 百木园
百木园数据来源
数据页面: 链家网南京(https://nj.lianjia.com/chengjiao/)
链家网数据量很大,这里只用南京的二手房成交数据。
如下图:
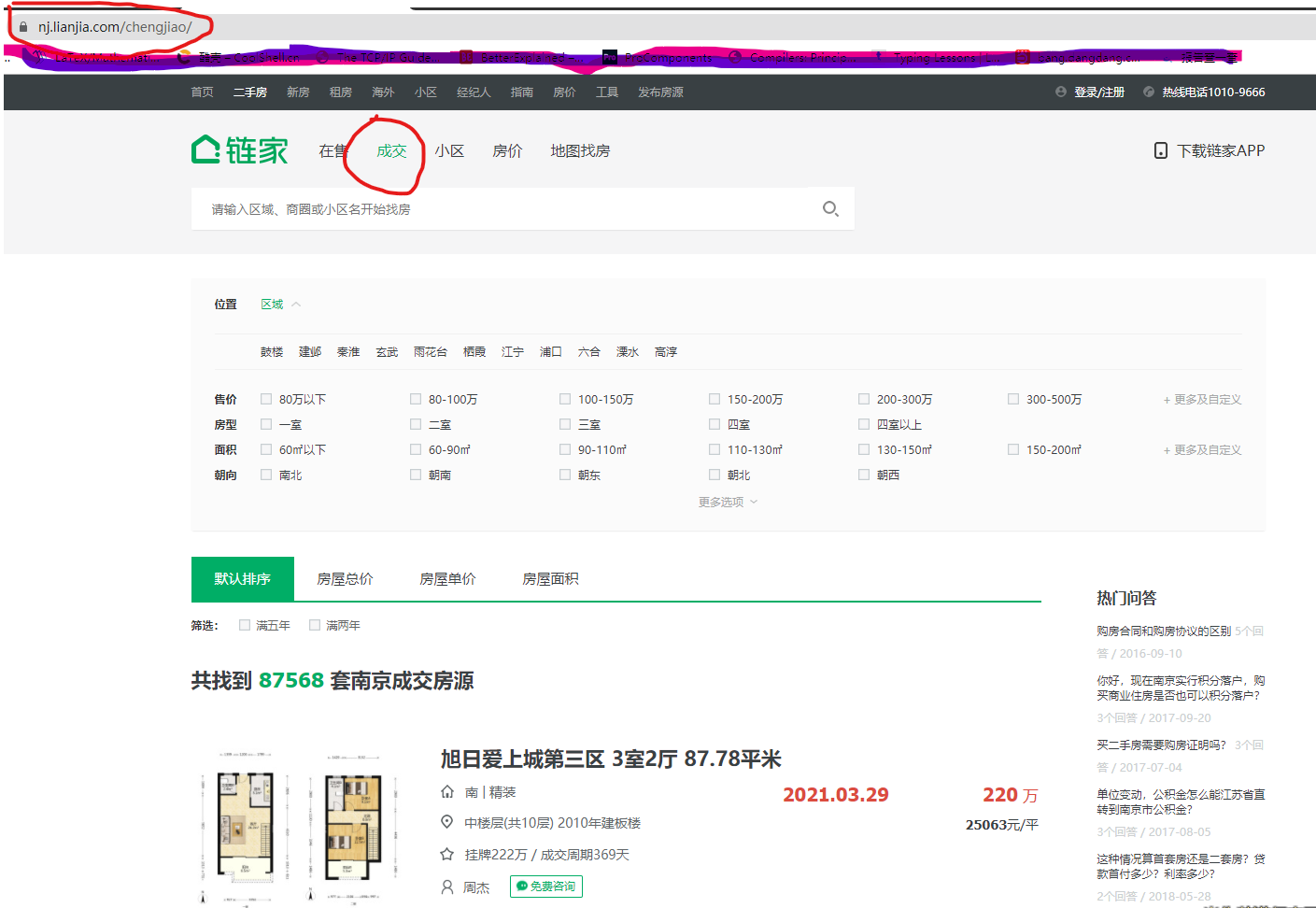
数据采集
链家网的页面数据比较整齐,采集很简单,为了避免影响别人使用,只采集的南京的二手房成交数据, 采集频率也很低,总共花了一下午才采集完所有数据。
我主要采集以下 9 个数据,没有采集房屋的图片。
爬虫技术争议比较多,详细的过程就不多说了,采集完的数据我放在以下地址:https://databook.top/data/b2b49fff-ede4-4ce5-9d96-08c616d1e481/detail
已经整理成 csv 格式,需要的可以下载了用来做数据分析实验。(数据截止到 2021/03/30)
数据采集的注意点
链家网的数据采集有个注意的地方,虽然打开这个网页(https://nj.lianjia.com/chengjiao/), 我们看到目前共找到 8 万多套成交房源,
但是链家网只显示 100 页的数据,每页 30 条,也就是最多一次查询出 3000 条数据。
所以,为了采集所有的数据,需要设置多种检索条件,保证每次搜索的数据不超过 3000 条。 8 万多条数据大概要设置 30 来种不同的搜索条件。
如下图,我主要根据区域,售价和户型来检索的,也就是按区域如果超过 3000,再按售价,售价还超出再按户型。 用这 3 个条件基本就够了。

数据清理
合并和去重
采集的数据是根据不同搜索条件来的,所以有很多个 csv 文件。 csv 格式是统一的,先用 shell 脚本进行数据的合并和去重,我是按照南京的不同的区来合并数据的。
采集的时候我已经按照不同的区把数据放在不同的文件夹了。合并数据脚本示例是如下:
d=\"merged-files\"
sed \"\" 建邺区/*.csv > ${d}/建邺区.csv
这里合并用的 sed 命令,没有用如下 cat 命令:
d=\"merged-files\"
cat 建邺区/*.csv > ${d}/建邺区.csv
用 cat 命令有个问题,前一个文件的最后一行会和下一个文件的第一行合并成一行。
合并之后就是去重:假设第一步合并后的文件都在 merged-files 文件夹下
d=\"merged-files\"
for f in `ls ${d}/`
do
sort -u ${d}/${f} -o uniq-${f}
done
格式化
采集到的原始数据是如下格式:
一品骊城 2室1厅 71平米,南 | 精装,2020.09.05,78,中楼层(共5层) 板楼,10916元/平,,挂牌82万,成交周期134天
可以看出,除了成交价(78)是正常的数字,单价(10916 元/平),挂牌价(挂牌 82 万),成交周期(成交周期 134 天)等都是数字和文字混合。 这些字段需要将数字剥离出来才能进行后续的分析。
我是通过一个简单的 golang 程序来格式化原始数据,然后生成新的 csv。
func handleData(line []string) TradedHouse {
var houseData TradedHouse
fmt.Printf(\"record: %v\\n\", line)
// 1. 小区名称和房屋概要
var arr = strings.Split(line[0], \" \")
houseData.Name = arr[0]
houseData.HouseType = arr[1]
if len(arr) > 2 {
houseData.HouseArea = gutils.ParseFloat64WithDefault(strings.TrimRight(arr[2], \"平米\"), 0.0)
}
// 2. 房屋朝向和装修情况
arr = strings.Split(line[1], \" | \")
houseData.HouseDirection = arr[0]
houseData.HouseDecoration = arr[1]
// 3. 成交日期
houseData.TradingTime = line[2]
// 4. 成交价格(单位: 万元)
houseData.TradingPrice = gutils.ParseFloat64WithDefault(line[3], 0.0)
// 5. 楼层等信息
houseData.FloorInfo = line[4]
// 6. 成交单价
houseData.UnitPrice = gutils.ParseFloat64WithDefault(strings.TrimRight(line[5], \"元/平\"), 0.0)
// 7. 房屋优势
houseData.Advance = line[6]
// 8. 挂牌价格
if len(line) > 7 {
houseData.ListedPrice = gutils.ParseFloat64WithDefault(strings.TrimRight(strings.TrimLeft(line[7], \"挂牌\"), \"万\"), 0.0)
}
// 9. 成交周期
if len(line) > 8 {
houseData.SellingTime, _ = strconv.Atoi(strings.TrimRight(strings.TrimLeft(line[8], \"成交周期\"), \"天\"))
}
return houseData
}
转换后的 csv 格式如下:
一品骊城,2室1厅,精装,中楼层(共5层) 板楼,71,10916,82,78,134,2020.09.05,南,
数值部分都分离出来了,可以进入数据分析的步骤了。
数据分析
最后的分析步骤使用的 python 脚本,主要使用 python 的 numpy 和 pandas 库。
下面分析了 2019~2020 南京各区二手房的每个月的销售套数,成交总额以及成交单价。
销售套数
# -*- coding: utf-8 -*-
import os
import numpy as np
import pandas as pd
def read_csv(fp):
# 读取2列 col9: 成交时间
# 其中成交时间进行处理:从 2020.01.01 ==> 2020.01
data = pd.read_csv(
fp,
usecols=[9],
header=None,
names=[\"time\"],
converters={\"time\": lambda s: s[:7]},
)
data_mask = data[\"time\"].str.contains(\"2019|2020\")
data = data[data_mask]
data[\"count\"] = 1
return data.groupby(\"time\")
def write_csv(fp, data):
data.to_csv(fp)
def main():
# 读取csv数据
csv_path = \"../liangjia-go/output/converter\"
output_path = \"./成交数量统计.csv\"
files = list(
map(
lambda f: os.path.join(csv_path, f + \".csv\"),
[
\"南京鼓楼区\",
\"南京建邺区\",
\"南京江宁区\",
\"南京溧水区\",
\"南京六合区\",
\"南京浦口区\",
\"南京栖霞区\",
\"南京秦淮区\",
\"南京玄武区\",
\"南京雨花台区\",
],
)
)
allData = None
for f in files:
data = read_csv(f)
data = data.sum()
data[\"area\"] = os.path.basename(f).strip(\".csv\").strip(\"南京\")
print(data)
if allData is None:
allData = data
else:
allData = allData.append(data)
write_csv(output_path, allData)
if __name__ == \"__main__\":
main()
成交总额
# -*- coding: utf-8 -*-
import os
import numpy as np
import pandas as pd
def read_csv(fp):
# 读取2列 col9: 成交时间, col7: 成交价格(万元)
# 其中成交时间进行处理:从 2020.01.01 ==> 2020.01
data = pd.read_csv(
fp,
usecols=[7, 9],
header=None,
names=[\"value\", \"time\"],
converters={\"time\": lambda s: s[:7]},
)
data_mask = data[\"time\"].str.contains(\"2019|2020\")
data = data[data_mask]
return data.groupby(\"time\")
def write_csv(fp, data):
data.to_csv(fp)
def main():
# 读取csv数据,提取成交价格(col 7)
csv_path = \"../liangjia-go/output/converter\"
output_path = \"./成交额统计.csv\"
files = list(
map(
lambda f: os.path.join(csv_path, f + \".csv\"),
[
\"南京鼓楼区\",
\"南京建邺区\",
\"南京江宁区\",
\"南京溧水区\",
\"南京六合区\",
\"南京浦口区\",
\"南京栖霞区\",
\"南京秦淮区\",
\"南京玄武区\",
\"南京雨花台区\",
],
)
)
allData = None
for f in files:
data = read_csv(f)
data = data.sum()
data[\"area\"] = os.path.basename(f).strip(\".csv\").strip(\"南京\")
print(data)
if allData is None:
allData = data
else:
allData = allData.append(data)
# 万元 => 元
allData[\"value\"] = allData[\"value\"] * 10000
write_csv(output_path, allData)
if __name__ == \"__main__\":
main()
成交单价
# -*- coding: utf-8 -*-
import os
import numpy as np
import pandas as pd
def read_csv(fp):
# 读取2列 col9: 成交时间, col5: 成交单价(元/平米)
# 其中成交时间进行处理:从 2020.01.01 ==> 2020.01
data = pd.read_csv(
fp,
usecols=[5, 9],
header=None,
names=[\"value\", \"time\"],
converters={\"time\": lambda s: s[:7]},
)
data_mask = data[\"time\"].str.contains(\"2019|2020\")
data = data[data_mask]
return data.groupby(\"time\")
def write_csv(fp, data):
data.to_csv(fp)
def main():
# 读取csv数据,提取成交价格(col 7)
csv_path = \"../liangjia-go/output/converter\"
output_path = \"./成交单价统计.csv\"
files = list(
map(
lambda f: os.path.join(csv_path, f + \".csv\"),
[
\"南京鼓楼区\",
\"南京建邺区\",
\"南京江宁区\",
\"南京溧水区\",
\"南京六合区\",
\"南京浦口区\",
\"南京栖霞区\",
\"南京秦淮区\",
\"南京玄武区\",
\"南京雨花台区\",
],
)
)
allData = None
for f in files:
data = read_csv(f)
data = data.mean()
data[\"area\"] = os.path.basename(f).strip(\".csv\").strip(\"南京\")
print(data)
if allData is None:
allData = data
else:
allData = allData.append(data)
write_csv(output_path, allData)
if __name__ == \"__main__\":
main()
分析结果展示
分析后生成的 csv,我写了另外一个工具,可以直接转换成小视频。
工具是基于 antv G2 和 ffmpeg 做的,还不是很成熟,以后会发布到官网上,同时在博客中详细介绍。
生成的视频已经放在我的视频号了,感兴趣可以看看。

总结
虽然上面的数据量不是很大,但这是我平时做一次数据分析的的整个过程(从数据采集到可视化展示)。
来源:https://www.cnblogs.com/wang_yb/p/14661559.html
图文来源于网络,如有侵权请联系删除。