 百木园
百木园《The Go Programming Language》 知识点记载,学习笔记、章节练习与个人思考。前言 · Go语言圣经 (itsfun.top)
标题后标记了小丑符号的表示还没写。
Hello, World
Go语言不需要在语句或者声明的末尾添加分号,除非一行上有多条语句。实际上,编译器会主动把特定符号后的换行符转换为分号,因此换行符添加的位置会影响Go代码的正确解析(译注:比如行末是标识符、整数、浮点数、虚数、字符或字符串文字、关键字break、continue、fallthrough或return中的一个、运算符和分隔符++、--、)、]或}中的一个)。举个例子,函数的左括号{必须和func函数声明在同一行上,且位于末尾,不能独占一行,而在表达式x + y中,可在+后换行,不能在+前换行(译注:以+结尾的话不会被插入分号分隔符,但是以x结尾的话则会被分号分隔符,从而导致编译错误)。
命令行参数
func main() {
s, sep := \"\", \"\"
for _, arg := range os.Args[1:] {
s += sep + arg
sep = \" \"
}
fmt.Println(s)
}
练习 1.3
如前文所述,每次循环迭代字符串s的内容都会更新。+=连接原字符串、空格和下个参数,产生新字符串,并把它赋值给s。s原来的内容已经不再使用,将在适当时机对它进行垃圾回收。
如果连接涉及的数据量很大,这种方式代价高昂。所以我们使用strings包的Join函数
func main() {
fmt.Println(strings.Join(os.Args[1:], \" \"))
}
练习 1.3: 做实验测量潜在低效的版本和使用了strings.Join的版本的运行时间差异。(1.6节讲解了部分time包,11.4节展示了如何写标准测试程序,以得到系统性的性能评测。)这里使用 time 包计算运行时间。
// ^ 练习 1.3: 做实验测量潜在低效的版本和使用了strings.Join的版本的运行时间差异。
package main
import (
\"fmt\"
\"strconv\"
\"strings\"
\"time\"
)
func main() {
args := make([]string, 10000)
for i := 0; i < 10000; i++ {
args = append(args, strconv.Itoa(i+1))
}
var s string
start := time.Now()
for i := range args {
s += args[i]
s += \" \"
}
// fmt.Println(s) // ^ 因为切片数量过大先不打印就只做合并操作
t := time.Since(start)
fmt.Println(\"elapsed time\", t)
/* -------------------------------------------------------------------------- */
start = time.Now()
s = strings.Join(args, \" \")
fmt.Println(s)
t = time.Since(start)
fmt.Println(\"elapsed time\", t)
}
elapsed time 230.8618ms
elapsed time 0s
可以看到前者耗费了0.23秒,后者几乎没有耗费时间
为了深入 \\(strings.Join\\) 方法,我们需要先深入 \\(strings.Builder\\) 类型
strings.Builder 源码解析
存在意义
使用 \\(strings.Builder\\),避免频繁创建字符串对象,进而提高性能
\\(Source\\ file\\) https://go.dev/src/strings/builder.go
在上面的高耗时案例中,与许多支持 \\(string\\) 类型的语言一样,\\(golang\\) 中的 \\(string\\) 类型也是只读且不可变的( \\(string\\) 类型笔记 Go xmas2020 学习笔记 04、Strings - 小能日记 - 博客园 )。因此,这种拼接字符串的方式会导致大量的string创建、销毁和内存分配。如果你拼接的字符串比较多的话,这显然不是一个正确的姿势。
在 \\(strings.Builder\\) 出来以前,我们是用 \\(bytes.Buffer\\) 来进行优化的。
func main() {
ss := []string{
\"A\",
\"B\",
\"C\",
}
var b bytes.Buffer
for _, s := range ss {
fmt.Fprint(&b, s)
}
print(b.String())
}
这里使用 var b bytes.Buffer 存放最终拼接好的字符串,一定程度上避免上面 \\(str\\) 每进行一次拼接操作就重新申请新的内存空间存放中间字符串的问题。
但这里依然有一个小问题: \\(b.String()\\) 会有一次 \\([\\ ]byte -> string\\) 类型转换。而这个操作是会进行一次内存分配和内容拷贝的。
原理解析
Golang 官方将 \\(strings.Builder\\) 作为一个\\(feature\\) 引入。
- 与 \\(byte.Buffer\\) 思路类似,既然 \\(string\\) 在构建过程中会不断的被销毁重建,那么就尽量避免这个问题,底层使用一个 \\(buf\\ [\\ ]byte\\) 来存放字符串的内容。
- 对于写操作,就是简单的将 \\(byte\\) 写入到 \\(buf\\) 即可。
- 为了解决 \\(bytes.Buffer.String()\\) 存在的 \\([\\ ]byte -> string\\) 类型转换和内存拷贝问题,这里使用了一个\\(unsafe.Pointer\\) 的内存指针转换操作,实现了直接将 \\(buf\\ [\\ ]byte\\)转换为 \\(string\\) 类型,同时避免了内存充分配的问题。
- 如果我们自己来实现 \\(strings.Builder\\) , 大部分情况下我们完成前3步就觉得大功告成了。但是标准库做得要更近一步。我们知道 Golang 的堆栈在大部分情况下是不需要开发者关注的,如果能够在栈上完成的工作逃逸到了堆上,性能就大打折扣了。因此,\\(copyCheck\\) 加入了一行比较 \\(hack\\) 的代码来避免 \\(buf\\) 逃逸到堆上。Go 栈、堆的知识可看 GopherCon SG 2019 \"Understanding Allocations\" 学习笔记 - 小能日记 - 博客园
常用方法
- String方法返回Builder构建的数据
- Len方法返回字节数组占据的字节数,1个汉字三个字节
- Cap方法返回字节数组分配的内存空间大小
- Reset方法将Builder重置为初始状态
- Write方法将字节数组加添加到buf数组后面
- WriteByte将字节c添加到buf数组后边
- WriteRune将rune字符添加到buf数组后面
- WriteString将字符串添加到buf数组后面
写入方法
\\(bytes.Buffer\\) 也支持这四个写入方法。
func (b *Builder) Write(p []byte) (int, error)
func (b *Builder) WriteByte(c byte) error
func (b *Builder) WriteRune(r rune) (int, error)
func (b *Builder) WriteString(s string) (int, error)
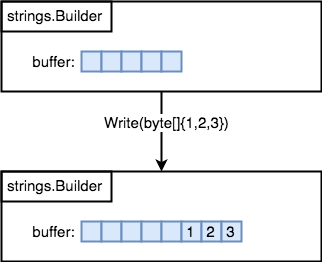
strings.Builderorganizes the content based on the internal slice to organize. When you call write-methods, they append new bytes to inner-slice. If the slice’s capacity is reached, Go will allocate a new slice with different memory space and copy old slice to a new one. It will take resource to do when the slice is large or it may create the memory issueThe
runeand a character ofstringcan be more than 1 bytes when youWriteRune()orWriteString()
我们可以预定义切片的容量来避免重新分配。
扩容方法
追加内容也有讲究,因为底层是 \\(slice\\),追加数据时有可能引起 \\(slice\\) 扩容。一般的优化方案是为 \\(slice\\) 初始化合理的空间,避免多次扩容复制。\\(Builder\\) 也提供了预分配内存的方法,如 \\(Grow\\) 方法。
func (b *Builder) grow(n int) {
buf := make([]byte, len(b.buf), 2*cap(b.buf)+n)
copy(buf, b.buf)
b.buf = buf
}
func (b *Builder) Grow(n int) {
b.copyCheck()
if n < 0 {
panic(\"strings.Builder.Grow: negative count\")
}
if cap(b.buf)-len(b.buf) < n {
b.grow(n)
}
}
注意扩容的容量和 \\(slice\\) 直接扩容两倍的方式略有不同,它是2*cap(b.buf)+n,之前容量的两倍加 \\(n\\)。
- 如果容量是10,长度是5,调用 \\(Grow(3)\\)结果是什么?当前容量足够使用,没有任何操作;
- 如果容量是10,长度是5,调用 \\(Grow(7)\\)结果是什么?剩余空间是5,不满足7个扩容空间,底层需要扩容。扩容的时候按照之前容量的两倍再加 \\(n\\) 的新容量扩容,结果是 \\(2*10+7=27\\)。
String() 方法
func (b *Builder) String() string {
return *(*string)(unsafe.Pointer(&b.buf))
}
先获取 \\([\\ ]byte\\) 地址,然后转成字符串指针,然后再取地址。
从 ptype 输出的结构来看,string 可看做 [2]uintptr,而 [ ]byte 则是 [3]uintptr,这便于我们编写代码,无需额外定义结构类型。如此,str2bytes 只需构建 [3]uintptr{ptr, len, len},而 bytes2str 更简单,直接转换指针类型,忽略掉 cap 即可。
禁止复制
type Builder struct {
addr *Builder // of receiver, to detect copies by value
buf []byte
}
\\(Builder\\) 的底层数据,它还有个字段 \\(addr\\) ,是一个指向 \\(Builder\\) 的指针。默认情况是它会指向自己。
b.addr = (*Builder)(noescape(unsafe.Pointer(b)))
\\(copyCheck\\) 用来保证复制后不允许修改的逻辑。仔细看下源码,如果 \\(addr\\) 是空,也就是没有数据的时候是可以被复制后修改的,一旦那边有数据了,就不能这么搞了。在 \\(Grow\\)、\\(Write\\)、\\(WriteByte\\)、\\(WriteString\\)、\\(WriteRune\\) 这五个函数里都有这个检查逻辑。
var b1 strings.Builder
b2 := b1
b2.WriteString(\"DEF\")
b1.WriteString(\"ABC\")
// b1 = ABC, b2 = DEF
var b1 strings.Builder
b1.WriteString(\"ABC\")
b2 := b1
b2.WriteString(\"DEF\")
代码将会报错 illegal use of non-zero Builder copied by value
下面的意思是拷贝过来的Builder进行添加修改,会造成其他Builder的修改。
When we copy the Builder, we clone the pointer of the slice but they still point to the old array. The problem will be occurs when you try to
Writesomething to copied Builder or source Builder, the other’s content will be affects. That’s reason whystrings.Builderprevent copy actions.
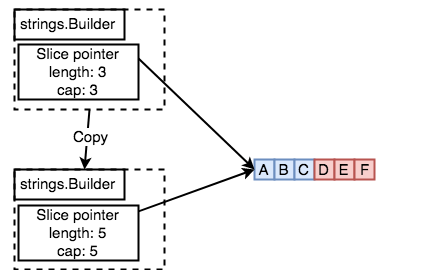
我们可以使用 \\(Reset\\) 方法对 \\(addr、buf\\) 置空。下面拷贝了使用 \\(Reset\\) 后不会报错。
var b1 strings.Builder
b1.WriteString(\"ABC\")
b2 := b1
fmt.Println(b2.Len()) // 3
fmt.Println(b2.String()) // ABC
b2.Reset()
b2.WriteString(\"DEF\")
fmt.Println(b2.String()) // DEF
线程不安全
func main() {
var b strings.Builder
var n int32
var wait sync.WaitGroup
for i := 0; i < 1000; i++ {
wait.Add(1)
go func() {
atomic.AddInt32(&n, 1)
b.WriteString(\"1\")
wait.Done()
}()
}
wait.Wait()
fmt.Println(len(b.String()), n)
}
905 1000
结果是 \\(905\\ 1000\\),并不都是 \\(1000\\) 。如果想保证线程安全,需要在 \\(WriteString\\) 的时候加锁。
io.Writer 接口
\\(strings.Builder\\) 实现了 \\(io.Writer\\) 接口。可以使用在很多例子中
- io.Copy(dst Writer, src Reader) (written int64, err error)
- bufio.NewWriter(w io.Writer) *Writer
- fmt.Fprint(w io.Writer, a …interface{}) (n int, err error)
- func (r *http.Request) Write(w io.Writer) error
- and other libraries that uses \\(io.Writer\\)
代码
func main() {
var b strings.Builder
fmt.Printf(\"%v\", b)
fmt.Println(b.Len(), b.Cap())
for i := 3; i >= 1; i-- {
fmt.Fprintf(&b, \"%d#\", i)
fmt.Printf(\"%v\\n\", b)
fmt.Println(b.Len(), b.Cap())
}
b.WriteString(\"Hello\")
fmt.Printf(\"%v\\n\", b)
fmt.Println(b.Len(), b.Cap())
fmt.Println(b.String())
// b.Grow(5) // ^ 扩容
b.Grow(88) // ^ 扩容
fmt.Printf(\"%v\\n\", b)
fmt.Println(b.Len(), b.Cap())
fmt.Println(unsafeEqual(\"Hello\", []byte{72, 101, 108, 108, 111}))
}
func unsafeEqual(a string, b []byte) bool {
bbp := *(*string)(unsafe.Pointer(&b))
return a == bbp
}
{<nil> []}0 0
{0xc0001223a0 [51 35]}
2 8
{0xc0001223a0 [51 35 50 35]}
4 8
{0xc0001223a0 [51 35 50 35 49 35]}
6 8
{0xc0001223a0 [51 35 50 35 49 35 72 101 108 108 111]}
11 16
3#2#1#Hello
{0xc0001223a0 [51 35 50 35 49 35 72 101 108 108 111]}
11 120
true
strings.Join 源码解析
实现原理
// Join concatenates the elements of its first argument to create a single string. The separator
// string sep is placed between elements in the resulting string.
func Join(elems []string, sep string) string {
switch len(elems) {
case 0:
return \"\"
case 1:
return elems[0]
}
n := len(sep) * (len(elems) - 1)
for i := 0; i < len(elems); i++ {
n += len(elems[i])
}
var b Builder
b.Grow(n)
b.WriteString(elems[0])
for _, s := range elems[1:] {
b.WriteString(sep)
b.WriteString(s)
}
return b.String()
}
前面计算出整个字符串需要的长度 \\(n\\),然后创建 \\(strings.Builder\\) 并通过 \\(Grow\\) 方法直接扩容,大小为 \\(0*2+n\\) 为 \\(n\\) ,然后通过 \\(WriteString\\) 方法写入,最后调用 \\(String\\) 方法返回字符串。只构造了一次字符串对象。
查找重复的行
func main() {
counts := make(map[string]int)
files := os.Args[1:]
if len(files) == 0 {
countLines(os.Stdin, counts)
} else {
for _, arg := range files {
f, err := os.Open(arg)
if err != nil {
fmt.Fprintf(os.Stderr, \"dup2: %v\\n\", err)
continue
}
countLines(f, counts)
f.Close()
}
}
for line, n := range counts {
if n > 1 {
fmt.Printf(\"%d\\t%s\\n\", n, line)
}
}
}
func countLines(f *os.File, counts map[string]int) {
input := bufio.NewScanner(f)
for input.Scan() {
counts[input.Text()]++
}
// NOTE: ignoring potential errors from input.Err()
}
bufio.Scanner
程序使用短变量声明创建bufio.Scanner类型的变量input。
input := bufio.NewScanner(os.Stdin)
该变量从程序的标准输入中读取内容。每次调用input.Scan(),即读入下一行,并移除行末的换行符;读取的内容可以调用input.Text()得到。Scan函数在读到一行时返回true,不再有输入时返回false。
map 传递
map是一个由make函数创建的数据结构的引用。map作为参数传递给某函数时,该函数接收这个引用的一份拷贝(copy,或译为副本),被调用函数对map底层数据结构的任何修改,调用者函数都可以通过持有的map引用看到。在我们的例子中,countLines函数向counts插入的值,也会被main函数看到。(译注:类似于C++里的引用传递,实际上指针是另一个指针了(函数里的局部变量),但内部存的值指向同一块内存)
为了打印结果,我们使用了基于range的循环,并在counts这个map上迭代。跟之前类似,每次迭代得到两个结果,键和其在map中对应的值。map的迭代顺序并不确定,从实践来看,该顺序随机,每次运行都会变化。这种设计是有意为之的,因为能防止程序依赖特定遍历顺序,而这是无法保证的。
ioutil.ReadFile
ReadFile函数一口气把全部输入数据读到内存中,返回一个字节切片(byte slice),必须把它转换为string,才能用strings.Split分割。
练习 1.4
练习 1.4: 修改dup2,出现重复的行时打印文件名称。
func main() {
counts := make(map[string]int)
counts_fileid := make(map[string]string)
files := os.Args[1:]
if len(files) == 0 {
countLines(os.Stdin, counts, counts_fileid)
} else {
for _, arg := range files {
f, err := os.Open(arg)
if err != nil {
fmt.Fprintf(os.Stderr, \"dup2: %v\\n\", err)
continue
}
countLines(f, counts, counts_fileid)
f.Close()
}
}
for line, n := range counts {
if n > 1 {
fmt.Printf(\"%d\\t%s\\t%v\\n\", n, line, counts_fileid[line])
}
}
}
func countLines(f *os.File, counts map[string]int, counts_fileid map[string]string) {
input := bufio.NewScanner(f)
for input.Scan() {
counts[input.Text()]++
counts_fileid[input.Text()] = f.Name()
}
}
hello Server
world
hello Server
123456
cat
123456
hello Server
hello
world
123456
3 hello Server data.txt
2 world data2.txt
3 123456 data2.txt
为什么 Map 中 Key 是无序的 🤡
且听下回分解,会更新一篇独立的文章
GIF 动画
练习 1.6
练习 1.6: 修改Lissajous程序,修改其调色板来生成更丰富的颜色,然后修改SetColorIndex的第三个参数,看看显示结果吧。
package main
import (
\"image\"
\"image/color\"
\"image/gif\"
\"io\"
\"math\"
\"math/rand\"
\"os\"
\"time\"
)
var palette = []color.Color{
color.White,
color.RGBA{0, 255, 0, 255},
color.RGBA{255, 0, 0, 255},
color.RGBA{0, 0, 255, 255},
color.RGBA{100, 255, 0, 255},
color.RGBA{0, 255, 100, 255},
}
const (
whiteIndex = 0 // first color in palette
blackIndex = 1 // next color in palette
)
func main() {
// The sequence of images is deterministic unless we seed
// the pseudo-random number generator using the current time.
// Thanks to Randall McPherson for pointing out the omission.
rand.Seed(time.Now().UTC().UnixNano())
lissajous(os.Stdout)
}
func lissajous(out io.Writer) {
const (
cycles = 2 // number of complete x oscillator revolutions
res = 0.001 // angular resolution
size = 100 // image canvas covers [-size..+size]
nframes = 64 // number of animation frames
delay = 8 // delay between frames in 10ms units
)
freq := rand.Float64() * 3.0 // relative frequency of y oscillator
anim := gif.GIF{LoopCount: nframes}
phase := 0.0 // phase difference
for i := 0; i < nframes; i++ {
rect := image.Rect(0, 0, 2*size+1, 2*size+1)
img := image.NewPaletted(rect, palette)
for t := 0.0; t < cycles*2*math.Pi; t += res {
x := math.Sin(t)
y := math.Sin(t*freq + phase)
img.SetColorIndex(size+int(x*size+0.5), size+int(y*size+0.5),
uint8(x*size)%5+1)
}
phase += 0.1
anim.Delay = append(anim.Delay, delay)
anim.Image = append(anim.Image, img)
}
gif.EncodeAll(out, &anim) // NOTE: ignoring encoding errors
}
这里修改了原代码中的 \\(palette\\) 、\\(img.SetColorIndex\\) 方法。需要注意的是,如果使用 \\(powershell\\) 重定向管道 go run . > out.gif 生成的 \\(gif\\) 图片将会出错无法打开。具体原因是 \\(powershell\\) 的标准输出流如果进行管道重定向会进行转换。
The GIF file (the gif data) is a binary format, not textual. Attempting to write it to the standard output and redirecting that to a file may suffer transformations. For example, the Windows PowerShell most likely converts some control characters (like
\"\\n\"to\"\\r\\n\"), so the resulting binary will not be identical to whatgif.EncodeAll()writes to the standard output. Apparentlycmd.exedoes not do such transformations.
解决方法可以用其他命令行工具比如 \\(cmd\\),或者在代码中明确使用 \\(os.File\\) 创建文件等形式。
获取URL
练习 1.7-1.9
练习 1.7: 函数调用io.Copy(dst, src)会从src中读取内容,并将读到的结果写入到dst中,使用这个函数替代掉例子中的ioutil.ReadAll来拷贝响应结构体到os.Stdout,避免申请一个缓冲区(例子中的b)来存储。记得处理io.Copy返回结果中的错误。
练习 1.8: 修改fetch这个范例,如果输入的url参数没有 http:// 前缀的话,为这个url加上该前缀。你可能会用到strings.HasPrefix这个函数。
练习 1.9: 修改fetch打印出HTTP协议的状态码,可以从resp.Status变量得到该状态码。
// Fetch prints the content found at a URL.
package main
import (
\"fmt\"
\"io\"
\"net/http\"
\"os\"
\"strings\"
)
func main() {
for _, url := range os.Args[1:] {
if !strings.HasPrefix(url, \"https://\") {
url = \"https://\" + url
}
resp, err := http.Get(url)
fmt.Println(\"Status\", resp.Status)
if err != nil {
fmt.Fprintf(os.Stderr, \"fetch: %v\\n\", err)
os.Exit(1)
}
// b, err := ioutil.ReadAll(resp.Body)
b, err := io.Copy(os.Stdout, resp.Body)
resp.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, \"fetch: reading %s: %v\\n\", url, err)
os.Exit(1)
}
fmt.Println(b)
}
}
(base) PS L:\\IT\\Go\\Codes\\Work\\Study\\Gopl\\ch1\\1.789> go run . https://wolflong.com
Status 200 OK
<!DOCTYPE html>
<html>
<head>
<meta charset=\"UTF-8\">
<title></title>
<script type=\"text/javascript\">
location.href=\"https://www.cnblogs.com/linxiaoxu/\";
</script>
</head>
<body>
</body>
</html>
206
并发获取多个URL 🤡
练习 1.10: 找一个数据量比较大的网站,用本小节中的程序调研网站的缓存策略,对每个URL执行两遍请求,查看两次时间是否有较大的差别,并且每次获取到的响应内容是否一致,修改本节中的程序,将响应结果输出到文件,以便于进行对比。
练习 1.11: 在fetchall中尝试使用长一些的参数列表,比如使用在alexa.com的上百万网站里排名靠前的。如果一个网站没有回应,程序将采取怎样的行为?(Section8.9 描述了在这种情况下的应对机制)。
Web 服务
练习 1.12
练习 1.12: 修改Lissajour服务,从URL读取变量,比如你可以访问 http://localhost:8000/?cycles=20 这个URL,这样访问可以将程序里的cycles默认的5修改为20。字符串转换为数字可以调用strconv.Atoi函数。你可以在godoc里查看strconv.Atoi的详细说明。
将 Lissajous 函数内的局部常量移动到函数外成为包变量,将 const 修改为 var 后出错。
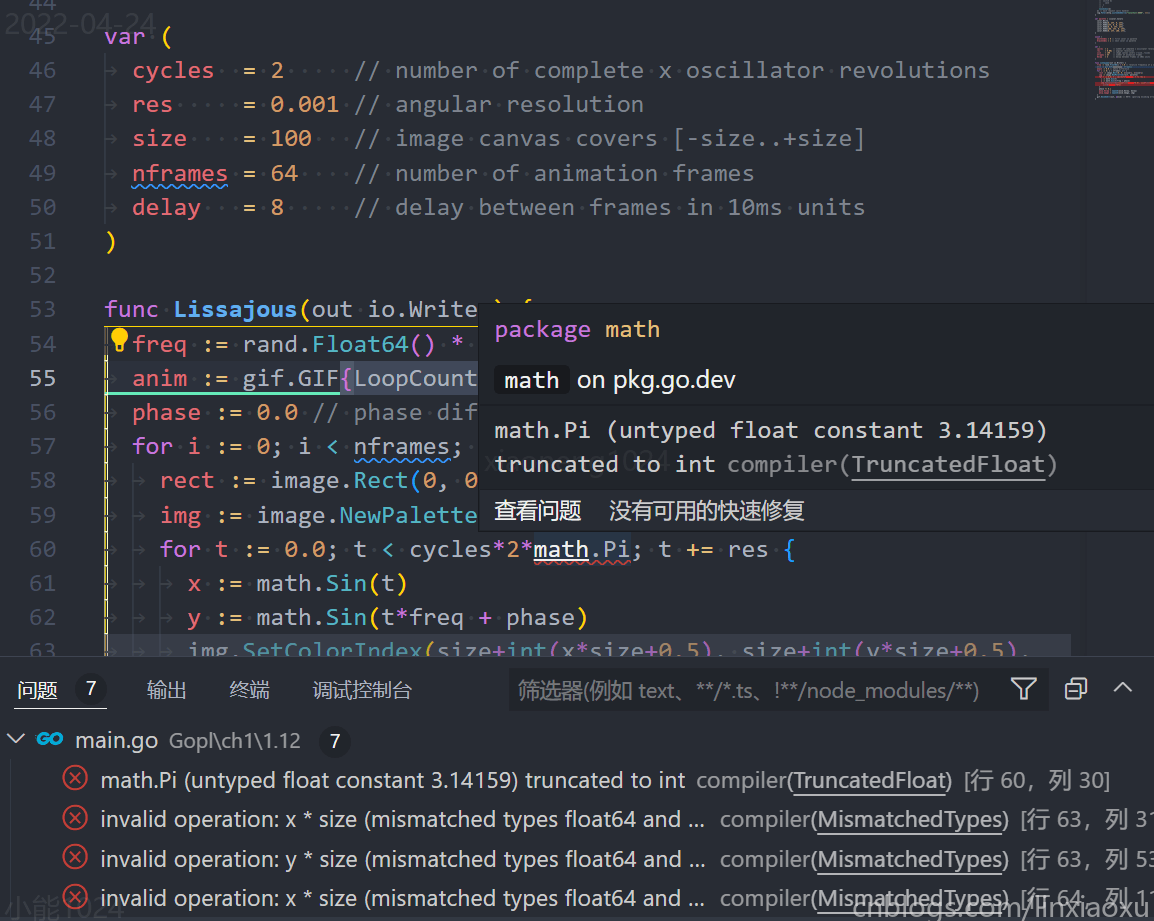
错误原因是常量声明时类型并没有确定,在给定计算的时候才确定了常量的类型。而将 const 改为 var 后,类型在声明的时候就被确定了。不同类型是不能做基本运算的,要进行类型转换。如下面错误给 size 外侧包一层 float64 即可。
invalid operation: size + int(x * size + 0.5) (mismatched types float64 and int)
package main
import (
\"fmt\"
\"image\"
\"image/color\"
\"image/gif\"
\"io\"
\"log\"
\"math\"
\"math/rand\"
\"net/http\"
\"os\"
\"strconv\"
\"time\"
)
func main() {
var err error
rand.Seed(time.Now().UTC().UnixNano())
http.HandleFunc(\"/\", func(w http.ResponseWriter, r *http.Request) {
if err := r.ParseForm(); err != nil {
log.Print(err)
}
for k, v := range r.Form {
fmt.Printf(\"Form[%q] = %q\\n\", k, v)
switch k {
case \"cycles\":
cycles, err = strconv.Atoi(v[0])
case \"size\":
size, err = strconv.Atoi(v[0])
}
if err != nil {
println(err)
os.Exit(1)
}
}
Lissajous(w)
}) // each request calls handler
log.Fatal(http.ListenAndServe(\"localhost:8000\", nil))
}
var palette = []color.Color{
color.White,
color.RGBA{0, 255, 0, 255},
color.RGBA{255, 0, 0, 255},
color.RGBA{0, 0, 255, 255},
color.RGBA{100, 255, 0, 255},
color.RGBA{0, 255, 100, 255},
}
const (
whiteIndex = 0 // first color in palette
blackIndex = 1 // next color in palette
)
var (
cycles = 2 // number of complete x oscillator revolutions
res = 0.001 // angular resolution
size = 100 // image canvas covers [-size..+size]
nframes = 64 // number of animation frames
delay = 8 // delay between frames in 10ms units
)
func Lissajous(out io.Writer) {
freq := rand.Float64() * 3.0 // relative frequency of y oscillator
anim := gif.GIF{LoopCount: nframes}
phase := 0.0 // phase difference
for i := 0; i < nframes; i++ {
rect := image.Rect(0, 0, 2*size+1, 2*size+1)
img := image.NewPaletted(rect, palette)
for t := 0.0; t < float64(cycles*2)*math.Pi; t += res {
x := math.Sin(t)
y := math.Sin(t*freq + phase)
img.SetColorIndex(size+int(x*float64(size)+0.5), size+int(y*float64(size)+0.5),
uint8(x*float64(size))%5+1)
}
phase += 0.1
anim.Delay = append(anim.Delay, delay)
anim.Image = append(anim.Image, img)
}
gif.EncodeAll(out, &anim) // NOTE: ignoring encoding errors
}
运行程序,访问本地服务 http://localhost:8000/?cycles=10&size=500

------ 课外补充 ------
静态编译、动态编译
静态库
静态库是指在我们的应用中,有一些公共代码是需要反复使用,就把这些代码编译为“库”文件;在链接步骤中,连接器将从库文件取得所需的代码,复制到生成的可执行文件中的这种库。
程序编译一般需经预处理、编译、汇编和链接几个步骤。静态库特点是可执行文件中包含了库代码的一份完整拷贝;缺点就是被多次使用就会有多份冗余拷贝。
动态库
动态链接库(Dynamic Link Library 或者 Dynamic-link Library,缩写为 DLL),是微软公司在微软Windows操作系统中,实现共享函数库概念的一种方式。
动态链接库文件,是一种不可执行的二进制程序文件,它允许程序共享执行特殊任务所必需的代码和其他资源。Windows 提供的DLL文件中包含了允许基于 Windows 的程序在 Windows 环境下操作的许多函数和资源。一般被存放在电脑的\"C:\\Windows\\System32\" 目录下。
DLL的最初目的是节约应用程序所需的磁盘和内存空间。在一个传统的非共享库中,一部分代码简单地附加到调用的程序上。如果两个程序调用同一个子程序,就会出现两份那段代码。相反,许多应用共享的代码能够切分到一个DLL中,在硬盘上存为一个文件,在内存中使用一个实例(instance)。DLL的广泛应用使得早期的视窗能够在紧张的内存条件下运行。
DLL提供了如模块化这样的共享库的普通好处。模块化允许仅仅更改几个应用程序共享使用的一个DLL中的代码和数据而不需要更改应用程序自身。这种模块化的基本形式允许如Microsoft Office、Microsoft Visual Studio、甚至Microsoft Windows自身这样大的应用程序使用较为紧凑的补丁和服务包。
尽管有这么多的优点,使用DLL也有一个缺点:DLL地狱,也就是几个应用程序在使用同一个共享DLL库发生版本冲突。这样的冲突可以通过将不同版本的问题DLL放到应用程序所在的文件夹而不是放到系统文件夹来解决;但是,这样将抵消共享DLL节约的空间。目前,Microsoft .NET将解决DLL hell问题当作自己的目标,它允许同一个共享库的不同版本并列共存。由于现代的计算机有足够的磁盘空间和内存,这也可以作为一个合理的实现方法。
静态库与动态库
静态库和动态库是两种共享程序代码的方式,它们的区别是:静态库在程序的链接阶段被复制到了程序中,和程序运行的时候没有关系;动态库在链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用。使用动态库的优点是系统只需载入一次动态库,不同的程序可以得到内存中相同的动态库的副本,因此节省了很多内存。
静态编译
静态编译,就是编译器在编译可执行文件的时候,将可执行文件需要调用的对应静态库(.a或.lib)中的部分提取出来,链接到可执行文件中去,使可执行文件在运行的时候不依赖于动态链接库。
静态编译、动态编译区别
动态编译的可执行文件需要附带一个的动态链接库。在执行时,需要调用其对应动态链接库中的命令。所以其优点一方面是缩小了执行文件本身的体积,另一方面是加快了编译速度,节省了系统资源。缺点一是哪怕是很简单的程序,只用到了链接库中的一两条命令,也需要附带一个相对庞大的链接库;二是如果其他计算机上没有安装对应的运行库,则用动态编译的可执行文件就不能运行。
静态编译就是编译器在编译可执行文件的时候,将可执行文件需要调用的对应静态库(.a或.lib)中的部分提取出来,链接到可执行文件中去,使可执行文件在运行的时候不依赖于动态链接库。所以其优缺点与动态编译的可执行文件正好互补。
Go 语言中采用静态编译,所以不用担心在系统库更新的时候冲突
查漏补缺
类型别名
语言自身的类型别名包括:\\(byte\\ rune\\)
还可以使用 type 关键字来定义类型别名
type Alias = Origin
需要注意别名和原类型之间的等号,源代码举例
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
// used, by convention, to distinguish byte values from 8-bit unsigned
// integer values.
type byte = uint8
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32
别名和原类型是等同的,不需要显式转换
Channel
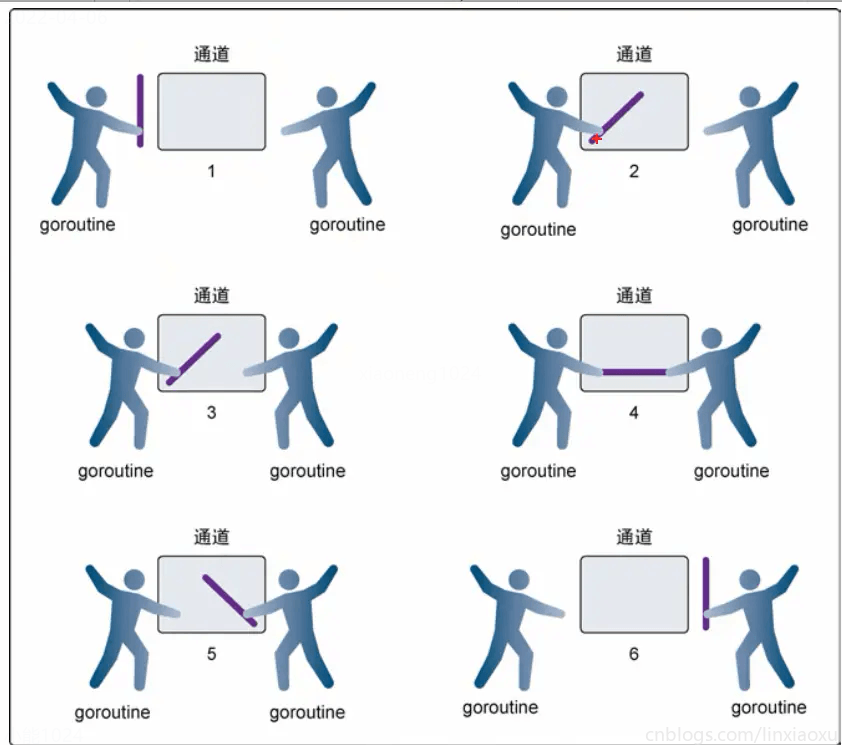
无缓存的通道要求goroutine和接收goroutine同时准备好,才能完成发送和接收操作,如果两个goroutine没有同时准备好,通道会导致先执行发送或接收操作的gotourine阻塞等待。
-
在第一步,两个goroutine都到达通道,但哪个都没有开始执行发送或者接收。
-
在第二步,左侧的goroutine将它的手伸进了通道,这模拟了向通道发送数据的行为,这时,这个goroutine会在通道中被锁住,直到交换完成。
-
在第三步,右侧的goroutine将它的手放入通道,这模拟了从通道里接收数据。这个goroutine一样也会在通道中被锁住,直到交换完成。
-
在第四步和第五步,进行交换,并最终,在第六步,两个goroutine都将他们的手从通道里拿出来,这模拟了被锁住的goroutine得到释放,两个goroutine现在都可以去做别的事情了。
第二条和第三条看不懂可跳过。第三条原文是无缓存,我将它改为了有缓存,因为我觉得没有缓存Channel的len、cap应该是 0,后面语句就不成立了。第二条相当于在做一个判空操作。
- 有缓存 Channel:
ch <- v发生在v <- ch之前 - 有缓存 Channel:
close(ch)发生在v <- ch && v == isZero(v)之前 - 有缓存 Channel: 如果
len(ch) == C,则从 Channel 中收到第 k 个值发生在 k+C 个值得发送完成之前 - 无缓存 Channel:
v <- ch发生在ch <- v之前
直观上我们很好理解他们之间的差异: 对于有缓存 Channel 而言,内部有一个缓冲队列,数据会优先进入缓冲队列,而后才被消费, 即向通道发送数据 ch <- v 发生在从通道接受数据 v <- ch 之前; 对于无缓存 Channel 而言,内部没有缓冲队列,即向通道发送数据 ch <- v 一旦出现, 通道接受数据 v <- ch 会立即执行, 因此从通道接受数据 v <- ch 发生在向通道发送数据 ch <- v 之前。 我们随后再根据实际实现来深入理解这一内存模型。
Go 语言还内建了 close() 函数来关闭一个 Channel
但语言规范规定了一些要求:
- 读写 nil Channel 会永远阻塞,关闭 nil Channel 会导致 panic
- 关闭一个已关闭的 Channel 会导致 panic
- 向已经关闭的 Channel 发送数据会导致 panic
- 向已经关闭的 Channel 读取数据不会导致 panic,但读取的值为 Channel 传递的数据类型的零值,可以通过接受语句第二个返回值来检查 Channel 是否关闭且排空
v, ok := <- ch
if !ok {
... // 如果是非缓冲 Channel ,说明已经关闭;如果是带缓冲 Channel ,说明已经关闭,且其内部缓冲区已经排空
}
错误处理
Go 语言的错误处理被设计为值类型,错误以接口的形式在语言中进行表达:
type error interface {
Error() string
}
任何实现了 error 接口的类型均可以作为 error 类型。对于下面的 CustomErr 结构而言:
type CustomErr struct {
err error
}
func (c CustomErr) Error() string {
return fmt.Sprintf(\"err: %v\", c.err)
}
由于其实现了 Error() 方法,于是可以以 error 类型返回给上层调用:
func foo() error {
return CustomErr{errors.New(\"this is an error\")}
}
func main() {
err := foo()
if err != nil { panic(err) }
}
除了错误值以外,还可以使用 panic 与 recover 内建函数来进行错误的传播:
func panic(v interface{})
func recover() interface{}
来源:https://www.cnblogs.com/linxiaoxu/p/16187331.html
本站部分图文来源于网络,如有侵权请联系删除。