblogs.com/wjp11/p/15973002.html
本站部分图文来源于网络,如有侵权请联系删除。