 百木园
百木园scrapy爬虫框架
目录
- scrapy爬虫框架
- 简介
- scrapy爬虫框架入门简介
- 网页爬虫代码
简介
通过实战快速入门scrapy爬虫框架
scrapy爬虫框架入门简介
下载scrapy
pip install scrapy
创建项目
scrapy startproject spiderTest1
创建爬虫
cd .\\spiderTest1
scrapy genspider douban movie.douban.com
将项目拖入pycharm
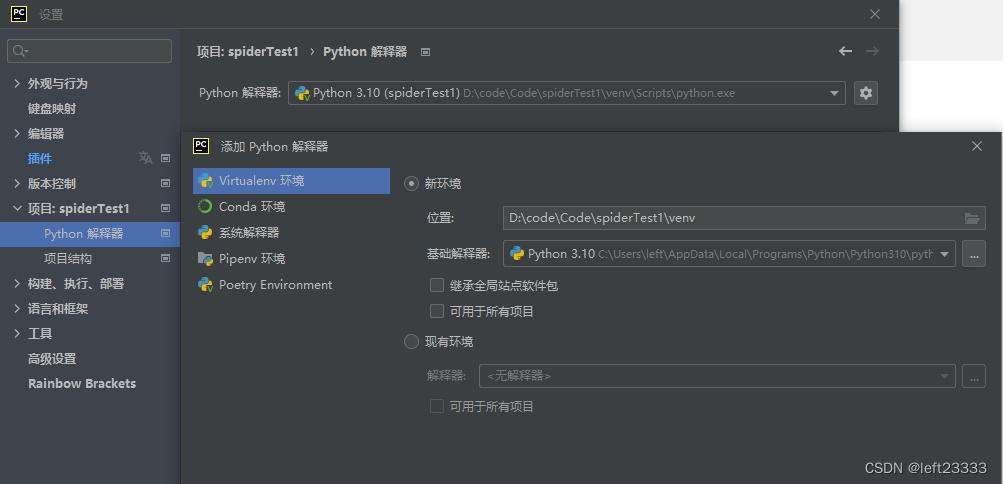
添加虚拟环境(python每一个项目都应当有专属的虚拟环境)
设置->项目->python解释器
不建议使用全局的python解释器
点齿轮->点添加,将虚拟环境放在项目路径下起名venv
项目目录

在虚拟环境中,再次安装scrapy 三方库
设置settings.py文件
# 设置请求头,伪装成浏览器
USER_AGENT = \'Mozilla/5.0(Macintosh;intel Mac OS X 10_14_6)AppleWebKit/537.36(KHTML,like Gecko)Chrome/92.0.4515.159 Safari/537.36\'
ROBOTSTXT_OBEY = True # 是否遵守爬虫协议
CONCURRENT_REQUESTS = 2 # 设置并发
DOWNLOAD_DELAY = 2 # 下载延迟
RANDOMIZE_DOWNLOAD_DELAY = True #随机延迟
# 当有多个管道,数字大的先执行,数字小的后执行
ITEM_PIPELINES = {
\'spiderTest1.pipelines.ExcelPipeline\': 300,
\'spiderTest1.pipelines.AccessPipeline\': 200,
}
运行爬虫
scrapy crawl spiderName --nolog # --nolog不显示日志
scrapy crawl spiderName -o Nmae.csv # 保存为csv格式
python往excel写数据,三方库
pip install openpyxl
查看已经安装了那些库
pip list
pip freeze # 依赖清单
将依赖清单输出requirements.txt保存
# >输出重定向
pip freeze > requirements.txt
按依赖清单装依赖项
pip install -r requirements.txt
网页爬虫代码
douban.py
import scrapy
from scrapy import Selector, Request
from scrapy.http import HtmlResponse
from spiderTest1.items import movieItem
class DoubanSpider(scrapy.Spider):
name = \'douban\'
allowed_domains = [\'movie.douban.com\']
start_urls = [\'https://movie.douban.com/top250\']
def start_requests(self):
for page in range(10):
# f格式化
yield Request(url=f\'https://movie.douban.com/top250?start={page * 25}&filter=\')
def parse(self, response: HtmlResponse, **kwargs):
sel = Selector(response)
list_items = sel.css(\'#content > div > div.article > ol > li\')
for list_item in list_items:
movie_item = movieItem()
movie_item[\'title\'] = list_item.css(\'span.title::text\').extract_first()
movie_item[\'rank\'] = list_item.css(\'span.rating_num::text\').extract_first()
movie_item[\'subject\'] = list_item.css(\'span.inq::text\').extract_first()
yield movie_item
# 找到超链接爬取url
# hrefs_list = sel.css(\'div.paginator > a::attr(href)\')
# for href in hrefs_list:
# url = response.urljoin(href.extract())
# yield Request(url=url)
在管道文件将数据库写入excel,数据库等
piplines.py
import openpyxl
# import pymysql
import pyodbc
# 写入access数据库
class AccessPipeline:
def __init__(self):
# 链接数据库
db_file = r\"E:\\left\\Documents\\spider.accdb\" # 数据库文件
self.conn = pyodbc.connect(
r\"Driver={Microsoft access Driver (*.mdb, *.accdb)};DBQ=\" + db_file + \";Uid=;Pwd=;charset=\'utf-8\';\")
# 创建游标
self.cursor = self.conn.cursor()
# 将数据放入容器进行批处理操作
self.data = []
def close_spider(self, spider):
self._write_to_db()
self.conn.close()
def _write_to_db(self):
sql = r\"insert into tb_top_movie (title, rating, subject) values (%s, %s, %s)\"
if len(self.data) > 0:
self.cursor.executemany(sql, self.data)
self.conn.commit()
# 清空原列表中的数据
self.data.clear()
# 回调函数 -->callback
def process_item(self, item, spider):
title = item.get(\'title\', \'\')
rank = item.get(\'rank\', \'\')
subject = item.get(\'subject\', \'\')
# 单条数据插入,效率较低
# sql = \"insert into [tb_top_movie] (title, rating, subject) values(\'\"+title+\"\',\'\"+rank+\"\',\'\"+subject+\"\')\"
# self.cursor.execute(sql)
# 批处理插入数据
self.data.append((title, rank, subject))
if len(self.data) == 50:
self._write_to_db()
return item
# 写入Excel
class ExcelPipeline:
def __init__(self):
self.wb = openpyxl.Workbook() # 工作簿
self.ws = self.wb.active # 工资表
self.ws.title = \'Top250\'
self.ws.append((\'标题\', \'评分\', \'主题\'))
def close_spider(self, spider):
self.wb.save(\'电影数据.xlsx\')
# 回调函数 -->callback
def process_item(self, item, spider):
title = item.get(\'title\', \'\')
rank = item.get(\'rank\', \'\')
subject = item.get(\'subject\', \'\')
self.ws.append((title, rank, subject))
return item
# 写入mysql
# class DBPipeline:
# def __init__(self):
# # 链接数据库
# self.conn = pymysql.connect(host=\'localhost\', port=9555,
# user=\'left\', passwd=\'123\',
# database=\'spider\', charset=\'utf8mb4\')
# # 创建游标
# self.cursor = self.conn.cursor()
#
# def close_spider(self, spider):
# self.conn.commit()
# self.conn.close()
#
# # 回调函数 -->callback
# def process_item(self, item, spider):
# title = item.get(\'title\', \'\')
# rank = item.get(\'rank\', \'\')
# subject = item.get(\'subject\', \'\')
# self.cursor.execute(
# \'insert into tb_top_movie (title, rating, subject) value(%s,%s,%s)\',
# (title, rank, subject)
# )
# return item
来源:https://www.cnblogs.com/left23333/p/16367744.html
本站部分图文来源于网络,如有侵权请联系删除。