 百木园
百木园课程地址 go-class-slides/xmas-2020 at trunk · matt4biz/go-class-slides (github.com)
主讲老师 Matt Holiday

00-02-Hello Example
目录结构
L:.
│ main.go
│
└───hello
hello.go
hello_test.go
- main.go 是主程序入口
- hello.go 是 hello 模块
- hello_test.go 用于单元测试 hello 模块
不一样的Hello World
hello.go
package hello
import (
\"strings\"
)
func Say(names []string) string {
if len(names) == 0 {
names = []string{\"world\"}
}
return \"Hello, \" + strings.Join(names, \", \") + \"!\"
}
传入参数是一个字符串切片,当切片长度为 0 时,自动给定一个长度为 1 的切片。
然后调用 strings.Join 方法将字符串切片各个元素根据间隔符 ,合并,在进行 + 运算符后返回完整字符串。
巧妙的单元测试
hello_test.go
package hello
import \"testing\"
func TestSayHello(t *testing.T) {
subtests := []struct {
items []string
result string
}{
{
result: \"Hello, world!\",
},
{
items: []string{\"Matt\"},
result: \"Hello, Matt!\",
},
{
items: []string{\"Matt\", \"Anne\"},
result: \"Hello, Matt, Anne!\",
},
}
for _, st := range subtests {
if s := Say(st.items); s != st.result {
t.Errorf(\"wanted %s (%v) | got %s\", st.result, st.items, s)
}
}
}
subtests 是一个匿名结构体的切片,我们可以在第二个花括号定义切片元素。
将参数与结果放在一起,for循环 subtests 进行多个单元测试,如果与预期不符就通过 t.Errorf 报错
因为 Say 方法在 Hello.go 中首字母大写声明,所以为 Public 公开,外界可用
传入os.Args切片
main.go
package main
import (
\"Work/Work/Study/Matt/2_cmd/hello\"
\"fmt\"
\"os\"
)
func main() {
fmt.Println(\"Hello,\", hello.Say(os.Args[1:]))
}
导入了hello包,通过 包名.方法名 调用(可以给包名起别名),因为 Say 函数需要传入一个字符串切片,我们不能直接传入 os.Args[1] 否则是一个字符串变量,巧妙的是可以用切片截取 os.Args[1:] 的方式获取一整个切片。
os.Args[n] 通常是运行go程序时添加的多余参数,os.Args[0] 是程序的绝对路径。
go run main.go cat dog
os.Args[0] 输出 C:/xxx/xxx/xxx/main.go
os.Args[1] 输出 cat
os.Args[2] 输出 dog
go mod init
go mod init hello
用于在当前根目录下生成 go.mod 文件,可以 ignore GOPATH,可用于在任何目录下的代码编写。go 会自动做处理。
03-Basic Types
变量类型与解释器

先看右图,在 python 中,a并不是计算机实际意义上的数字,a是在解释器中表示或伪装的数字,使用C编写的解释器将使用底层硬件来做实际的数学运算,把这些东西编成二进制数字。所以在python中虽然a=2,但计算机并不能立刻知道。
来看左图,a纯粹是机器中内存位置的地址,没有解释器,没有jvm。这就是go的性能优势,go编译器直接生成机器代码,操作要快很多。
a:=2 在64位系统上,默认 64位 int
不要用内置浮点类型表示金钱
尝试使用内置浮点类型来表示金钱是一种不好的做法,几乎所有语言都是如此。浮点数实际上是为了科学计算。
使用内置浮点数表示金钱会有表示错误(精确度问题),缺少逻辑(100美分三次分割问题)
变量声明方式

特殊类型

go 中布尔值跟数字双方是独立的,不能互相转换和比较。
变量初始化

如果不希望初始化最好使用 var 声明变量,如果需要初始化使用短声明语法
常量定义

go 限制常量为 数字,字符串,布尔值 类型。
类型转换
package main
import \"fmt\"
func main() {
a := 2
b := 3.1
fmt.Printf(\"a: %8T %v\\n\", a, a)
fmt.Printf(\"b: %8T %[1]v\\n\", b) // ^ [1] 是Printf方法第二个参数
a = int(b) // ^ go 是一门严格的语言,需要进行显式类型转换
fmt.Printf(\"a: %8T %[1]v\\n\", a)
b = float64(a)
fmt.Printf(\"b: %8T %[1]v\\n\", b)
}
求平均值、标准流
package main
import (
\"fmt\"
\"os\"
)
func main() {
var sum float64
var n int
for {
var val float64
if _, err := fmt.Fscanln(os.Stdin, &val); err != nil {
fmt.Println(err)
break
} else {
sum += val
n++
}
}
if n == 0 {
fmt.Fprintln(os.Stderr, \"no values\") // ^ 需要告诉在哪个输出流上打印
os.Exit(-1)
}
fmt.Println(\"The average is\", sum/float64(n)) // ^ go没有自动转换,需要强制转换
}
_, err := fmt.Fscanln(os.Stdin, &val) 用于从标准输入流获取输入的行数据,并进行转换,转换失败会将错误返回给 err,否则 err 为 nil
fmt.Fprintln(os.Stderr, \"no values\") 与 Println 差不多,只是需要告诉在哪个输出流上打印
04-Strings
Strings

字符串在 go 中都是 unicode ,unicode 是一种特殊的技术用于表示国际通用字符。
rune 相当于 wide character,是 int32 的同义词,四个字节足够大,任何 unicode、字符,逻辑字符 可以指向它。
但是为了让程序更高效,我们不想一直用 4 个字节表示每个字符,因为很多程序使用 ascii 字符。
因此有一种称为 utf-8 编码的 unicode 技术,以字节 byte 表示 unicode 的简便方法。
从物理角度上看,strings 就是 unicode 字符的 utf-8 编码。
ascii characters 适合 0-127 的范围
func main() {
s := \"élite\"
fmt.Printf(\"%8T %[1]v %d\\n\", s, len(s))
fmt.Printf(\"%8T %[1]v\\n\", []rune(s))
b := []byte(s)
fmt.Printf(\"%8T %[1]v %d\\n\", b, len(b))
}
string élite 6
[]int32 [233 108 105 116 101]
[]uint8 [195 169 108 105 116 101] 6
é 为 233 超出了 ascii 的表示范围,由 2 个字节表示,而不是为每个字符使用 4 个字节,这是 utf8 编码的效果。中文字经常为 20000 的数字,五个中文字会用 15 个字节表示。
len(s) 显示 6 的原因,在程序中字符串的长度是在 utf-8 中编码字符串所必需的字节字符串的长度
The length of a string in the program is the length of the byte string that\'s necessary to encode the string in utf-8,not the number of unicode characters
就是说给定一个字符串,把它进行 utf-8 编码需要的字节数量就是它的长度,而不是 unicode 字符的数量。
String structure
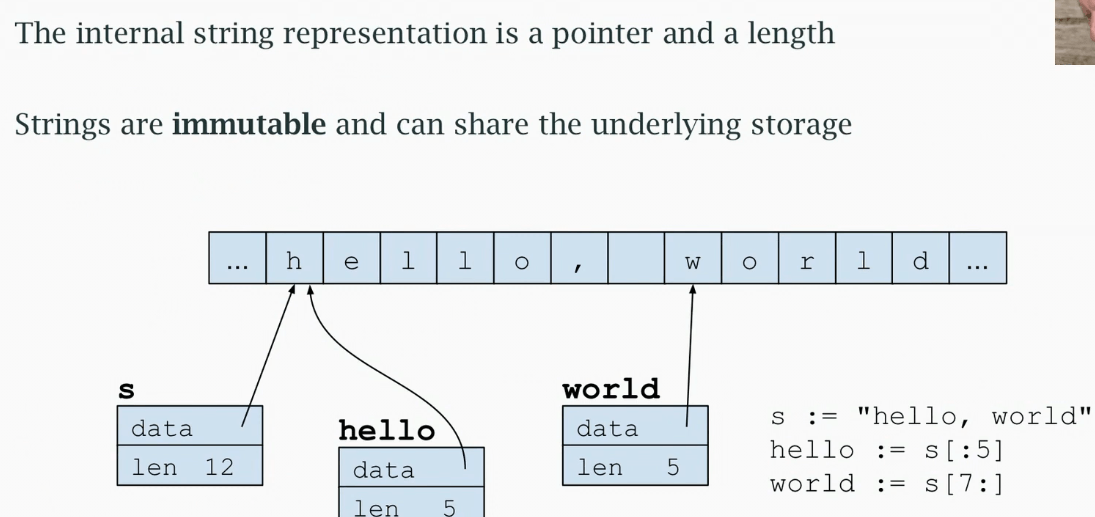
可以把图片左边的 s 理解为一个描述符(描述符不是指针、不是 go 的专业术语),它有指针和额外的信息(字节数)。
go 字符串末尾没有空字节,很多编程语言通过循环字符串判断空字节获取长度,效率并不高。在 go 中字符串长度直接保存在描述符中。
通过索引字符串创建 hello 的时候,hello 的 data 指向的是跟 s 描述符 data 的相同内存地址(共享存储)。
因为字符串没有空字节,而且它们是不可变的,所以共享存储是完全可行的。world 也是同理。它们重用 s 中的内存。
t := s 的结果是 t 将有与 s 一样的内容,但是 t 跟 s 是不一样的描述符。

b、c 与 s 共享存储。
d 开辟了新的内存空间,存入了新的字符串。
s[5] = \'a\' 出错,字符串是不可变的,不能单独修改字符串。
s +=\"es\" 相当于 s = s + \"es\" ,开辟了新的内存空间,复制原有内容,再添加新内容,并使 data 指向新的内存地址。
原来的字符串并没有改变、消失,因为 b、c 依旧指向原来的内存地址,s 指向了新开辟的内存地址。
String functions

s = strings.ToUpper(s) 字符串不允许被更改,所以会创建新字符串进行旧字符串的拷贝并大写。由于开辟了新的内存空间,将返回值给 s 也就很好理解了。
如果没有变量引用字符串,它会自动被垃圾回收。
Practice
做一个替换句子中指定单词的程序
main.go
package main
import (
\"bufio\"
\"fmt\"
\"os\"
\"strings\"
)
func main() {
if len(os.Args) < 3 {
fmt.Fprintln(os.Stderr, \"not enough args\")
os.Exit(-1)
}
old, new := os.Args[1], os.Args[2]
scan := bufio.NewScanner(os.Stdin)
for scan.Scan() {
s := strings.Split(scan.Text(), old)
t := strings.Join(s, new)
fmt.Println(t)
}
}
os.Args 运行 go 程序时附加的参数,具体可以看前几节的内容。
buffio.NewScanner(os.Stdin) 扫描仪是一个缓冲io工具,默认以行分割输入的内容。举个例子,如果输入特别大,就可以把它以一系列行的形式读取。
scan.Scan() 将循环读取行,如果有可用的行读取将会返回true。
scan.Text() 获取读取的行。
for 循环中使用 strings 标准库的 Split 方法根据旧单词 变量 old(大小写敏感)分割字符串获得字符串切片。
再将切片传入 strings 标准库的 Join 方法,通过新单词 变量 new 合并字符串。
test.txt
matt went to greece
where did matt go
alan went to rome
matt didn\'t go there
第一行留空行,因为会读取 BOM 头,具体请看这篇文章
重定向管道流读取TXT文本第一次读取为\"\"空字符串 - 小能日记 - 博客园 (cnblogs.com)
result
cat test.txt | go run . matt ed
ed went to greece
where did ed go
alan went to rome
ed didn\'t go there
这里我们使用了重定向管道,读取 test.txt 的内容当做 main.go 的程序输入,指令在 linux 是 go run . matt ed < test.txt。
old, new := os.Args[1], os.Args[2]
old, new = new, old
值得注意的一点是初始化变量的方式,使用一行初始化两个变量。巧妙的是可以用这种方式进行两个变量值的交换。
05-Arrays, Slices, and Maps
In memory

string、array、slice 在内存中是连续存储的,map不是连续存储的。
Array

在创建数组的时候需要指定大小,如果不指定需要使用 ... ,图中 a、b 将是固定的 24 字节对象(int在64位操作系统上默认为int64),一旦设定不能改变。
d=b 中,由于数组只是一块内存,并不是像字符串那样的描述符,我们只是物理地复制了字节。当数组大小不一致时,无法进行拷贝复制。
Slice

切片有描述符,指向一个特定的内存地址。它的工作方式类似于字符串的工作方式。
切片描述符包含 data、len、capacity。
append 方法需要把返回值重新赋给 a,假设 a 指向的内存区域已经满了,再添加元素就要开辟新的更大的内存区域存放。
a=b 表示 b 描述符的内容被拷贝到 a 描述符中。
e:=a 新建一个描述符,内容与 a 描述符内的一致。
切片可以被切片(截取)操作,就像从字符串(前面的os.Args[1:])中取出切片,从切片数组切片等。
package main
import \"fmt\"
func main() {
t := []byte(\"string\")
fmt.Println(len(t), t)
fmt.Println(t[2])
fmt.Println(t[:2])
fmt.Println(t[2:])
fmt.Println(t[3:5], len(t[3:5]))
}
6 [115 116 114 105 110 103]
114
[115 116]
[114 105 110 103]
[105 110] 2
fence post error

栅栏柱错误:假设我有三个栅栏部分,我必须有四个栅栏在他们旁边将它们固定住。(不懂直接看图)
Compare Array、Slice

切片可以是任意长度,而且大部分 Go 的标准库使用切片作为参数。
切片是不能进行比较的,想进行比较可以使用数组。这也导致切片不能作为 Map Key。
数组可以作为一些算法必备的数组。大小固定,值不改变。近似于伪常量。注意,不能添加 const 常量关键字,只有数字,字符串,布尔值可以作为常量。

Example

a[0]=4 因为 a 只是 w 的值拷贝(数组),所以修改后 w 并没有被修改。
b[0]=3 将会使 x 修改,因为两者 data 都指向同一个内存地址。(但是要注意,这是值拷贝,如果添加元素过多,会导致 b 的 data 指针使用新的内存地址而 x 还是指向原来的)
copy(c, b) 函数不会因为切片大小不同出错,会尽可能把 b 切片中的元素拷贝到 c 中。
我们可以对数组切片如 z := a[0:2] z 将是一个切片,指向 a 的前两个元素,go 会自动提供数组来保存。
Map

假设要计算一个文件中不同单词出现的次数,就可以使用 Maps。是一个 Hash table。
m 是一个描述符,但是整体为空。 p 的 data 指针指向一个哈希表。

map 与 map 间不能进行比较,只能进行 nil 比较。
可以查看 map 的长度,不能查看 map 的容量。

可以通过获取第二个参数判断键值对是否存在。
Built in functions

Make nil useful

由于 len、cap、range 这些内建函数是安全的,我们不需要 if 判断 nil 就可以直接使用。
range 将会跳过 nil、empty 的循环对象。
Quote

一种不影响你思考编程的方式的语言是不值得了解的
Practice
编写一个段落单词计数器,输出前三个出现次数最多的单词。
main.go
package main
import (
\"bufio\"
\"fmt\"
\"os\"
\"sort\"
)
func main() {
scan := bufio.NewScanner(os.Stdin)
words := make(map[string]int)
// ^ 默认是按行读取,所以手动指定按单词读取
scan.Split(bufio.ScanWords)
for scan.Scan() {
words[scan.Text()]++
}
fmt.Println(len(words), \"unique words\")
type kv struct {
key string
val int
}
var ss []kv
for k, v := range words {
ss = append(ss, kv{k, v})
}
// ^ 直接修改原切片
sort.Slice(ss, func(i, j int) bool {
return ss[i].val > ss[j].val
})
for _, s := range ss[:3] {
fmt.Println(s.key, \"appears\", s.val, \"times\")
}
}
scan.Split(bufio.ScanWords) Scanner 默认是按行读取,所以手动指定按单词读取。
kv{k, v} 结构体的初始化
sort.Slice 函数直接修改原切片,传入的函数在 return 前面的元素排在切片的前面。如左>右,则大的元素在切片最前面,属于降序排序。
test.txt
matt went to greece
where did matt go
alan went to rome
matt didn\'t go there
第一行是空行是有原因的,这是 BOM头(Byte Order Mark) 导致的,具体请看另一篇文章
重定向管道流读取TXT文本第一次读取为\"\"空字符串 - 小能日记 - 博客园 (cnblogs.com)
result
cat test.txt | go run .
12 unique words
matt appears 3 times
to appears 2 times
go appears 2 times
06-Control Statements
If-then-else

- 花括号是必须写的,而且有严格的格式
- if 语句内可以写短声明
Loop
for

range array

注意第二种方式 v 是被拷贝的,假设 myArray 是个 4K 大小的数组,那么每次循环时都会进行复制,这种情况下最好采用第一种方式。第一种更加高效,只用索引的方式直接从数组中获取避免了复制。
range map

这两种情况下,循环都会进行很长的时间。
在 c++ 中 map 是基于树形结构的,它又一个隐含的顺序,按字母顺序排列。
在 go 中 map 是无序的,基于哈希表。不同时间迭代映射会得到不同的顺序。如果你需要顺序取出,那你要先取出 keys 然后对其按字母进行排列,再遍历从maps 取出值。
infinite loop

common mistake

labels and loops

例子中可能 returnedData 切片很长,所以匹配到第一个之后应该返回到标签 outer 的外部循环。
需要明确指出 continue outer ,即对应 outer 标签
Switch
switch

switch其实就是 if else 的语法糖。更容易理解,提高可读性。- 可以在
switch后短声明。 - 可以为一个
case添加空的语句段,只判断不执行。 - 不需要添加
break。 - 最好添加
default。
switch on true

cases 可以有逻辑语句,就像一堆 if else,更加方便。
Packages

所有 go 文件必须以 package 开头。
短声明只能在函数中使用,因为在包中应该以关键词开头,这样方便编译器解析。

如果首字母大写,那么就是导出的,否则是私有的。


包依赖应该是一个树形结构,不能循环依赖。

包内的东西将在 main 函数前被初始化,在运行时将会执行包内的 init 函数(在main调用前)。
循环依赖会导致不知道优先初始化哪个的问题。

好的包在一个简单的 api 后面封装了深层复杂的功能
06-Declarations & Types
Declaration


Short declarations

重点讲一下第三条
- 第一行用短声明了
err变量 - 第二行重复声明
err会报错 - 第三行会正确运行,因为声明了新变量
x,而err只是重新赋值

Structural typing

duck typing
在程序设计中,鸭子类型(英语:duck typing)是动态类型的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由\"当前方法和属性的集合\"决定。
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
在鸭子类型中,关注点在于对象的行为,能作什么;而不是关注对象所属的类型。例如,在不使用鸭子类型的语言中,我们可以编写一个函数,它接受一个类型为\"鸭子\"的对象,并调用它的\"走\"和\"叫\"方法。在使用鸭子类型的语言中,这样的一个函数可以接受一个任意类型的对象,并调用它的\"走\"和\"叫\"方法。如果这些需要被调用的方法不存在,那么将引发一个运行时错误。任何拥有这样的正确的\"走\"和\"叫\"方法的对象都可被函数接受的这种行为引出了以上表述,这种决定类型的方式因此得名。


Operator

逻辑运算符只能给布尔值用,其他编程语言可能有 0 == false,但是 go 没有

07-Formatted & File I/O
I/O steams

操作系统具有三个标准 io 流,标准输入、标准输出、标准错误。它们分别可以重定向。
formatted I/O

Println 将参数默认输出到标准输出流,如果会用 Fprintln 可以指定输出到某个流,比如 os.Stderr
fmt functions

Sprintln 格式化字符串并返回。

package main
import \"fmt\"
func main() {
a, b := 12, 345
c, d := 1.2, 3.45
fmt.Printf(\"%d %d\\n\", a, b)
fmt.Printf(\"%x %x\\n\", a, b)
fmt.Printf(\"%#x %#x\\n\", a, b)
fmt.Printf(\"%f %.2f\", c, d)
fmt.Println()
fmt.Printf(\"|%6d|%6d|\\n\", a, b)
fmt.Printf(\"|%-6d|%-6d|\\n\", a, b)
fmt.Printf(\"|%06d|%06d|\\n\", a, b)
fmt.Printf(\"|%9f|%9.2f|\\n\", c, d) // ^ 当数字过大时也会超出
}
12 345
c 159
0xc 0x159
1.200000 3.45
| 12| 345|
|12 |345 |
|000012|000345|
| 1.200000| 3.45|
package main
import (
\"fmt\"
)
func main() {
s := []int{1, 2, 3}
a := [3]rune{\'a\', \'b\', \'c\'}
m := map[string]int{\"and\": 1, \"or\": 2}
ss := \"a string\"
b := []byte(ss)
fmt.Printf(\"%T\\n\", s)
fmt.Printf(\"%v\\n\", s)
fmt.Printf(\"%#v\\n\", s) // ^ %#v 更符合初始化时输入的形式
fmt.Println()
fmt.Printf(\"%T\\n\", a)
fmt.Printf(\"%v\\n\", a)
fmt.Printf(\"%q\\n\", a) // ^ 注意这个%q将rune从int32转化成了字符串
fmt.Printf(\"%#v\\n\", a)
fmt.Println()
fmt.Printf(\"%T\\n\", m)
fmt.Printf(\"%v\\n\", m)
fmt.Printf(\"%#v\\n\", m)
fmt.Println()
fmt.Printf(\"%T\\n\", ss)
fmt.Printf(\"%v\\n\", ss)
fmt.Printf(\"%q\\n\", ss)
fmt.Printf(\"%#v\\n\", ss)
fmt.Printf(\"%v\\n\", b)
fmt.Printf(\"%v\\n\", string(b)) // ^ 将字节切片转换为字符串
}
[]int
[1 2 3]
[]int{1, 2, 3}
[3]int32
[97 98 99]
[\'a\' \'b\' \'c\']
[3]int32{97, 98, 99}
map[string]int
map[and:1 or:2]
map[string]int{\"and\":1, \"or\":2}
string
a string
\"a string\"
\"a string\"
[97 32 115 116 114 105 110 103]
a string
file I/O

Practice ① I/O
编写一个类似 Unix cat 的程序,将多个文件输出到标准输出流中,并输出为一个文件。
package main
import (
\"fmt\"
\"io\"
\"os\"
)
func main() {
for _, fname := range os.Args[1:] {
file, err := os.Open(fname)
if err != nil {
fmt.Fprintln(os.Stderr, err)
continue
}
if _, err := io.Copy(os.Stdout, file); err != nil {
fmt.Fprint(os.Stderr, err)
continue
}
fmt.Fprint(os.Stdout, \"\\n\") // ^ 每个文件内容末尾添加换行符
file.Close()
}
}
io.copy 是一个很棒的功能,它知道如何缓冲、如何以块的形式读入并写会,它不会尝试把整个文件读取到内存中也不会一次读取一个字符。
file.Close 大多数操作系统对程序中打开多少个文件有限制,所以文件使用完成后需要进行关闭。
在当前目录新建 txt 文件,写入内容。执行下面三条命令。
go run . a.txt
go run . a.txt b.txt c.txt
go run . a.txt b.txt c.txt > new.txt
第二条指令结果
[]int{1, 2, 3}
go go go
people car
cat
apple
banana
第三条指令在当前目录生成了 new.txt 文件,内容是 标准输出流 的内容。


Always check the err

Practice ② I/O
编写一个简短的程序计算文件大小。一次性读取(小文件情况下)
我们前面知道, io/ioutil 包可以对整个文件进行读取,存入内存中。我们可以使用它计算文件大小。
原先的 io.Copy 返回的是复制的字节数,而 ReadAll 将返回整个 data ,字节切片和一个err。
package main
import (
\"fmt\"
\"io/ioutil\"
\"os\"
)
func main() {
for _, fname := range os.Args[1:] {
file, err := os.Open(fname)
if err != nil {
fmt.Fprintln(os.Stderr, err)
continue
}
data, err := ioutil.ReadAll(file)
if err != nil {
fmt.Fprint(os.Stderr, err)
continue
}
fmt.Println(\"The file has\", len(data), \"bytes\")
file.Close()
}
}
go run . a.txt b.txt c.txt
The file has 30 bytes
The file has 20 bytes
The file has 18 bytes
data, err := ioutil.ReadAll(file) 从 if 中取出单独成行,是因为需要 data 这个变量。如果放在 if 短声明里会导致作用域只在 if 语句块内。
Practice ③ I/O
编写一个 wc 程序(word counter),输出lines、words、characters数量。使用缓冲 buffio(大文件情况下)
package main
import (
\"bufio\"
\"fmt\"
\"os\"
\"strings\"
)
func main() {
for _, fname := range os.Args[1:] {
var lc, wc, cc int
file, err := os.Open(fname)
if err != nil {
fmt.Fprintln(os.Stderr, err)
continue
}
scan := bufio.NewScanner(file)
for scan.Scan() {
s := scan.Text()
wc += len(strings.Fields(s)) // ^ 根据空格、制表符分割 a slice of words
cc += len(s)
lc++
}
fmt.Printf(\"%7d %7d %7d %s\\n\", lc, wc, cc, fname)
file.Close()
}
}
go run . a.txt b.txt c.txt
3 7 26 a.txt
2 5 18 b.txt
3 3 14 c.txt
bufio.NewScanner(file) 创建一个扫描器按行扫描。考虑到多行需要用 for 循环 scan.Scan。
strings.Fields(s) 根据空格、制表符分割,拿到的是字符串切片。
08-Functions, Parameters
functions
first class


你可以在函数体内声明函数,但必须是匿名函数,作为一个变量。
function signatures

函数签名指的是 函数参数类型与排列顺序、函数返回值
parameter


pass by value
func do(b [3]int) int {
b[0] = 0
return b[1]
}
func main() {
a := [3]int{1, 2, 3}
v := do(a) // ^ 数组被复制到函数的局部变量
fmt.Println(a, v)
}
[1 2 3] 2
pass by reference
func do(b []int) int {
b[0] = 0
fmt.Printf(\"b2 @ %p\\n\", b)
b = append(b, 100)
b = append(b, 100)
fmt.Printf(\"b3 @ %p\\n\", b)
return b[1]
}
func main() {
a := []int{1, 2, 3}
fmt.Printf(\"b1 @ %p\\n\", a)
v := do(a) // ^ 切片被复制到函数的局部变量
fmt.Println(a, v)
}
b1 @ 0xc00012c078
b2 @ 0xc00012c078
b3 @ 0xc00013e060
[0 2 3] 2
func do(m1 map[int]int) {
m1[3] = 0 // ^ 两个描述符和相同的哈希表,且哈希表有三个键,因此修改m1,m被修改
m1 = make(map[int]int) // ^ 分配了新映射,但m不会被改变
m1[4] = 4
fmt.Println(\"m1\", m1)
}
func main() {
m := map[int]int{4: 1, 7: 2, 8: 3}
do(m)
fmt.Println(m)
}
m1 map[4:4]
map[3:0 4:1 7:2 8:3]
the ultimate truth

go 里只有值传递,函数内的变量都是局部变量,它被分配、拷贝实际参数的值,假如传入的是切片描述符,它也是被复制到局部变量里的。描述符被复制,切片底层数据没有被复制。
returns

Recursion

递归运行比迭代慢因为要创建一系列堆栈帧。
08-Defer


defer gotcha #1


Defer is based on function scope
第二个例子中,只有退出函数才会执行 defer 将会打开很多文件导致程序崩溃。所以直接使用 f.close 关闭文件。
defer gotcha #2

defer 执行时,以参数实际的值拷贝传递进延迟函数并压入 defer栈 中,而不是引用。

当我离开函数时执行延迟堆栈,延迟的匿名函数修改返回值 a
09-Closures

变量的生命周期可以超过变量声明上下文的范围


左侧 f 只是函数指针,右侧 f 则是闭包。注意右上角标红的 &,闭包是引用封闭的,拿到a、b变量的引用而不是单纯的值。

Slice 需要一个特定的闭包签名函数。在闭包的上下文中,我唯一传递给我的闭包是 i、j 他们是整数,ss 也是这个函数的一部分虽然没有被明确传入。
package main
import \"fmt\"
func do(d func()) {
d()
}
func main() {
for i := 0; i < 4; i++ {
v := func() {
fmt.Printf(\"%d @ %p\\n\", i, &i)
}
do(v)
}
}
0 @ 0xc000016088
1 @ 0xc000016088
2 @ 0xc000016088
3 @ 0xc000016088
package main
import \"fmt\"
func main() {
s := make([]func(), 4)
for i := 0; i < 4; i++ {
s[i] = func() {
fmt.Printf(\"%d @ %p\\n\", i, &i)
}
}
for i := 0; i < 4; i++ {
s[i]()
}
}
4 @ 0xc000016088
4 @ 0xc000016088
4 @ 0xc000016088
4 @ 0xc000016088
当封闭 i 变量时,每个闭包需要一个引用。四个匿名函数引用的都是同一个 i ,在第一个循环退出后,i 值为 4。i 并没有被垃圾回收,因为它仍被 4 个匿名闭包函数所引用。每次打印都是 4
比如传入一个闭包函数作为回调函数的时候,所引用的值在回调执行前会发生改变,那会出现大问题。
在第一个循环内创建一个新变量,每次循环声明初始化一个新变量,每个闭包函数会引用这个新变量,每个 i2 地址不一样。
for i := 0; i < 4; i++ {
i2 := i // closure capture
s[i] = func() {
fmt.Printf(\"%d @ %p\\n\", i, &i)
}
闭包是一种函数,调用具有来自函数外部的附加数据。例如数据来自另一个函数的范围,并且它通过引用封闭(封盖)。被封闭参数有点像参数,但它并不是,它允许我们函数使用那些不能用参数传递的额外数据,例如有些被其他类型固定的数据而无法被传递的数据。我们需要注意 gotcha ,因为闭包通过引用封闭,如果闭包是异步执行的,那么我封闭(封盖)的变量可能会发生改变。正如前面的例子,修复方法就是创建一个对应的本地副本,让闭包函数关闭(封盖)本地副本,这样副本的值就固定了。
10-Slices in Detail
Slice
package main
import \"fmt\"
func main() {
var s []int
t := []int{}
u := make([]int, 5)
v := make([]int, 0, 5)
fmt.Printf(\"%d, %d, %T, %5t %#[3]v\\n\", len(s), cap(s), s, s == nil)
fmt.Printf(\"%d, %d, %T, %5t %#[3]v\\n\", len(t), cap(t), t, t == nil)
fmt.Printf(\"%d, %d, %T, %5t %#[3]v\\n\", len(u), cap(u), u, u == nil)
fmt.Printf(\"%d, %d, %T, %5t %#[3]v\\n\", len(v), cap(v), v, v == nil)
}
0, 0, []int, true []int(nil)
0, 0, []int, false []int{}
5, 5, []int, false []int{0, 0, 0, 0, 0}
0, 5, []int, false []int{}

\\(t\\) 中的 \\(addr\\) 指向一个起哨兵作用的结构,所以我们知道它是空的而不是 \\(nil\\).
可以用 append 方法生成元素存储地址,并返回一个描述符引用这个存储给 \\(s\\) . 即便 \\(s\\) 为 \\(nil\\)
Empty vs nil slice

使用 \\(nil\\) 、\\(empty\\) 映射替换切片在这个例子中分别是 null、{ } 。
判断切片是否为空不能使用 a == nil ,因为有 \\(nil\\)、\\(empty\\) 两种情况,应该用 len(a) 进行判断。
最好make切片的时候给定 length,否则新建同长度容量的切片用append会将元素追加在一堆0的后面。
Important
package main
import \"fmt\"
func main() {
a := [3]int{1, 2, 3}
b := a[:1]
fmt.Println(\"a = \", a)
fmt.Println(\"b = \", b)
c := b[0:2]
fmt.Println(\"c = \", c)
fmt.Println(len(b))
fmt.Println(cap(b))
fmt.Println(len(c))
fmt.Println(cap(c))
d := a[0:1:1]
// e := d[0:2]
fmt.Println(\"d = \", d)
// fmt.Println(\"e = \", e) Error
fmt.Println(len(d))
fmt.Println(cap(d))
}
a = [1 2 3]
b = [1]
c = [1 2]
1
3
2
3
d = [1]
1
2
对截取的切片再次进行切片是根据原先的底层数组来的。
如果你使用两个索引切片符,你得到的切片的容量等于底层数组的容量。
package main
import \"fmt\"
func main() {
a := [3]int{1, 2, 3}
b := a[:1]
// c := b[0:2]
c := b[0:2:2]
fmt.Printf(\"a[%p] = %v\\n\", &a, a)
fmt.Printf(\"b[%p] = %v\\n\", b, b)
fmt.Printf(\"c[%p] = %v\\n\", c, c)
c = append(c, 5)
fmt.Printf(\"a[%p] = %v\\n\", &a, a)
fmt.Printf(\"c[%p] = %v\\n\", c, c)
c[0] = 9
fmt.Printf(\"a[%p] = %v\\n\", &a, a)
fmt.Printf(\"c[%p] = %v\\n\", c, c)
}
a[0xc000010150] = [1 2 3]
b[0xc000010150] = [1]
c[0xc000010150] = [1 2]
a[0xc000010150] = [1 2 3]
c[0xc00000e2a0] = [1 2 5]
a[0xc000010150] = [1 2 3]
c[0xc00000e2a0] = [9 2 5]
\\(a\\) 是一个数组,\\(b、c\\) 是两个切片,它们指向 \\(a\\)。
-
对 \\(c\\) 添加元素,会发现 \\(a、c\\) 被改变。\\(c\\) 的容量为 \\(3\\),长度为 \\(2\\),对 \\(c\\) 添加元素的时候把 \\(a\\) 修改了,覆盖 \\(a\\) 的第三个值。
-
对 \\(c\\) 限制容量数量,再添加元素会导致没有地方放置,所以会重新分配一块容量更大的内存区域,拷贝原先的元素,再把新加的元素放进去,底层数组地址发生改变。
去掉 \\(a\\),将 \\(b\\) 声明为切片并初始化,\\(b\\) 描述符指向无命名的底层数组。用 \\(c\\) 对其切片,并添加元素,结果和上面是一样的。切片实际上是一些底层数组的别名。
11-Homework #2

package main
import (
\"bytes\"
\"fmt\"
\"os\"
\"strings\"
\"golang.org/x/net/html\"
)
var raw = `
<!DOCTYPE html>
<html>
<body>
<h1>My First Heading</h1>
<p>My first paragraph.</p>
<p>HTML <a href=\"https://www.w3schools.com/html/html_images.asp\">images</a> are defined with the img tag:</p>
<img src=\"xxx.jpg\" width=\"104\" height=\"142\">
</body>
</html>
`
func visit(n *html.Node, words, pics *int) {
if n.Type == html.TextNode {
*words += len(strings.Fields(n.Data))
} else if n.Type == html.ElementNode && n.Data == \"img\" {
*pics++
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
visit(c, words, pics)
}
}
func countWordsAndImages(doc *html.Node) (int, int) {
var words, pics int
visit(doc, &words, &pics)
return words, pics
}
func main() {
doc, err := html.Parse(bytes.NewReader([]byte(raw)))
if err != nil {
fmt.Fprintf(os.Stderr, \"parse failed:%s\\n\", err)
os.Exit(-1)
}
words, pics := countWordsAndImages(doc)
fmt.Printf(\"%d words and %d images\\n\", words, pics)
}
14 words and 1 images
假如我去访问一个网站,我会得到一个字节的片段,将它放到阅读器中。
doc, err := html.Parse(bytes.NewReader([]byte(raw)))
返回的\\(doc\\)是树节点,我们可以用 \\(for\\) 循环通过节点的 \\(FirstChild、NextSibling\\) 属性遍历整棵树。
11-Reader
Reader interface
上文出现了阅读器这个概念,我感到很模糊,于是查找相关资料进行学习。
type Reader interface {
Read(p []byte) (n int ,err error)
}
官方文档中关于该接口方法的说明
Read 将 len(p) 个字节读取到 p 中。它返回读取的字节数 n(0 <= n <= len(p)) 以及任何遇到的错误。即使 Read 返回的 n < len(p),它也会在调用过程中使用 p 的全部作为暂存空间。若一些数据可用但不到 len(p) 个字节,Read 会照例返回可用的数据,而不是等待更多数据。
Read 在成功读取 n > 0 个字节后遇到一个错误或
EOF (end-of-file),它就会返回读取的字节数。它会从相同的调用中返回(非nil的)错误或从随后的调用中返回错误(同时 n == 0)。 一般情况的一个例子就是 Reader 在输入流结束时会返回一个非零的字节数,同时返回的err不是EOF就是nil。无论如何,下一个 Read 都应当返回0, EOF。
调用者应当总在考虑到错误 err 前处理 n > 0 的字节。这样做可以在读取一些字节,以及允许的 EOF 行为后正确地处理 I/O 错误
PS: 当Read方法返回错误时,不代表没有读取到任何数据,可能是数据被读完了时返回的io.EOF。
Reader 接口的方法集(Method_sets)只包含一个 Read 方法,因此,所有实现了 Read 方法的类型都实现了io.Reader 接口,也就是说,在所有需要 io.Reader 的地方,可以传递实现了 Read()方法的类型的实例。
NewReader func
Reader Struct
NewReader创建一个从s读取数据的Reader
type Reader struct {
s string //对应的字符串
i int64 // 当前读取到的位置
prevRune int
}
Len 、Size,Read func
Len作用: 返回未读的字符串长度
Size的作用:返回字符串的长度
read的作用: 读取字符串信息
r := strings.NewReader(\"abcdefghijklmn\")
fmt.Println(r.Len()) // 输出14 初始时,未读长度等于字符串长度
var buf []byte
buf = make([]byte, 5)
readLen, err := r.Read(buf)
fmt.Println(\"读取到的长度:\", readLen) //读取到的长度5
if err != nil {
fmt.Println(\"错误:\", err)
}
fmt.Println(buf) //adcde
fmt.Println(r.Len()) //9 读取到了5个 剩余未读是14-5
fmt.Println(r.Size()) //14 字符串的长度
Practice
任何实现了 Read() 函数的对象都可以作为 Reader 来使用。
围绕io.Reader/Writer,有几个常用的实现

net.Conn,os.Stdin,os.File: 网络、标准输入输出、文件的流读取strings.Reader: 把字符串抽象成Readerbytes.Reader: 把[]byte抽象成Readerbytes.Buffer: 把[]byte抽象成Reader和Writerbufio.Reader/Writer: 抽象成带缓冲的流读取(比如按行读写)
我们编写一个通用的阅读器至标准输出流方法,并分别传入对象 \\(os.File、net.Conn、strings.Reader\\)
func readerToStdout(r io.Reader, bufSize int) {
buf := make([]byte, bufSize)
for {
n, err := r.Read(buf)
if err == io.EOF {
break
}
if err != nil {
fmt.Println(err)
break
}
if n > 0 {
fmt.Println(string(buf[:n]))
}
}
}
在\\(readerToStdout\\) 方法中,我们传入实现了 \\(io.Reader\\) 接口的对象,并规定一个每次读取数据的缓冲字节切片的大小。
需要注意的是,由于是分段读取,需要使用 \\(for\\) 循环,通过判断 \\(io.EOF\\) 退出循环,同时还需要考虑其他错误。输出至 \\(os.Stdin\\) 标准流时需要对字节切片进行字符串类型转换,同时字节切片应该被索引截取。\\(n\\)是本次读取到的字节数。
如果输出时切片不被索引截取会出现什么情况。
func fileReader() {
f, err := os.Open(\"book.txt\")
if err != nil {
panic(err)
}
defer f.Close()
buf := make([]byte, 3)
for {
n, err := f.Read(buf)
if err == io.EOF {
break
}
if err != nil {
fmt.Println(err)
break
}
if n > 0 {
fmt.Println(buf)
}
}
}
book.txt 内容为 abcd
[97 98 99]
[100 98 99]
第一次循环缓冲切片被正常填满,而第二次由于还剩一个字节,便将这一个字节读入缓冲切片中,而后面元素未被改变。假定文件字节数很小,缓冲切片很大,那么第一次就可以读取完成,这会导致输出字节数组后面的 \\(0\\) 或一些奇怪的内容。
func connReader() {
conn, err := net.Dial(\"tcp\", \"example.com:80\")
if err != nil {
panic(err)
}
defer conn.Close()
fmt.Fprint(conn, \"GET /index.html HTTP/1.0\\r\\n\\r\\n\")
readerToStdout(conn, 20)
}
这里我们通过 \\(net.Dial\\) 方法创建一个 \\(tcp\\) 连接,同时我们需要使用 \\(fmt.Fprint\\) 方法给特定连接发送请求。\\(conn\\) 实现了 \\(io.Reader\\) 接口,可以传入 \\(readerToStdout\\) 方法。
func stringsReader() {
s := strings.NewReader(\"very short but interesting string\")
readerToStdout(s, 5)
}
func fileReader() {
f, err := os.Open(\"book.txt\")
if err != nil {
panic(err)
}
defer f.Close()
readerToStdout(f, 3)
}
我们给定 \\(string\\) 对象来构造 \\(strings.Reader\\),并传入 \\(readerToStdout\\) 方法。我们使用 \\(os.Open\\) 打开文件,所得到的 \\(File\\) 对象也实现了 \\(os.Reader\\) 接口。
12-Structs, Struct tags & JSON
Struct
结构通常是不同类型的聚合,所以有不同类型的字段,通过字段查找值。
type Employee struct {
Name string
Number int
Boss *Employee
Hired time.Time
}
func main() {
var e Employee
fmt.Printf(\"%T %+[1]v\", e)
}
main.Employee {Name: Number:0 Boss:<nil> Hired:0001-01-01 00:00:00 +0000 UTC}
通过 \\(\\%+v\\) 显示结构体的字段。通过点表示法插入值。另外的声明方法
var e2 = Employee{
\"Matt\",
1,
nil,
time.Now(),
}
这种需要按顺序填写所有字段。我们可以指定字段名就可以只写部分
var e2 = Employee{
Name: \"Matt\",
Number: 1,
Hired: time.Now(),
}
boss := Employee{\"Lamine\", 2, nil, time.Now()}
e2.Boss = &boss
fmt.Printf(\"%T %+[1]v\\n\", e2)
main.Employee {Name:Matt Number:1 Boss:0xc00005e100 Hired:2022-04-08 07:40:49.042803 +0800 CST m=+0.006431301}
由于 \\(Boss\\) 是指针,在 \\(e2\\) 的输出中显示的是指针。上方代码也可以写成
boss := &Employee{\"Lamine\", 2, nil, time.Now()}
e2.Boss = boss
使 \\(boss\\) 指向结构体指针,在某种意义上创建结构体,匿名获取指针。
使用 \\(map\\) 管理所有 \\(Employee\\) 对象
c := map[string]*Employee{}
// c := make(map[string]*Employee)
c[\"Lamine\"] = &Employee{\"Lamine\", 2, nil, time.Now()}
c[\"Matt\"] = &Employee{
Name: \"Matt\",
Number: 1,
Boss: c[\"Lamine\"],
Hired: time.Now(),
}
fmt.Printf(\"%T %+[1]v\\n\", c[\"Lamine\"])
fmt.Printf(\"%T %+[1]v\\n\", c[\"Matt\"])
*main.Employee &{Name:Lamine Number:2 Boss:<nil> Hired:2022-04-08 07:51:11.8676147 +0800 CST m=+0.004987001}
*main.Employee &{Name:Matt Number:1 Boss:0xc00005e040 Hired:2022-04-08 07:51:11.8676147 +0800 CST m=+0.004987001}
Struct Gotcha
c := map[string]Employee{}
c[\"Lamine\"] = Employee{\"Lamine\", 2, nil, time.Now()}
c[\"Matt\"] = Employee{
Name: \"Matt\",
Number: 1,
Boss: &c[\"Lamine\"],
Hired: time.Now(),
}
fmt.Printf(\"%T %+[1]v\\n\", c[\"Lamine\"])
fmt.Printf(\"%T %+[1]v\\n\", c[\"Matt\"])
修改 \\(map\\) 存储对象,从结构体指针变为结构体,而 \\(Employee\\) 内的 \\(Boss\\) 字段需要一个指针,在这种情况下,假设我们从映射中获取对象,并得到其指针,那么 \\(IDE\\) 会报错。
invalid operation: cannot take address of c[\"Lamine\"]
映射有限制,你不能获取映射内实体的地址。原因在于每当操作地图的时候,如果我将某些内容插入地图或从地图中删除某些内容,地图可以在内部重新排列,因为哈希表数据结构是动态的,那样获得的地址是非常不安全的,可能会变成过时的指针。
c[\"Lamine\"] = Employee{\"Lamine\", 2, nil, time.Now()}
c[\"Lamine\"].Number++
cannot assign to struct field c[\"Lamine\"].Number in map
如果有一张结构体的映射,对映射中一个该结构体中的值进行修改是不可能的。必须要将结构体的映射修改为结构体指针的映射。
Anonymous Struct Type
func main() {
var album = struct {
title string
artist string
year int
copies int
}{
\"The White Album\",
\"The Beatles\",
1968,
1000000000,
}
var pAlbum *struct {
title string
artist string
year int
copies int
}
fmt.Println(album, pAlbum)
}
基于匿名结构类型,并用结构文字初始化,但并不是特别方便。比如创建一个空的匿名结构体指针的时候。
var album1 = struct {
title string
}{
\"The White Album\",
}
var album2 = struct {
title string
}{
\"The Black Album\",
}
album1 = album2
fmt.Println(album1, album2)
可以执行这种赋值操作,将拷贝 \\(album2\\) 的副本复制给 \\(album1\\) ,两个匿名结构体具有相同的结构和行为(有相同的字段和字段类型)
type album1 struct {
title string
}
type album2 struct {
title string
}
func main() {
var a1 = album1{
\"The White Album\",
}
var a2 = album2{
\"The Black Album\",
}
a1 = a2
// a1 = album1(a2)
fmt.Println(a1, a2)
}
而在这种情况下会报错,因为他们不是同一个类型名,但是他们是可以互相转换的。
cannot use a2 (variable of type album2) as album1 value in assignment

判断结构体一致的条件
- 字段一样,字段类型也一样
- 字段按顺序排列
- 相同的字段标签

红圈用于包含一些如何以各种方式进行编码的信息协议。比如为 \\(json\\) 创建 \\(key\\),当我们查看 \\(json\\) 的工作原理时它将使用反射。

但如果它们是一致的,可以进行强制转换。

需要注意的是,从 \\(go\\ 1.8\\) 起,不同字段标签不阻碍类型转换。

Make the zero value useful

\\(nil\\ [\\ ]byte\\) 可以使用 \\(append\\),当 \\(buffer\\) 被创建时就可以直接被使用,不需要做什么前置工作。
Empty structs

\\(struct\\{\\}\\) 在内存中作为单例对象存在,构建空结构体集合比布尔值集合更省空间。
JSON
type Response struct {
Page int `json:\"page\"`
Words []string `json:\"words,omitempty\"`
}
func main() {
r := Response{
Page: 1,
Words: []string{\"up\", \"in\", \"out\"},
}
j, _ := json.Marshal(r)
fmt.Println(string(j))
fmt.Printf(\"%#v\\n\", r)
var r2 Response
_ = json.Unmarshal(j, &r2)
fmt.Printf(\"%#v\\n\", r2)
r3 := Response{
Page: 100,
}
j3, _ := json.Marshal(r3)
fmt.Println(string(j3))
fmt.Printf(\"%#v\\n\", r3)
}
\\(json.Marshal()\\) 返回字节切片,输出到控制台需要转换成 \\(string\\)。\\(json.Unmarshal\\) 需要提供一个结构体指针用于存放解析的数据。\\(omitempty\\) 关键词用于判空,如果为空就省去。否则转换为 \\(json\\) 的时候会给该字段默认加 \\(null\\) 值。
字段都以大写开头,这样它们可以被导出。如果字段名以小写开头,\\(json\\) 不会对它进行编码。
struct field words has json tag but is not exported
从编译器来看程序是正确的,而从 \\(linting\\ tool\\) 静态分析工具来看会给出一个警告。

正则表达式参考资料
Syntax · google/re2 Wiki (github.com)
13-Regular Expressions
Simple string searches

func main() {
test := \"Here is $1 which is $2!\"
test = strings.ReplaceAll(test, \"$1\", \"honey\")
test = strings.ReplaceAll(test, \"$2\", \"tasty\")
fmt.Println(test)
}
Here is honey which is tasty!
使用 \\(strings\\) 包进行简单搜索,对于复杂搜索和验证,谨慎使用 \\(regexp\\) 。
Location by regex
func main() {
te := \"aba abba abbba\"
re := regexp.MustCompile(`b+`)
mm := re.FindAllString(te, -1)
id := re.FindAllStringIndex(te, -1)
fmt.Println(mm)
fmt.Println(id)
for _, d := range id {
fmt.Println(te[d[0]:d[1]])
}
up := re.ReplaceAllStringFunc(te, strings.ToUpper)
fmt.Println(up)
}
[b bb bbb]
[[1 2] [5 7] [10 13]]
b
bb
bbb
aBa aBBa aBBBa
FindAllString(te, -1) 返回匹配的字符串切片。
FindAllStringIndex(te, -1) 返回匹配的字符串位置,是切片的切片。
UUID validation


var uu = regexp.MustCompile(`^[[:xdigit:]]{8}-[[:xdigit:]]{4}-[1-5][[:xdigit:]]{3}-[89abAB][[:xdigit:]]{3}-[[:xdigit:]]{12}$`)
var test = []string{
\"072664ee-a034-4cc3-a2e8-9f1822c43bbb\",
\"072664ee-a034-4cc3-a2e8-9f1822c43bbbb\", // ^ 如果不加 ^ $ 匹配了前面的且忽略了后面的b
\"072664ee-a034-6cc3-a2e8-9f1822c43bbbb\",
\"072664ee-a034-4cc3-C2e8-9f1822c43bbb\",
}
func main() {
for i, t := range test {
if !uu.MatchString(t) {
fmt.Println(i, t, \"\\tfails\")
}
}
}
1 072664ee-a034-4cc3-a2e8-9f1822c43bbbb fails
2 072664ee-a034-6cc3-a2e8-9f1822c43bbbb fails
3 072664ee-a034-4cc3-C2e8-9f1822c43bbb fails
Capture groups
var ph = regexp.MustCompile(`\\(([[:digit:]]{3})\\) ([[:digit:]]{3})-([[:digit:]]{4})`)
func main() {
orig := \"(214) 514-9548\"
match := ph.FindStringSubmatch(orig)
fmt.Printf(\"%q\\n\", match)
if len(match) > 3 {
fmt.Printf(\"+1 %s-%s-%s\\n\", match[1], match[2], match[3])
}
}
[\"(214) 514-9548\" \"214\" \"514\" \"9548\"]
+1 214-514-9548

URL re

(?::([0-9]+))? 末尾的问号确定圆括号内的内容可以出现零次或一次。
?: 表示不被捕获,即整个括号内容匹配了也不添加到返回的切片里。
但内部又有一个捕获组 ([0-9]+) 匹配出现一次或多次的数字,将被捕获到字符串放入返回的切片中。
所以 :([0-9]+) 这一整个不会出现在切片中,而 ([0-9]+) 会出现在切片中。


FindStringSubmatch 只会匹配最后一个,使用FindAllStringSubmatch返回全部匹配,切片的切片。
14-Reference & Value Semantics
Pointers vs Values


如果要共享变量并修改,建议统一用指针传递的方式,否则 \\(f3\\) 返回的是原来的副本,\\(f4\\) 作出的修改将无法反映到 \\(f1\\)、\\(f2\\) 修改的对象上。即针对一个对象的修改却产生了两个对象。

Loop Gotcha

循环内第二个参数拿到的是副本,要在循环内修改原切片字段的值不能直接修改副本,需要通过索引进行修改。

在函数内修改切片最好将切片返回,因为修改切片很可能会导致切片描述符指向的底层数组地址发生改变,比如 \\(grow\\) 扩容。

将指针指向切片内的元素是极其危险的。当切片描述符指向的底层数组扩容时,会导致指针指向已经过时的底层数组。再通过指针修改元素会导致修改无效。
package main
import \"fmt\"
func main() {
items := [][2]byte{{1, 2}, {3, 4}, {5, 6}}
a := [][]byte{}
for _, item := range items {
a = append(a, item[:])
}
fmt.Println(items)
fmt.Println(a)
}
[[1 2] [3 4] [5 6]]
[[5 6] [5 6] [5 6]]
因为 \\(item\\) 是切片元素的副本,所以是两字节数组,在内存中有特定位置,每次循环获得到的副本都在内存的同一个地方。当循环结束后,最后两个字节数组是 \\(5、6\\) ,而向 \\(a\\) 添加的是三个相同的 \\(item\\) 引用,所以都将引用 \\(item\\) 的最终值。修复这种方法的方法是在每次循环内部声明一个新变量。
func main() {
items := [][2]byte{{1, 2}, {3, 4}, {5, 6}}
a := [][]byte{}
for _, item := range items {
i := make([]byte, len(item))
copy(i, item[:])
a = append(a, i)
}
fmt.Println(items)
fmt.Println(a)
}
[[1 2] [3 4] [5 6]]
[[1 2] [3 4] [5 6]]
如果给定 \\(i\\) 的 \\(length\\) 为 \\(0\\),会导致 \\(copy\\) 无法工作。所以必须给定长度。

不要引用用于循环的变量。在循环内部声明新变量将其特殊化。

来源:https://www.cnblogs.com/linxiaoxu/p/16288021.html
本站部分图文来源于网络,如有侵权请联系删除。