 百木园
百木园1. ArrayList 了解过吗?它是啥?有啥用?
众所周知,Java 集合框架拥有两大接口 Collection 和 Map,其中,Collection 麾下三生子 List、Set 和 Queue。ArrayList 就实现了 List 接口,其实就是一个数组列表,不过作为 Java 的集合框架,它只能存储对象引用类型,也就是说当我们需要装载的数据是诸如 int、float 等基本数据类型的时候,必须把它们转换成对应的包装类。
ArrayList 的底层实现是一个 Object 数组:
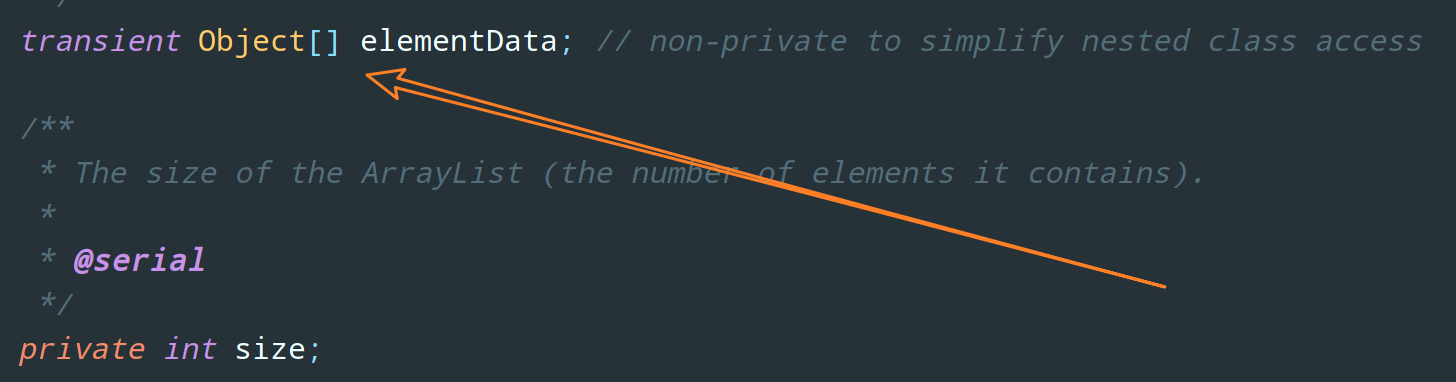
既然它是基于数组实现的,数组在内存空间中是连续分配的,那必然查询速率非常快,不过当然也肯定逃不过增删效率低的缺陷。
另外,和 ArrayList 一样同样实现了 List 接口的、我们比较常用的还有 LinkedList。LinkedList 比较特殊,它不仅实现了 List 接口,还实现了 Queue 接口,所以你可以看见 LinkedList 经常被当作队列使用:
Queue<Integer> queue = new LinkedList<>();
LinkedList 人如其名,它的底层自然是基于链表的,而且还是个双向链表。链表的特性和数组正好是反的,由于没有索引,所以查询效率低,但是增删速度快。
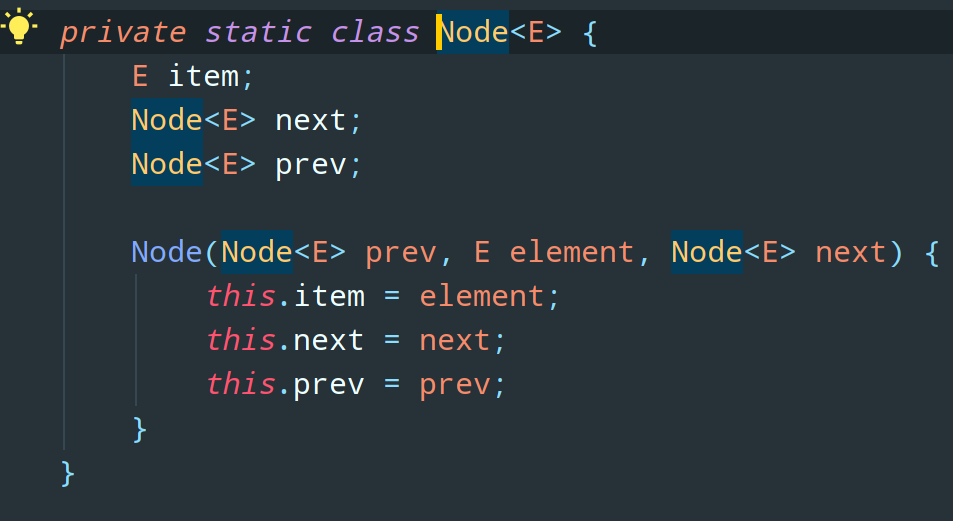
2. ArrayList 如何指定底层数组大小的?
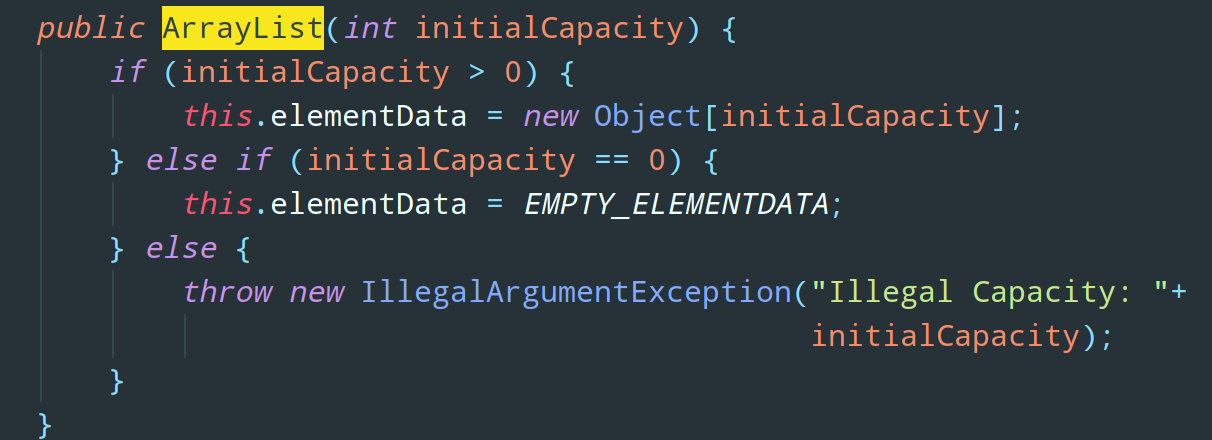
OK,首先,既然咱真正存储数据的地方是数组,那我们初始化 ArrayList 的时候自然要给数组分配一个大小,开辟一个内存空间。我们先来看看 ArrayList 的无参构造函数:
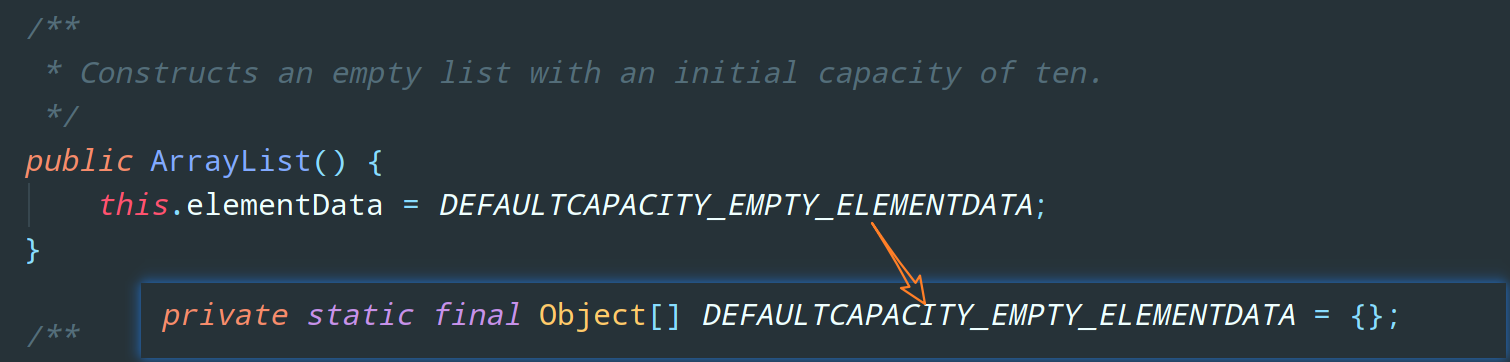
可以看到,它为底层的 Object 数组也就是 elementData 赋值了一个默认的空数组 DEFAULTCAPACITY_EMPTY_ELEMENTDATA。也就是说,使用无参构造函数初始化 ArrayList 后,它当时的数组容量为 0 。
这给咱初始化一个容量为 0 的数组有啥用?啥也存不了啊?别急,如果使用了无参构造函数来初始化 ArrayList, 只有当我们真正对数据进行添加操作 add 时,才会给数组分配一个默认的初始容量 DEFAULT_CAPACITY = 10。看下图:
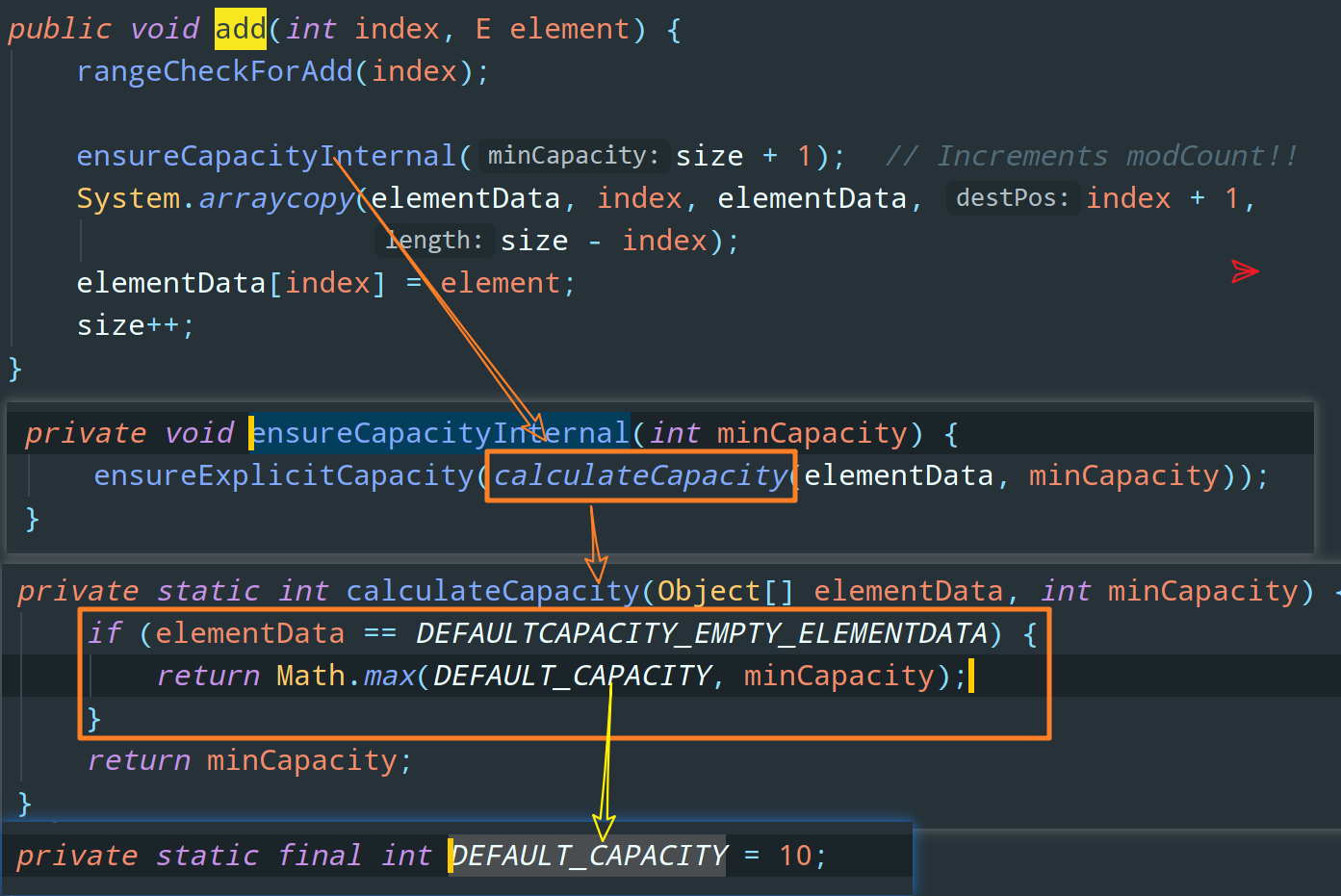
说完了无参构造,ArrayList 的有参构造函数就是中规中矩了,按照用户传入的大小开辟数组空间:
3. 数组的大小一旦被规定就无法改变,那 ArrayList 是怎么对底层数组进行扩容的?
ArrayList 的底层实现是 Object 数组,我们知道,数组的大小一旦被规定就无法改变。那如果我们不断的往里面添加数据的话,ArrayList 是如何进行扩容的呢?或者说 ArrayList 是如何实现存放任意数量对象的呢?
OK,扩容发生在啥时候?那肯定是我们往数组中新加入一个元素但是发现数组满了的时候。没错,我们去 add 方法中看看 ArrayList 是怎么做扩容的:
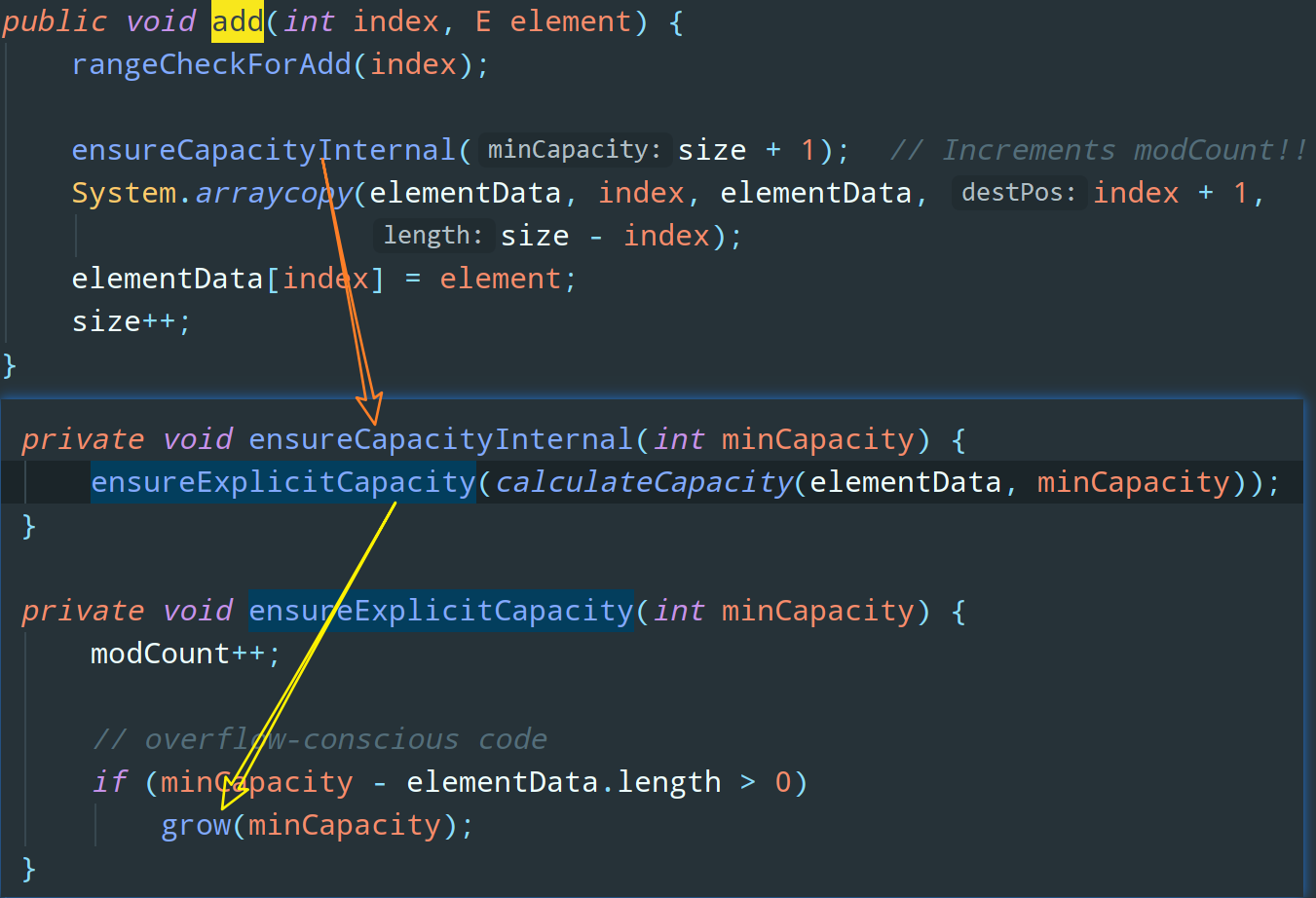
ensureExplicitCapacity 判断是否需要进行扩容,很显然,grow 方法是扩容的关键:
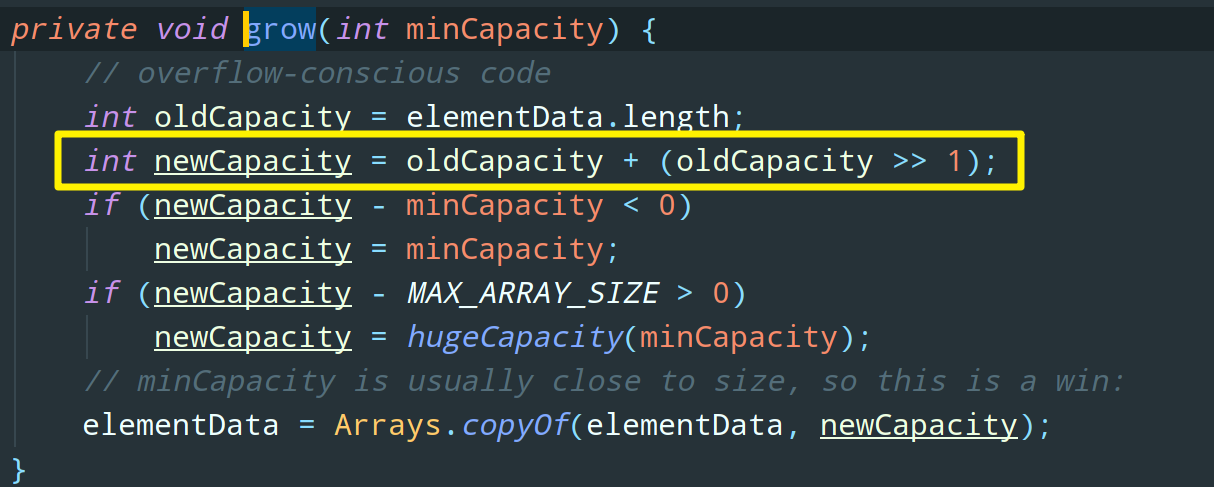
说实话,别的都不用看了,看上面图中的黄色框框就知道 ArrayList 是怎么扩容的了:扩容后的数组长度 = 当前数组长度 + 当前数组长度 / 2。最后使用 Arrays.copyOf 方法直接把原数组中的数组 copy 过来,需要注意的是,Arrays.copyOf 方法会创建一个新数组然后再进行拷贝。
举个例子画个图来演示一下:
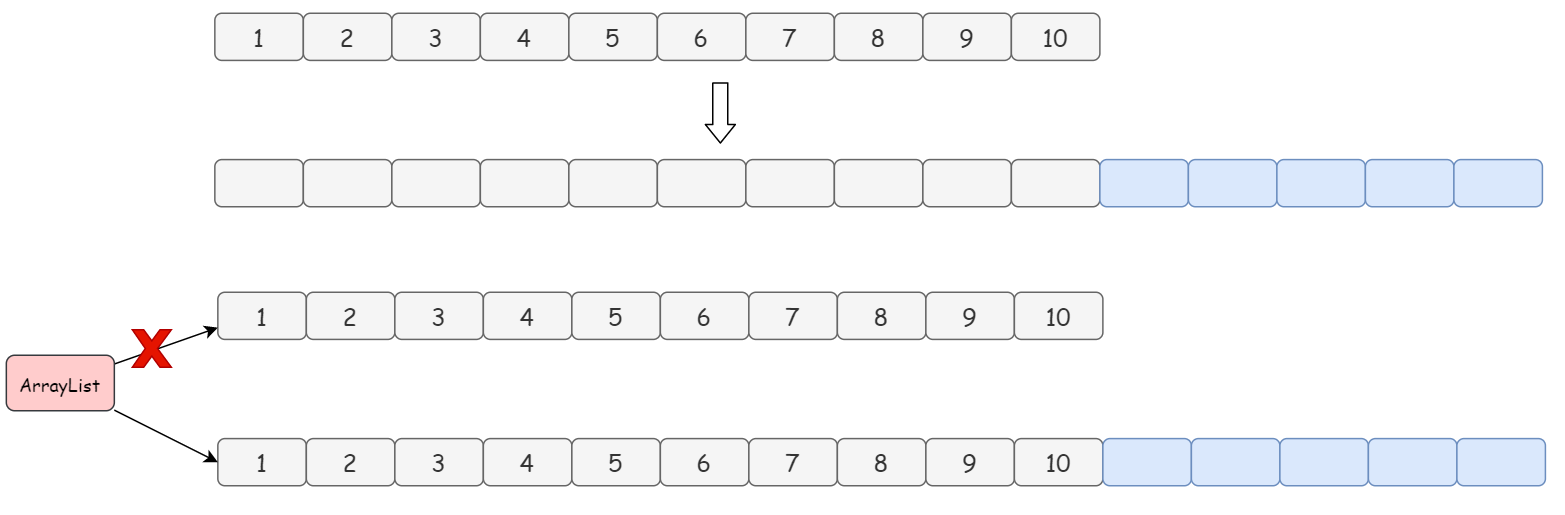
4. 既然扩容发生在添加数据的时候,讲讲 ArrayList 具体是怎么添加数据的
OK,add 方法我们刚刚讲了一半,添加数据前会先判断一下是否需要扩容,真正的添加数据的操作在下半部分:
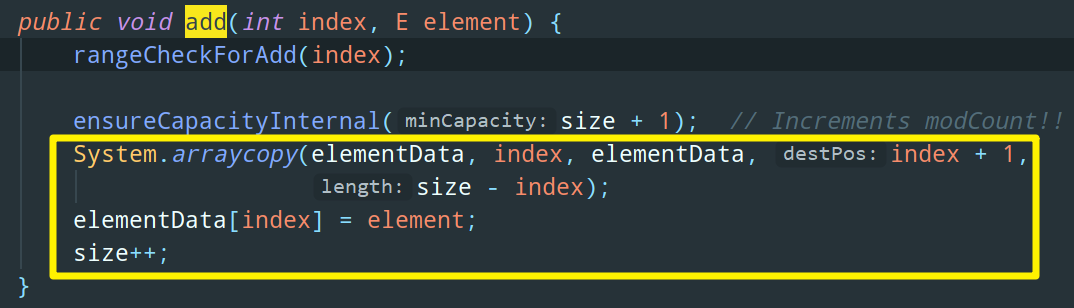
先讲下 add(int index, E element) 这个方法的含义,就是在指定索引 index 处插入元素 element。比如说 ArrayList.add(0, 3),意思就是在头部插入元素 3。
再来看看 add 方法的核心 System.arraycopy,这个方法有 5 个参数:
- elementData:源数组
- index:从源数组中的哪个位置开始复制
- elementData:目标数组
- index + 1:复制到目标数组中的哪个位置
- size - index:要复制的源数组中数组元素的数量
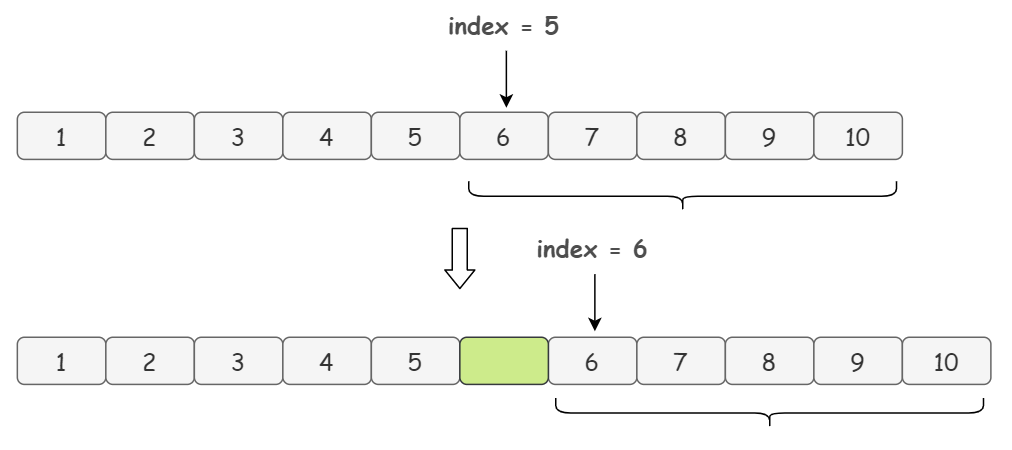
解释一下上面代码中 arraycopy 的意思,举个例子,我们想要在 index = 5 的位置插入元素,首先,我们会复制一遍源数组 elementData(这里我们称复制的数组为新数组吧),然后把源数组中从 index = 5 的位置开始到数组末尾的元素,放到新数组的 index + 1 = 6 的位置上:
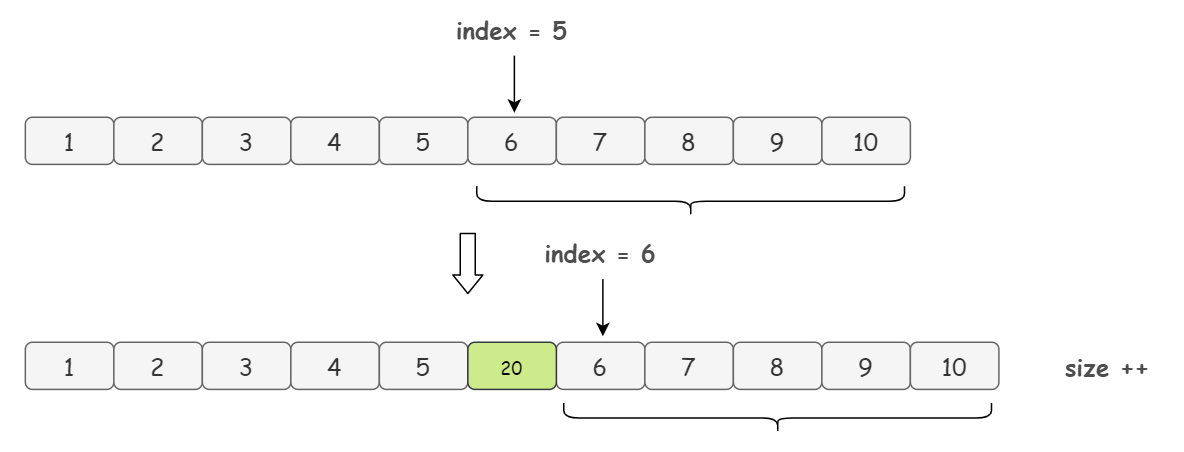
于是,这就给我们要新增的元素腾出了位置,然后在新数组 index = 5 的位置放入元素 element 就完成了添加的操作:
显然,不用多说,ArrayList 的将数据插入到指定位置的操作性能非常低下,因为要开辟新数组复制元素啊,要是涉及到扩容那就更慢了。
另外,ArrayList 还内置了一个直接在末尾添加元素的 add 方法,不用复制数组,直接 size ++ 就好,这个方法应该是我们最常使用的:

5. ArrayList 又是如何删除数据的呢?
Ctrl + F 找到 remove 方法,就这?和添加一个道理,也是复制数组
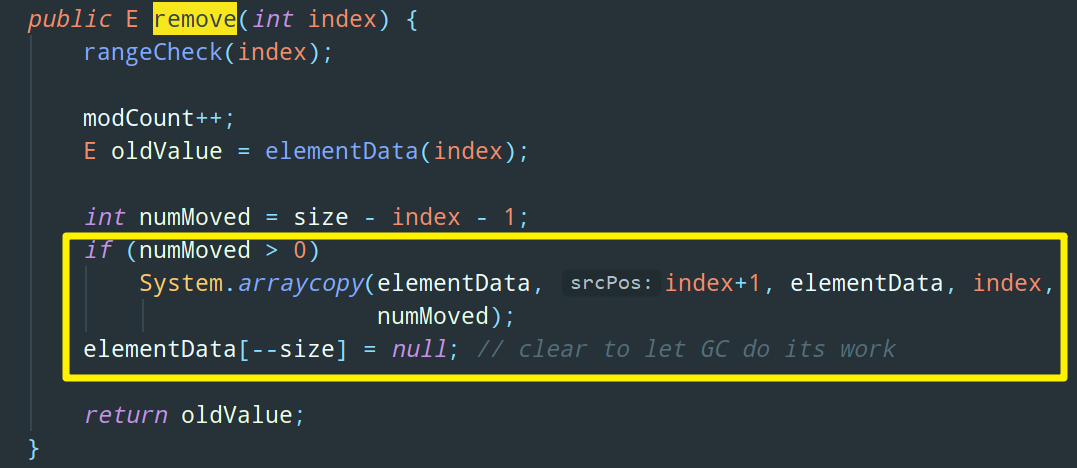
举个例子,假设我们要删除数组的 index = 5 的元素,首先,我们会复制一遍源数组,然后把源数组中从 index + 1 = 6 的位置开始到数组末尾的元素,放到新数组的 index = 5 的位置上:
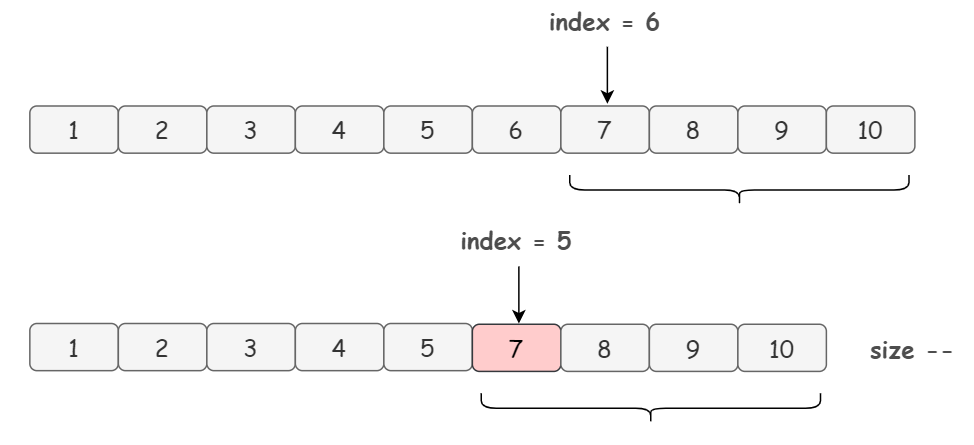
也就是说 index = 5 的元素直接被覆盖掉了,给了你被删除的感觉。同样的,它的效率自然也是十分低下的
6. ArrayList 是线程安全的吗?不安全的表现
ArrayList 和 LinkedList 都不是线程安全的,我们以在末尾添加元素的 add 方法为例,来看看 ArrayList 线程不安全的表现是啥:

黄色框里的并不是一个原子操作,它由两步操作构成:
elementData[size] = e;
size = size + 1;
在单线程执行这两条代码时,那当然没有任何问题,但是当多线程环境下执行时,可能就会发生一个线程添加的值覆盖另一个线程添加的值。举个例子:
- 假设 size = 0,我们要往这个数组的末尾添加元素
- 线程 A 开始添加一个元素,值为 A。此时它执行第一条操作,将 A 放在了数组 elementData 下标为 0 的位置上
- 接着线程 B 刚好也要开始添加一个值为 B 的元素,且走到了第一步操作。此时线程 B 获取到的 size 值依然为 0,于是它将 B 也放在了 elementData 下标为 0 的位置上
- 线程 A 开始增加 size 的值,size = 1
- 线程 B 开始增加 size 的值,size = 2
这样,线程 A、B 都执行完毕后,理想的情况应该是 size = 2,elementData[0] = A,elementData[1] = B。而实际情况变成了 size = 2,elementData[0] = B(线程 B 覆盖了线程 A 的操作),下标 1 的位置上什么都没有。并且后续除非我们使用 set 方法修改下标为 1 的值,否则这个位置上将一直为 null,因为在末尾添加元素时将会从 size = 2 的位置上开始。
上段代码验证下:
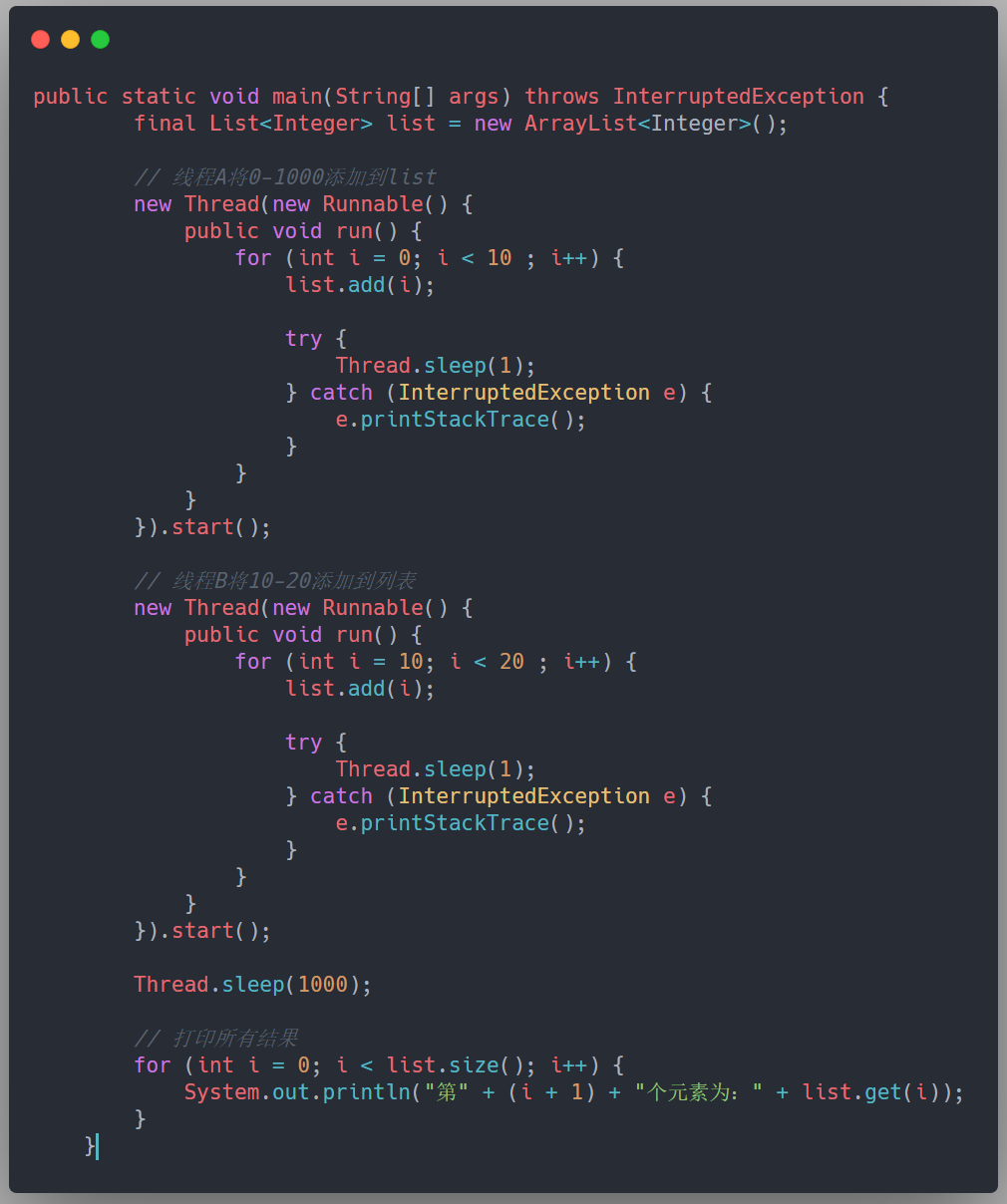
结果和我们分析的一样:
ArrayList 的线程安全版本是 Vector,它的实现很简单,就是把所有的方法统统加上 synchronized :
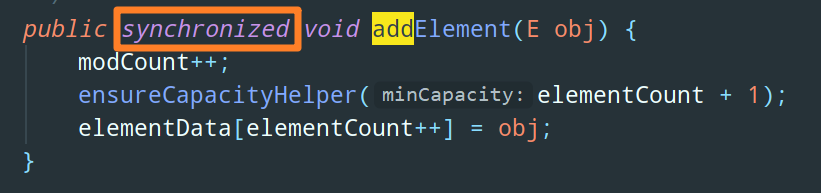
既然它需要额外的开销来维持同步锁,所以理论上来说它要比 ArrayList 要慢。
7. 为什么线程不安全还要用它呢?
因为在大多数场景中,查询的情况居多,不会涉及太频繁的增删。那如果真的涉及频繁的增删,可以使用LinkedList,底层链表实现,为增删而生。而如果你非得保证线程安全那就使用 Vector。当然实际开发中使用最多的还是 ArrayList,虽然线程不安全、增删效率低,但是查询效率高啊。
小伙伴们大家好呀,我是小牛肉,公众号【飞天小牛肉】定期推送大厂面试题,提供背诵版 + 详细版,知其然而知其所以然,让八股文变得有价值!)
来源:https://www.cnblogs.com/cswiki/p/16395899.html
本站部分图文来源于网络,如有侵权请联系删除。