 百木园
百木园我是3y,一年CRUD经验用十年的markdown程序员👨🏻💻常年被誉为优质八股文选手
前两天我不是发了一篇数据链路追踪的文章嘛,在末尾也遗留了TODO:运行应用的服务器一般是集群,日志数据会记录到不同的机器上,排查和定位问题只能登录各个服务器查看。
今天来聊聊这个话题。
00、为什么需要分布式日志组件?
在文章正式开始之前,我分享下我以前负责过的一个系统,它的架构如下:
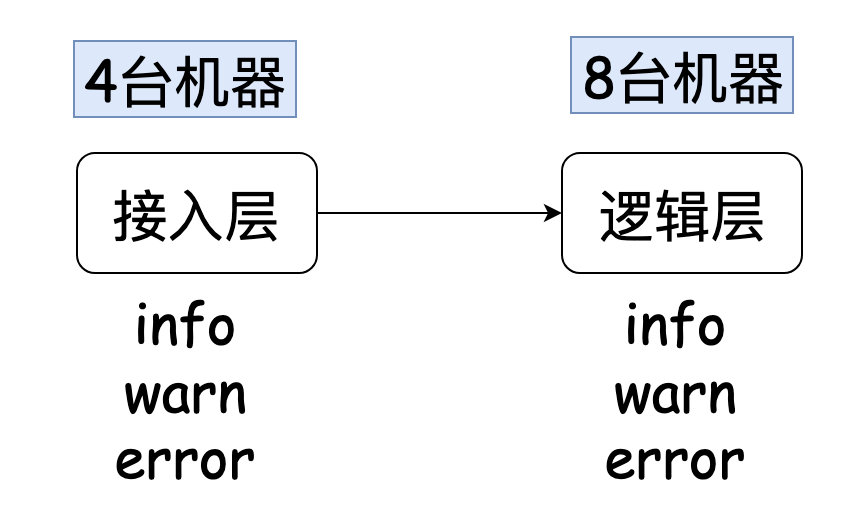
每次当我查问题的时候,我可能能把问题初步定位在逻辑层,但为了能给业务方交代,我需要给证据业务方看(日志信息就是铁证)。
一个请求肯定是被这8台机器内的某一台处理,但具体是哪一台,我不知道。所以,我需要上每台机器上grep一把日志,然后才能找出对应的日志证明我的分析。

有的时候,可能接入层也需要一起参与进去,就排查一个问题,人都傻了了(翻看日志的时间占用了太久了)。
后来啊,看了同事的骚操作(在item2 编写脚本:快速登录堡垒机(免去输入账号和密码信息),根据应用服务器数量来切割窗口并且切换到对应的日志目录)。说白了就是一键登录多台应用服务器。嗯,这查日志的速度比起以前又快了好多。

再后来,公司运维侧又主力推在Web页面上登录应用服务器(自动登录堡垒机),这能省去编写脚本(支持批量操作)。但从当时的体验上,没有用item2访问得流畅(总感觉卡卡的)。
不过还有问题,因为我们在很多时候是不知道在info/warn/error哪个文件下。很多时候只能一个一个文件去查,虽然说可以直接通配符一把查,如果日志过大,带来停顿时间也挺烦的。
系统一旦被问到业务问题,查日志的频率实在是太高了。于是我在某个Q规划的时候是想自己把日志信息写入到搜索引擎,顺便学习下搜索引擎的知识。然后这个规划被组内的某个大佬看到了,在底下评论:要不来试试Graylog?
原来组内本身就在维护了一个日志框架,只是我不知道...于是我接入了Graylog日志,工作效率杠杠提高了,凭借这个事情吹了一个Q。

自从接入了之后,我就没登录过应用服务器了,有次差点连grep都不会写了。

01、轻量级ELK(Graylog)
说起ELK,即便没用过肯定也听说过这玩意了,在后端是真的流行。这次austin接入一个比较轻量级的ELK框架:Graylog
这个框架我感觉蛮好用的,作为使用方接入起来异常简单(我估摸运维应该也挺简单的,很多用Graylog是直接发UDP到Server,不用在机器上装agent收集日志)
一图胜十言:
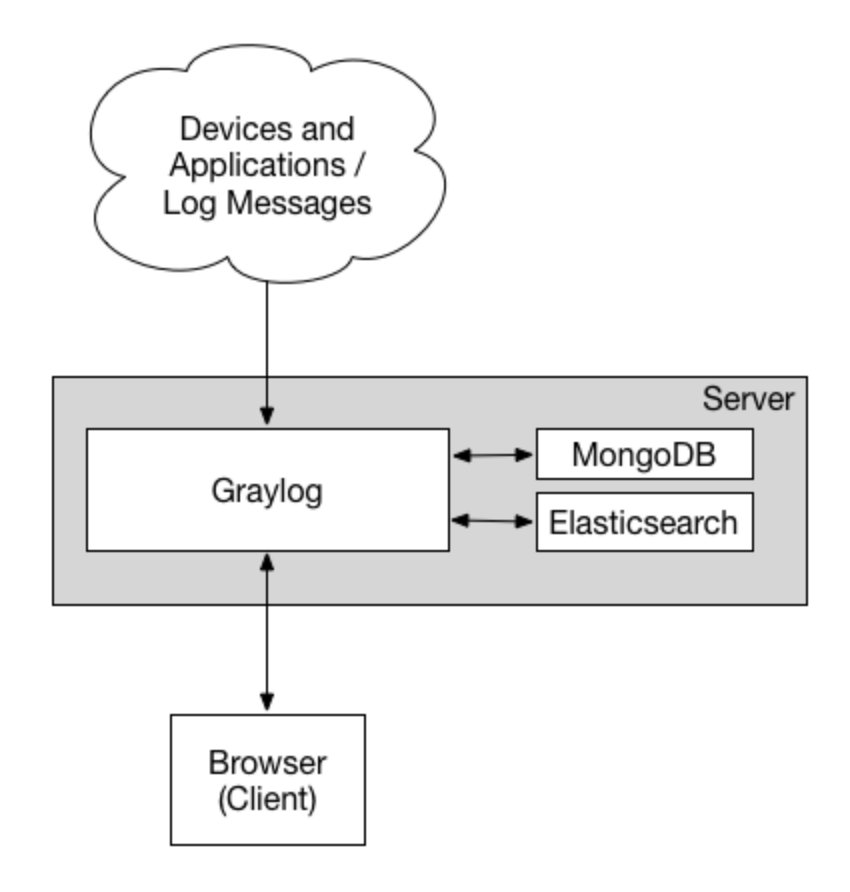
官方文档:https://docs.graylog.org/docs
据我了解,有相当多的企业使用它来查看日志和业务监控告警,这篇文章我就直接让你们体验体验吧。
02、部署Graylog
老样子,直接上docker-compose,如果一直跟着我的步伐,应该对着不陌生了。docker-compose.yml的内容其实我也是抄官网的,这里还是贴下吧(就不用你们翻了)
version: \'3\'
services:
mongo:
image: mongo:4.2
networks:
- graylog
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2
environment:
- http.host=0.0.0.0
- transport.host=localhost
- network.host=0.0.0.0
- \"ES_JAVA_OPTS=-Dlog4j2.formatMsgNoLookups=true -Xms512m -Xmx512m\"
ulimits:
memlock:
soft: -1
hard: -1
deploy:
resources:
limits:
memory: 1g
networks:
- graylog
graylog:
image: graylog/graylog:4.2
environment:
- GRAYLOG_PASSWORD_SECRET=somepasswordpepper
- GRAYLOG_ROOT_PASSWORD_SHA2=8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
- GRAYLOG_HTTP_EXTERNAL_URI=http://ip:9009/ # 这里注意要改ip
entrypoint: /usr/bin/tini -- wait-for-it elasticsearch:9200 -- /docker-entrypoint.sh
networks:
- graylog
restart: always
depends_on:
- mongo
- elasticsearch
ports:
- 9009:9000
- 1514:1514
- 1514:1514/udp
- 12201:12201
- 12201:12201/udp
networks:
graylog:
driver: bridg
这个文件里唯一需要改动的就是ip(本来的端口是9000的,我由于已经占用了9000端口了,所以我这里把端口改成了9009,你们可以随意)
嗯,写完docker-compose.yml文件,直接docker-compose up -d它就启动起来咯。
启动以后,我们就可以通过ip:port访问对应的Graylog后台地址了,默认的账号和密码是admin/admin
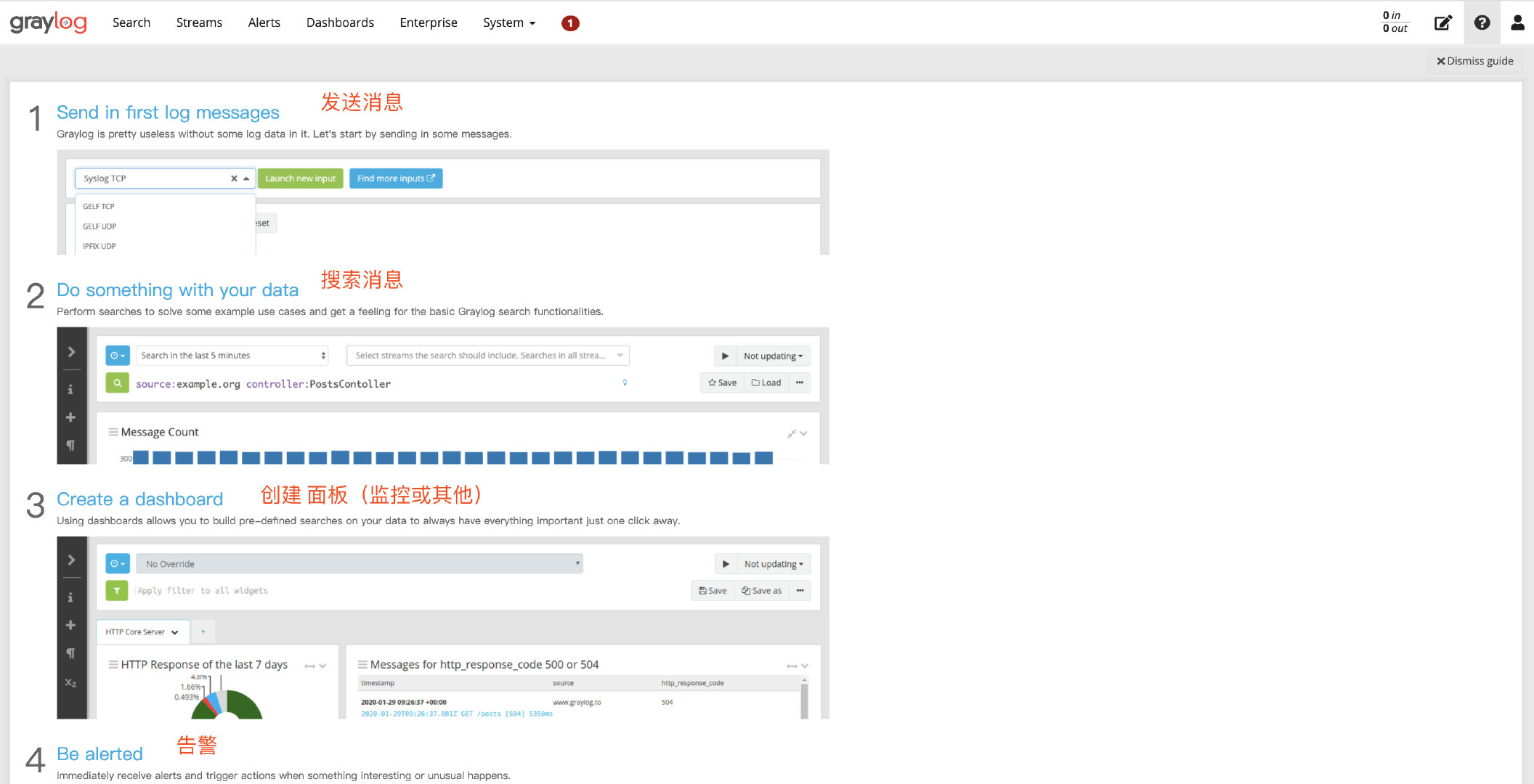
随后,我们配置下inputs的配置,找到GELF UDP,然后点击Launch new input,只需要填写Title字段,保存就完事了(其他不用动)。

嗯,到这里,我们的GrayLog设置就完成了。
03、SpringBoot使用GrayLog
还记得我们austin项目使用的日志框架吗?没错,就是logback。我们要把日志数据写入Graylog很简单,只需要两步:
1、引入依赖:
<dependency>
<groupId>de.siegmar</groupId>
<artifactId>logback-gelf</artifactId>
<version>3.0.0</version>
</dependency>
2、在logback.xml配置graylog相关的信息:
<appender name=\"GELF\" class=\"de.siegmar.logbackgelf.GelfUdpAppender\">
<!-- Graylog服务的地址 -->
<graylogHost>ip</graylogHost>
<!-- UDP Input端口 -->
<graylogPort>12201</graylogPort>
<!-- 最大GELF数据块大小(单位:字节),508为建议最小值,最大值为65467 -->
<maxChunkSize>508</maxChunkSize>
<!-- 是否使用压缩 -->
<useCompression>true</useCompression>
<encoder class=\"de.siegmar.logbackgelf.GelfEncoder\">
<!-- 是否发送原生的日志信息 -->
<includeRawMessage>false</includeRawMessage>
<includeMarker>true</includeMarker>
<includeMdcData>true</includeMdcData>
<includeCallerData>false</includeCallerData>
<includeRootCauseData>false</includeRootCauseData>
<!-- 是否发送日志级别的名称,否则默认以数字代表日志级别 -->
<includeLevelName>true</includeLevelName>
<shortPatternLayout class=\"ch.qos.logback.classic.PatternLayout\">
<pattern>%m%nopex</pattern>
</shortPatternLayout>
<fullPatternLayout class=\"ch.qos.logback.classic.PatternLayout\">
<pattern>%d - [%thread] %-5level %logger{35} - %msg%n</pattern>
</fullPatternLayout>
<!-- 配置应用名称(服务名称),通过staticField标签可以自定义一些固定的日志字段 -->
<staticField>app_name:austin</staticField>
</encoder>
</appender>
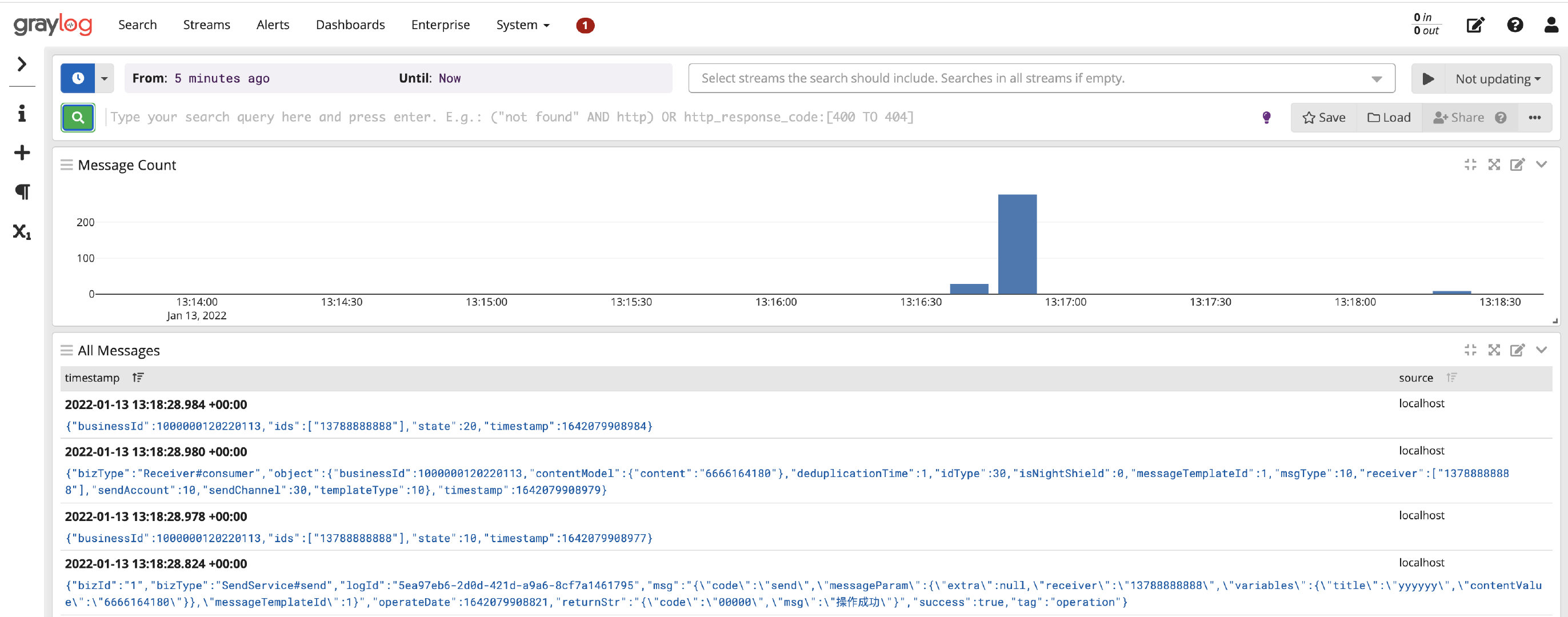
在这个配置信息里,唯一要改的也只是ip的地址,到这里接入就完毕了,我们再打开控制台,就能看到日志的信息啦。
04、懂点GrayLog
懂点GrayLog查询语法:这块我日常来来去去其实就用几个,我来展示下我平时用的吧。如果觉得不够,再去官网文档捞一把就完事了:https://docs.graylog.org/docs/query-language
1、根据字段精确查询:full_message:\"13788888888\"

2、查询错误日志信息:level_name:\"ERROR\"
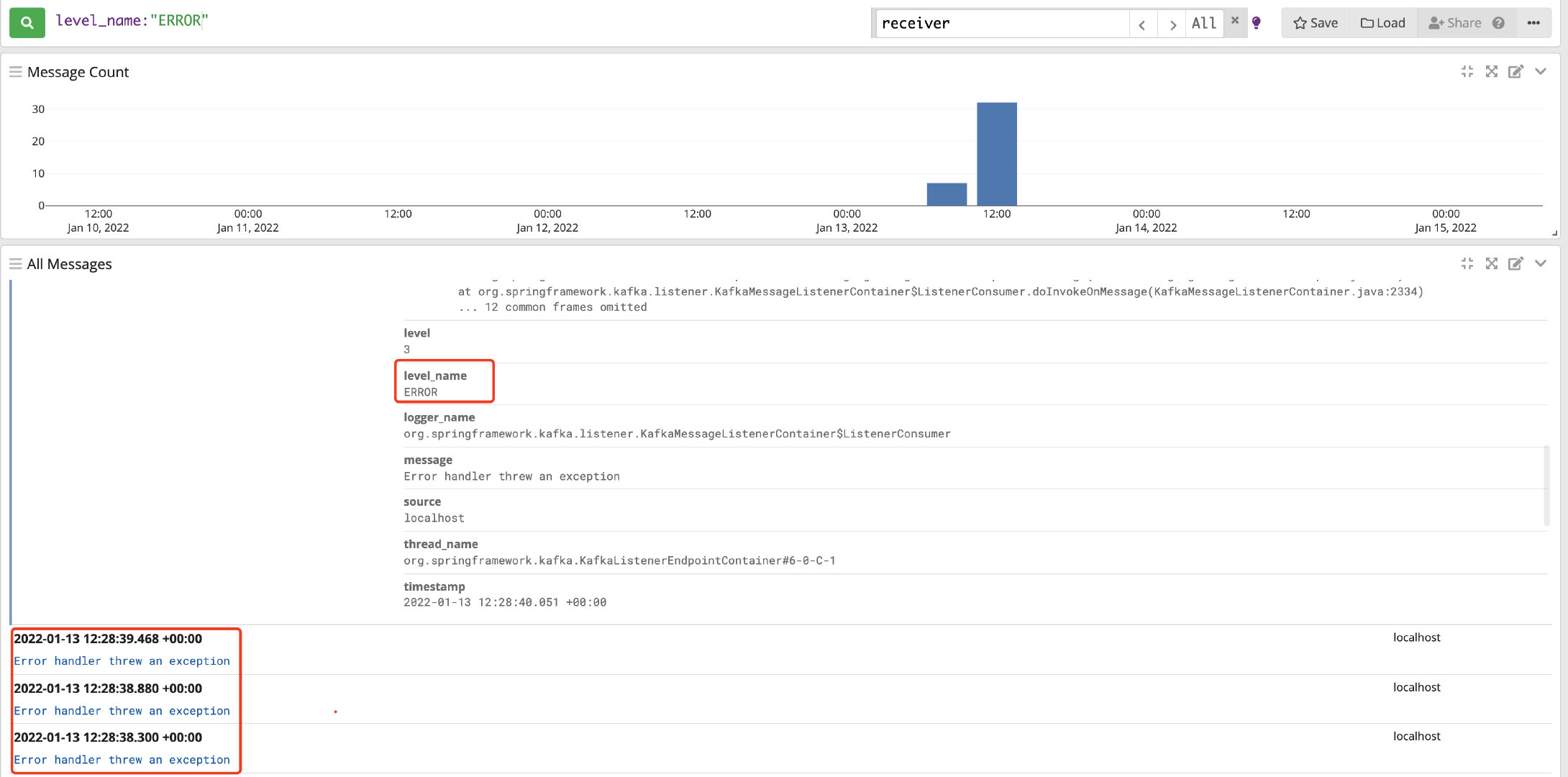
3、组合多字段查询:level_name:\"INFO\" AND full_message:\"13788888888\"
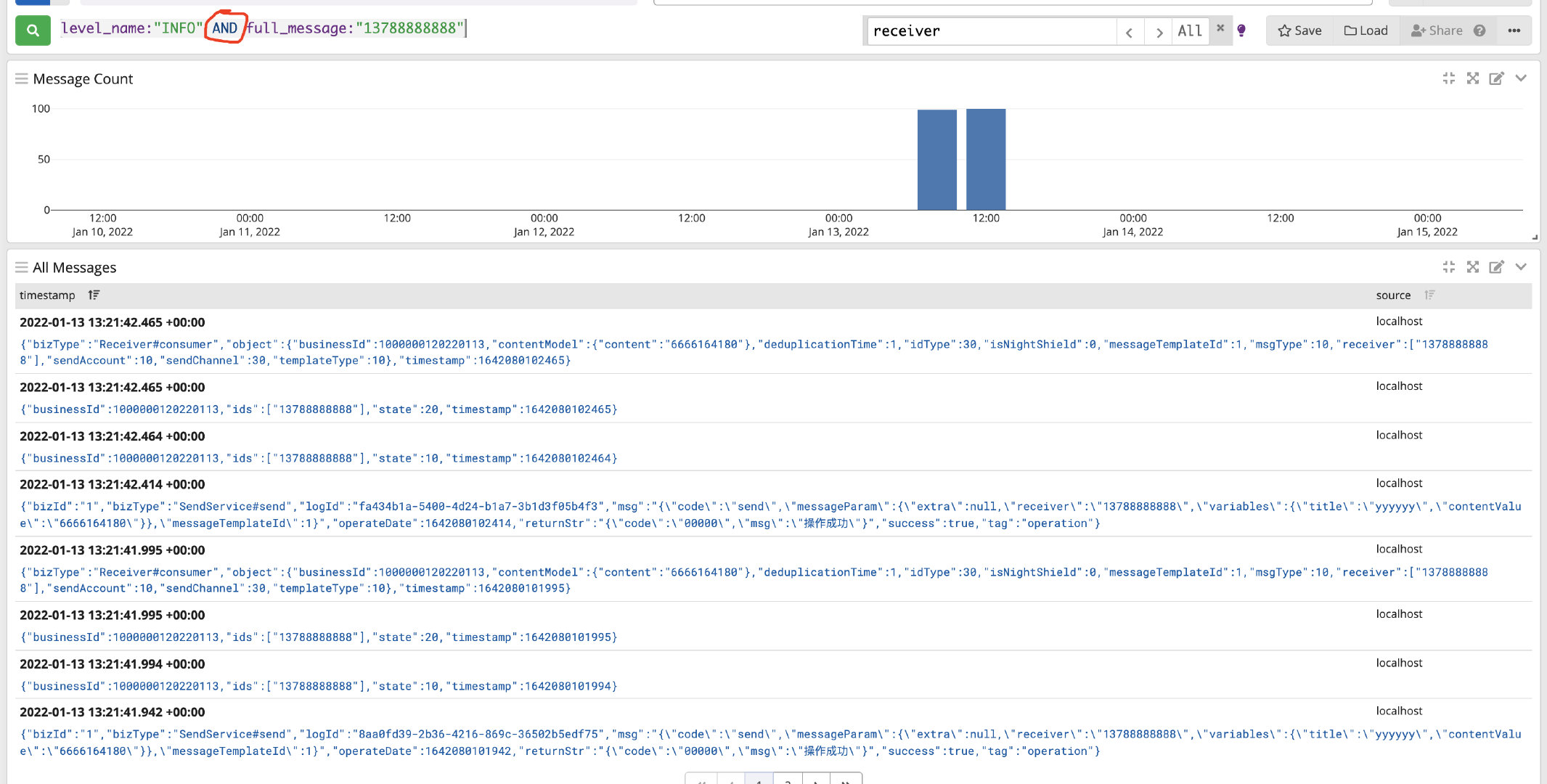
在接入的时候,仔细的小伙伴可能会发现我这边在Input的时候选择的是GELF,然后在引入Maven依赖的时候也有GELF的字样。那GELF是啥意思呢?
这块在官网也有给出对应的解释:The Graylog Extended Log Format (GELF) is a log format that avoids the shortcomings of classic plain syslog
详细资料:https://docs.graylog.org/docs/gelf
GELF是一种日志格式,能避免传统意义上的 syslogs的一些问题,而我们引入的Maven依赖则是把日志格式化成GELF格式然后append到GrayLog上。

05 、番外:Swagger
前几天有个老哥在GitHub给我提了个pull request关于swagger的,我昨天把他merge了,也升级了下swagger的版本。
之前我没用过swagger类似的文档工具,就这次pull request我也去体验了下swagger。
在初次的体验感觉是不错的:它能把项目的所有接口的文档信息都能在一个页面上统一管理,并且就能直接通过样例参数直接发送请求。通过注解的方式来进行编写文档,也不用担心代码改了然后忘了更新文档这事。
但是,后来我配置好对应的参数信息文档,再在swagger-ui体验了下,发现是真滴丑,看到这ui我还是阶段性放弃吧。

swagger的竞品还有好几个,我看ui貌似都要比swagger好看。不过,austin项目的主要接口就只有一个,我作为熟练掌握的markdown工程师能轻松胜任文档工作,就没再继续体验别的竞品了。
06、总结
之前我好像是在知乎看到过类似的一段话:一个工具或框架使用优秀,就取决于它的入门的难易。如果一个框架要花很长时间才能弄懂,那可能它做得并没那么好。
我其实不会经常去研究各种使用的框架它的细节原理,也不会蒙头就去看源码,没什么必要,毕竟它没出问题啊。
像GrayLog这种工具类的框架,如果在公司不是主要的维护者,其实不必太过于纠结他的实现细节,可以从总体上把握他的设计思想。换我建议,真要学习,还得是看它的具体存储(比如Elasticsearch的原理)
学习就要带有利益点(学了能提高效率,学了能以后在面试的时候吹牛逼进而涨工资,学了能使自己快乐,学了能装逼)
都看到这里了,点个赞一点都不过分吧?我是3y,下期见。
关注我的微信公众号【Java3y】除了技术我还会聊点日常,有些话只能悄悄说~ 【对线面试官+从零编写Java项目】 持续高强度更新中!求star!!原创不易!!求三连!!

austin项目源码Gitee链接:gitee.com/austin
austin项目源码GitHub链接:github.com/austin
更多的文章可往:文章的目录导航
来源:https://www.cnblogs.com/Java3y/p/16002730.html
本站部分图文来源于网络,如有侵权请联系删除。