 百木园
百木园1 MySQL总体架构介绍
1.1 MySQL总体架构介绍
引言
MySQL是一个关系型数据库
应用十分广泛
在学习任何一门知识之前
对其架构有一个概括性的了解是非常重要的
比如索引、sql是在哪个地方执行的
流程是什么样的
今天我们就先来学习一下MySQL的总体架构
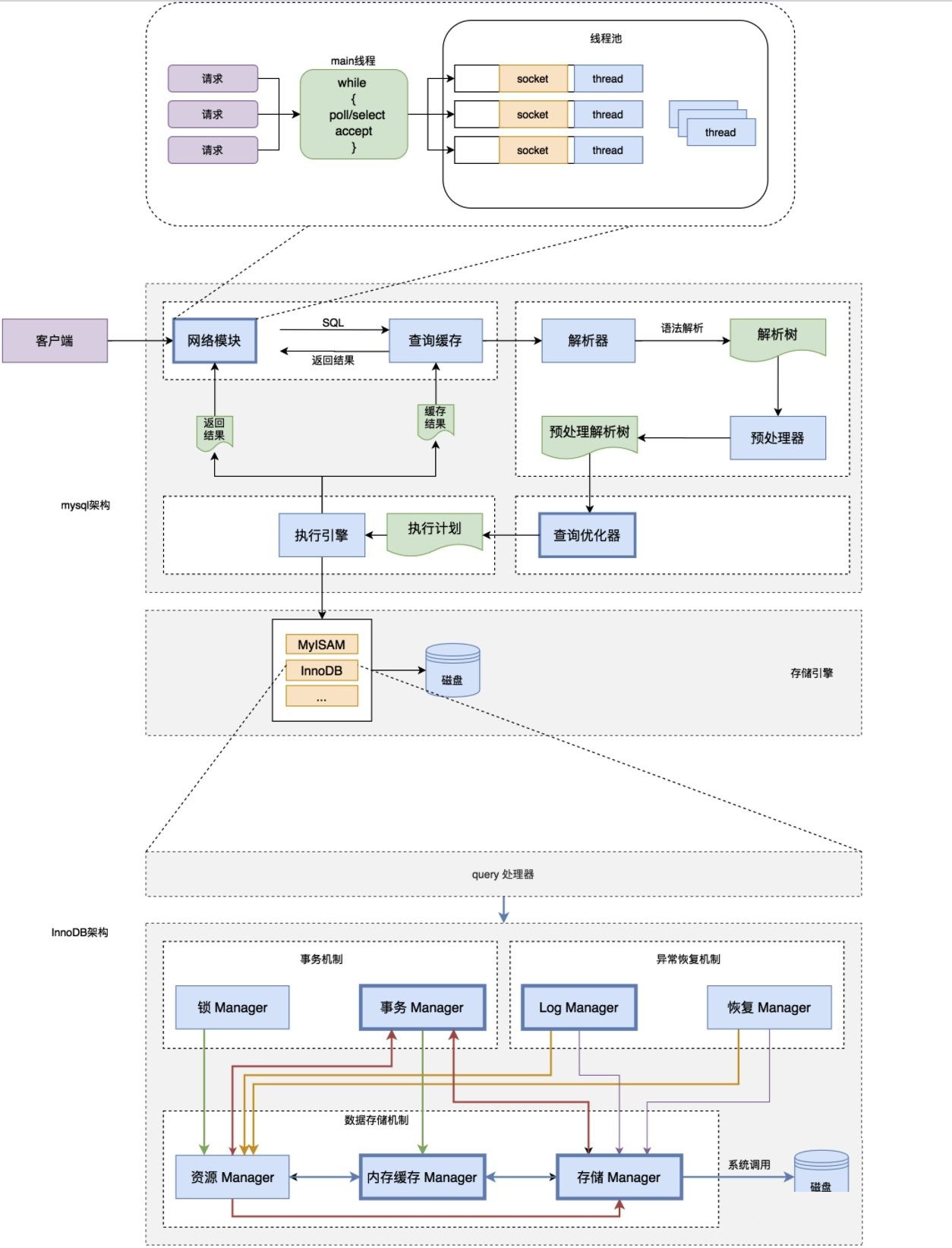
总的来说:MySQL架构是一个客户端-服务器系统。
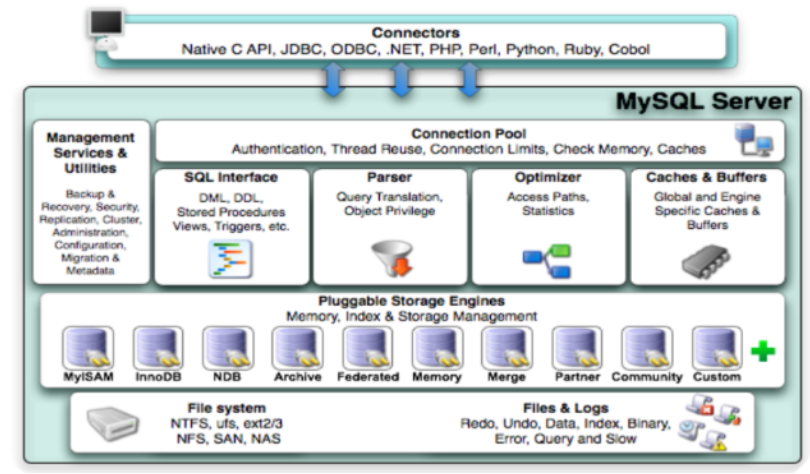
MySQL主要包括以下几部分:
Server 层:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binglog 日志模块。
存储引擎: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自己的日志模块 redolog 模块。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始就被当做默认存储引擎了
连接器: 身份认证和权限相关(登录 MySQL 的时候)。
查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)mysql的server层增加一层缓存模块,类似一个内存的kv层,k是sql,value是结果
分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
优化器: 按照 MySQL 认为最优的方案去执行。
执行器: 执行语句,然后从存储引擎返回数据。
1.2 MySQL存储引擎介绍
引言
和大多数的数据库不同, MySQL中有一个存储引擎的概念
针对不同的存储需求可以选择最优的存储引擎。
存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式 。
存储引擎是基于表的,而不是基于库的
所以存储引擎也可被称为表类型。
MySQL提供了插件式的存储引擎架构。所以MySQL存在多种存储引擎,可以根据需要使用相应引擎,或者编写存储引擎。
MySQL5.0支持的存储引擎包含 : InnoDB 、MyISAM 、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED等
可以通过指定 show engines , 来查询当前数据库支持的存储引擎 :
SHOW ENGINES;
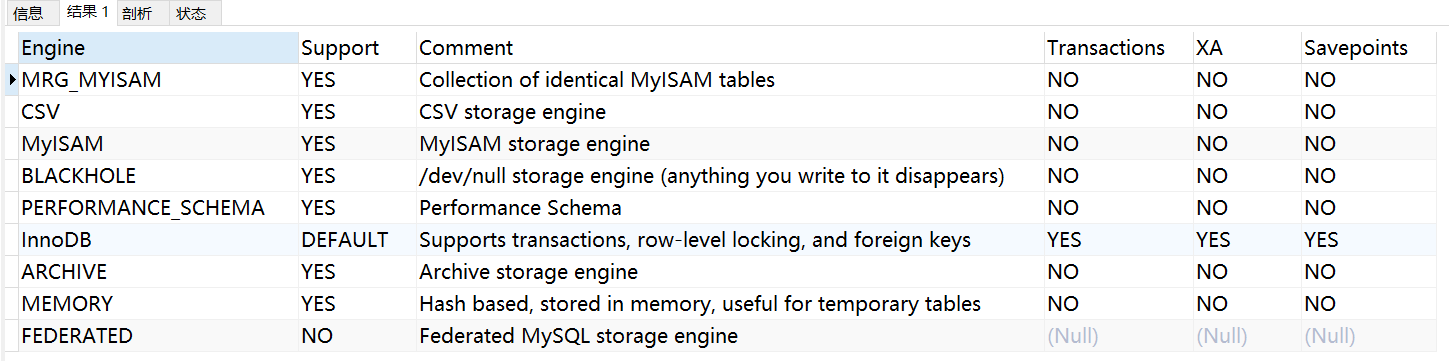
表含义:
- support : 指服务器是否支持该存储引擎
- transactions : 指存储引擎是否支持事务
- XA : 指存储引擎是否支持分布式事务处理
- Savepoints : 指存储引擎是否支持保存点(实现回滚到指定保存点)
-
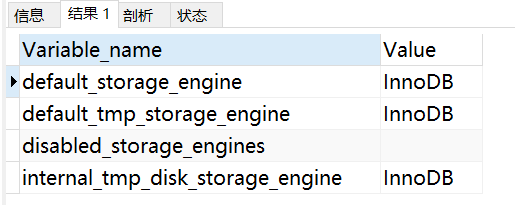
查看MySQL数据库存储引擎配置
SHOW VARIABLES LIKE \'%storage_engine%\';
1.2.1 如何更改数据库表引擎
- 建表语句后面加入引擎赋值即可 ,命令举例如下 ,
CREATE TABLE t1(
id INT ,
name VARCHAR(20)
) ENGINE = MyISAM;
- 修改已有的表引擎 , 命令举例如下 ,
ALTER TABLE t1 ENGINE = InnoDB;
1.2.2 常用引擎及其特性对比
-
常见的存储引擎 :
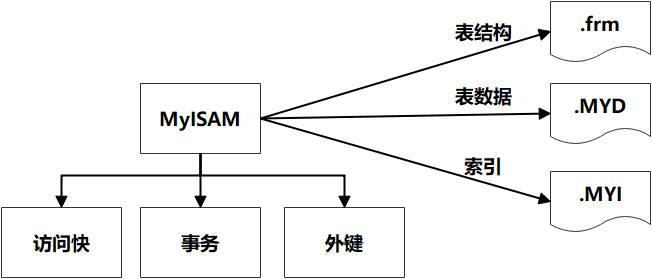
MyISAM存储引擎 : 访问快,不支持事务和外键。表结构保存在.frm文件中,表数据保存在.MYD文件中,索引保存在.MYI文件中。
[root@linux-141 itcast]# ll -rw-r-----. 1 mysql mysql 8630 9月 10 16:01 t_account_myisam.frm -rw-r-----. 1 mysql mysql 52 9月 10 16:06 t_account_myisam.MYD -rw-r-----. 1 mysql mysql 2048 9月 10 17:56 t_account_myisam.MYI [root@linux-141 itcast]#
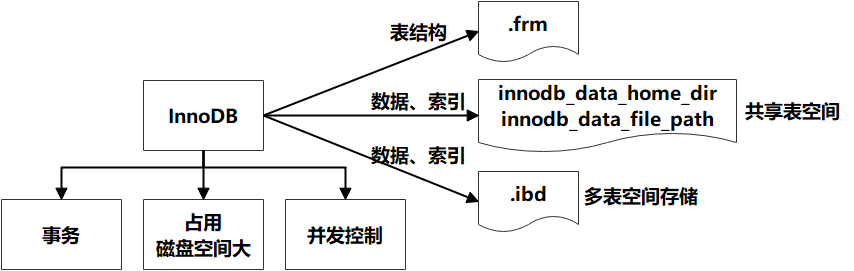
innoDB存储引擎(5.5版本开始默认) : 支持事务 ,占用磁盘空间大 ,支持并发控制。表结构保存在.frm文件中,如果是共享表空间,数据和索引保存在 innodb_data_home_dir 和 innodb_data_file_path定义的表空间中,可以是多个文件。如果是多表空间存储,每个表的数据和索引单独保存在 .ibd 中。
[root@linux-141 itcast]# ll
-rw-r-----. 1 mysql mysql 8630 9月 10 16:02 t_account_innodb.frm
-rw-r-----. 1 mysql mysql 98304 9月 14 15:50 t_account_innodb.ibd
[root@linux-141 itcast]#
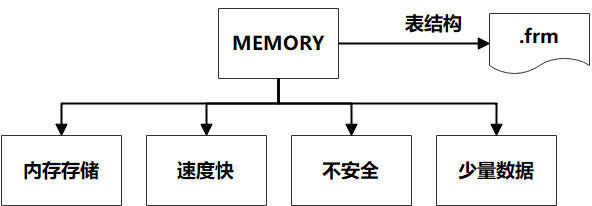
MEMORY存储引擎 : 内存存储 , 速度快 ,不安全 ,适合小量快速访问的数据。表结构保存在.frm中。
!
特性对比 :
| 特点 | InnoDB | MyISAM | MEMORY | MERGE | NDB |
|---|---|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 | 没有 | 有 |
| 事务安全 | 支持 | ||||
| 锁机制 | 行锁(适合高并发) | 表锁 | 表锁 | 表锁 | 行锁 |
| B树索引 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 哈希索引 | 支持 | ||||
| 全文索引 | 支持(5.6版本之后) | 支持 | |||
| 集群索引 | 支持 | ||||
| 数据索引 | 支持 | 支持 | 支持 | ||
| 索引缓存 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 数据可压缩 | 支持 | ||||
| 空间使用 | 高 | 低 | N/A | 低 | 低 |
| 内存使用 | 高 | 低 | 中等 | 低 | 高 |
| 批量插入速度 | 低 | 高 | 高 | 高 | 高 |
| 支持外键 | 支持 |
1.2.3 如何选择不同类型的引擎
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
以下是几种常用的存储引擎的使用环境。
- InnoDB : 是Mysql的默认存储引擎,用于事务处理应用程序,支持外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询以外,还包含更新、删除操作,那么InnoDB存储引擎是比较合适的选择。InnoDB存储引擎除了有效的降低由于删除和更新导致的锁定, 还可以确保事务的完整提交和回滚,对于类似于计费系统或者财务系统等对数据准确性要求比较高的系统,InnoDB是最合适的选择。
- MyISAM : 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
- MEMORY:将所有数据保存在RAM中,在需要快速定位记录和其他类似数据环境下,可以提供极快的访问。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,其次是要确保表的数据可以恢复,数据库异常终止后表中的数据是可以恢复的。MEMORY表通常用于更新不太频繁的小表,用以快速得到访问结果。
1.3 SQL的执行流程是什么样的
- 客户端发送一条查询给服务器。
- 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,再调用存储引擎的API来执行查询。
- 将结果返回给客户端。
2 MySQL存储引擎调优
2.1 MySQL服务器硬件优化
tips
硬件(cpu、内存等)相关
了解即可
关于提升硬件设备性能:
例如选择尽量高频率的内存(频率不能高于主板的支持)、提升网络带宽、使用SSD高速磁盘、提升CPU性能等。
CPU的选择:
- 对于数据库并发比较高的场景,CPU的数量比频率重要。
- 对于CPU密集型场景和频繁执行复杂SQL的场景,CPU的频率越高越好
磁盘的选择
影响数据库最大的性能问题就是磁盘I/O
为提高数据库的IOPS性能,可使用SSD或PCIE-SSD高速磁盘设备
磁盘IO的优化
可以用RAID来进行优化
常用RAID(磁盘阵列)级别:
RAID0:也称为条带,就是把多个磁盘链接成一个硬盘使用,这个级别IO最好
RAID1:也称为镜像,要求至少有两个磁盘,每组磁盘存储的数据相同
RAID5:也是把多个(最少3个)硬盘合并成一个逻辑盘使用,数据读写时会建立奇偶校验信息,并且奇偶校验信息和相对应的数据分别存储在不同的磁盘上。当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和响应的奇偶校验信息去恢复被损坏的数据
RAID1+0(建议使用):就是RAID0和RAID1的组合。同时具备两个级别的优缺点,一般建议数据库使用这个级别。
2.2 MySQL数据库配置优化
tips:
以下为生产环境中最常用的DB参数配置
-
表示缓冲池字节大小,大的缓冲池可以减少磁盘IO次数。
innodb_buffer_pool_size = 推荐值为物理内存的50%~80%。 -
用来控制redo log buffer刷新到磁盘的策略。
innodb_flush_log_at_trx_commit=1select @@innodb_flush_log_at_trx_commit;0 : 提交事务的时候,不立即把 redo log buffer 里的数据刷入磁盘文件中,而是依靠 InnoDB 的主线程每秒执行一次刷新到磁盘。此时可能你提交事务了,结果 mysql 宕机了,然后此时内存里的数据全部丢失。 1 : 提交事务的时候,立即把 redo log buffer 里的数据刷入磁盘文件中,只要事务提交成功,那么数据就必然在磁盘里了。 2 : 提交事务的时候,把 redo log buffer日志写入磁盘文件对应的系统缓存,而不是直接进入磁盘文件,这时可能1秒后才会把系统缓存里的数据写入到磁盘文件。 -
每提交1次事务就同步写到磁盘中,可以设置为1。
sync_binlog=10:默认值。事务提交后,将二进制日志从缓冲写入操作系统缓冲,但是不进行刷新操作(fsync()),此时只是写入了操作系统缓冲而没有刷新到磁盘,若操作系统宕机则会丢失部分二进制日志。 1:事务提交后,将二进制文件写入磁盘并立即执行刷新操作,相当于是同步写入磁盘,不经过操作系统的缓存。 N:每写N次操作系统缓冲就执行一次刷新操作。 -
脏页占innodb_buffer_pool_size的比例,触发刷脏页到磁盘。 推荐值为25%~50%。
innodb_max_dirty_pages_pct=30脏页:内存数据页和磁盘数据页上的内容不一致 -
后台进程最大IO性能指标。
默认200,如果SSD,调整为5000~20000PCIE-SSD可调整为5w左右
默认:innodb_io_capacity=200
-
指定innodb共享表空间文件的大小。
innodb_data_file_path = ibdata:1G:autoextend:默认10M,一般设置为1GB
-
慢查询日志的阈值设置,单位秒。
long_query_time=0.3合理设置区间0.1s~0.5s,
-
mysql复制的形式,row为MySQL8.0的默认形式。
binlog_format=row建议binlog的记录格式为row模式
STATEMENT模式:每一条会修改数据的sql语句都会记录到binlog中。 ROW模式:不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。 MIXED模式:以上两种模式的混合使用。 -
降低interactive_timeout、wait_timeout的值。
交互等待时间和非交互等待时间,值一致,建议300~500s,默认8小时
在用mysql客户端对数据库进行操作时,打开终端窗口,如果一段时间(8小时)没有操作,再次操作时,会报错:当前的连接已经断开,需要重新建立连接 -
数据库最大连接数max_connections=200
-
过大,实例恢复时间长;过小,造成日志切换频繁。
innodb_log_file_size=默认redo log空间大小
-
全量日志建议关闭。
默认关闭general_log=0开启 general log 将所有到达MySQL Server的SQL语句记录下来,general_Log文件就会产生很大的文件,建议关闭
2.3 Mysql中查询缓存优化
tips:
在MySQL 8.0之后废弃这个功能
原理:复杂、实用性不高
作为了解即可
1) 查询缓存概述
开启Mysql的查询缓存,当执行完全相同的SQL语句的时候,服务器就会直接从缓存中读取结果,当数据被修改,之前的缓存会失效,修改比较频繁的表不适合做查询缓存。
2) 操作流程
回顾
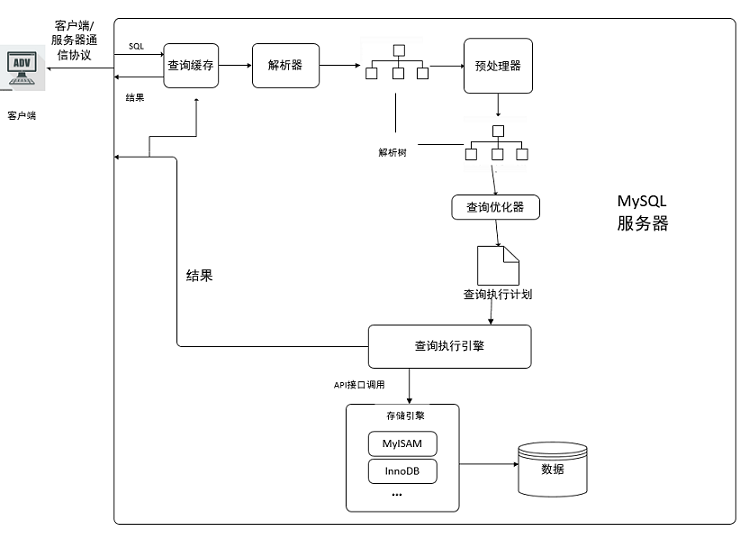
- 客户端发送一条查询给服务器;
- 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段;
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划;
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
- 将结果返回给客户端。
3) 查询缓存配置
-
查看当前的MySQL数据库是否支持查询缓存:
SHOW VARIABLES LIKE \'have_query_cache\';

-
查看当前MySQL是否开启了查询缓存 :
SHOW VARIABLES LIKE \'query_cache_type\';

-
查看查询缓存的占用大小 :
SHOW VARIABLES LIKE \'query_cache_size\';

-
查看查询缓存的状态变量:
SHOW STATUS LIKE \'Qcache%\';
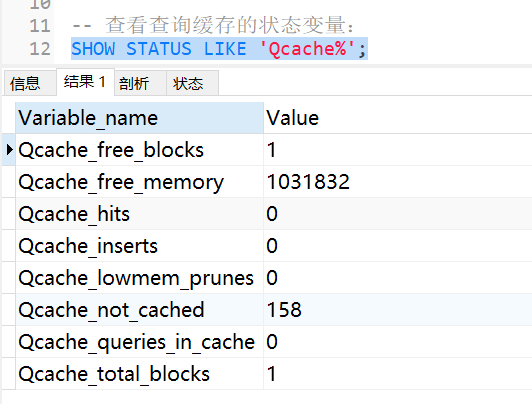
各个变量的含义如下:
| 参数 | 含义 |
|---|---|
| Qcache_free_blocks | 查询缓存中的可用内存块数 |
| Qcache_free_memory | 查询缓存的可用内存量 |
| Qcache_hits | 查询缓存命中数 |
| Qcache_inserts | 添加到查询缓存的查询数 |
| Qcache_lowmen_prunes | 由于内存不足而从查询缓存中删除的查询数 |
| Qcache_not_cached | 非缓存查询的数量(由于 query_cache_type 设置而无法缓存或未缓存) |
| Qcache_queries_in_cache | 查询缓存中注册的查询数 |
| Qcache_total_blocks | 查询缓存中的块总数 |
4) 开启查询缓存
MySQL的查询缓存默认是关闭的,需要手动配置参数 query_cache_type , 来开启查询缓存。query_cache_type 该参数的可取值有三个 :
| 值 | 含义 |
|---|---|
| OFF 或 0 | 查询缓存功能关闭 |
| ON 或 1 | 查询缓存功能打开,SELECT的结果符合缓存条件即会缓存,否则,不予缓存,显式指定 SQL_NO_CACHE,不予缓存 |
| DEMAND 或 2 | 查询缓存功能按需进行,显式指定 SQL_CACHE 的SELECT语句才会缓存;其它均不予缓存 |
在 my.cnf 配置中,增加以下配置 :
#开启查询缓存
query_cache_type=1
配置完毕之后,重启服务既可生效 ;
然后就可以在命令行执行SQL语句进行验证 ,执行一条比较耗时的SQL语句,然后再多执行几次,查看后面几次的执行时间;获取通过查看查询缓存的缓存命中数,来判定是否走查询缓存。
-- 执行SQL语句进行验证 查询缓存
SELECT * FROM product_list WHERE store_name = \'联想北达兴科专卖店\';
-- 将SELECT修改为小写,发现缓存失效
SELECT * FROM product_list WHERE store_name = \'联想北达兴科专卖店\';
5) 查询缓存SELECT选项
可以在SELECT语句中指定两个与查询缓存相关的选项 :
SQL_CACHE : 如果查询结果是可缓存的,并且 query_cache_type 系统变量的值为ON或 DEMAND ,则缓存查询结果 。
SQL_NO_CACHE : 服务器不使用查询缓存。它既不检查查询缓存,也不检查结果是否已缓存,也不缓存查询结果。
例子:
SELECT SQL_CACHE id, name FROM xxx;
SELECT SQL_NO_CACHE id, name FROM xxx;
6) 查询缓存失效的情况
tips
需要注意的问题
1) SQL 语句不一致的情况, 要想命中查询缓存,查询的SQL语句必须一致。
SQL1 : select count(*) from xxx;
SQL2 : Select count(*) from xxx;
2) 当查询语句中有一些不确定的值,则不会缓存。如 : now() , current_date() , curdate() , curtime() , rand() , uuid() , user() , database() 。
SQL1 : select * from xxx where updatetime < now() limit 1;
SQL2 : select user();
SQL3 : select database();
3) 不使用任何表查询语句。
select \'A\';
4) 查询 mysql, information_schema或 performance_schema 数据库中的表时,不会走查询缓存。
select * from information_schema.engines;
5) 在存储的函数,触发器或事件的主体内执行的查询。
6) 如果表更改,则使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除。这包括使用MERGE映射到已更改表的表的查询。一个表可以被许多类型的语句,如被改变 INSERT, UPDATE, DELETE, TRUNCATE TABLE, ALTER TABLE, DROP TABLE,或 DROP DATABASE 。
将查询缓存关闭,因为后面还需要进行索引的验证,所以不希望走查询缓存
[root@linux-141 itcast]# vi /etc/my.cnf
[root@linux-141 itcast]# service mysql restart
Shutting down MySQL.... SUCCESS!
Starting MySQL. SUCCESS!
2.4. Mysql内存管理及优化
1)内存优化原则
1) 将尽量多的内存分配给MySQL做缓存,但要给操作系统和其他程序预留足够内存。
2) MyISAM 存储引擎的数据文件读取依赖于操作系统自身的IO缓存,因此,如果有MyISAM表,就要预留更多的内存给操作系统做IO缓存。
3) 排序区、连接区等缓存是分配给每个数据库会话(session)专用的,其默认值的设置要根据最大连接数合理分配,如果设置太大,不但浪费资源,而且在并发连接较高时会导致物理内存耗尽。
2) MyISAM 内存优化
MyISAM 存储引擎使用 key_buffer 缓存索引块,加速myisam索引的读写速度。对于myisam表的数据块,mysql没有特别的缓存机制,完全依赖于操作系统的IO缓存。
key_buffer_size
key_buffer_size决定MyISAM索引块缓存区的大小,直接影响到MyISAM表的存取效率。可以在MySQL参数文件中设置key_buffer_size的值,对于一般MyISAM数据库,建议至少将1/4可用内存分配给key_buffer_size。
在my.cnf 中做如下配置:
key_buffer_size=512M
read_buffer_size
如果需要经常顺序扫描MyISAM 表,可以通过增大read_buffer_size的值来改善性能。但需要注意的是read_buffer_size是每个session独占的,如果默认值设置太大,就会造成内存浪费。
read_rnd_buffer_size
对于需要做排序的MyISAM 表的查询,如带有order by子句的sql,适当增加 read_rnd_buffer_size 的值,可以改善此类的sql性能。
但需要注意的是 read_rnd_buffer_size 是每个session独占的,如果默认值设置太大,就会造成内存浪费。
3) InnoDB 内存优化
innodb用一块内存区做IO缓存池,该缓存池不仅用来缓存innodb的索引块,而且也用来缓存innodb的数据块。
innodb_buffer_pool_size
该变量决定了 innodb 存储引擎表数据和索引数据的最大缓存区大小。在保证操作系统及其他程序有足够内存可用的情况下,innodb_buffer_pool_size 的值越大,缓存命中率越高,访问InnoDB表需要的磁盘I/O 就越少,性能也就越高。
innodb_buffer_pool_size=512M
innodb_log_buffer_size
决定了innodb重做日志缓存的大小,对于可能产生大量更新记录的大事务,增加innodb_log_buffer_size的大小,可以避免innodb在事务提交前就执行不必要的日志写入磁盘操作。
innodb_log_buffer_size=10M
2.5. Mysql并发参数调整
从实现上来说,MySQL Server 是多线程结构,包括后台线程和客户服务线程。多线程可以有效利用服务器资源,提高数据库的并发性能。在Mysql中,控制并发连接和线程的主要参数包括 max_connections、back_log、thread_cache_size、table_open_cahce。
1) max_connections
最大可支持的连接数
采用max_connections 控制允许连接到MySQL数据库的最大数量,默认值是 151。如果状态变量 connection_errors_max_connections 不为零,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这时可以考虑增大max_connections 的值。
Mysql 最大可支持的连接数,取决于很多因素,包括给定操作系统平台的线程库的质量、内存大小、每个连接的负荷、CPU的处理速度,期望的响应时间等。在Linux 平台下,性能好的服务器,支持 500-1000 个连接不是难事,需要根据服务器性能进行评估设定。
2) back_log
积压请求栈大小
back_log 参数控制MySQL监听TCP端口时设置的积压请求栈大小。如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。5.6.6 版本之前默认值为 50 , 之后的版本默认为 50 + (max_connections / 5), 但最大不超过900。
如果需要数据库在较短的时间内处理大量连接请求, 可以考虑适当增大back_log 的值。
3) table_open_cache
执行线程可打开表缓存个数
该参数用来控制所有SQL语句执行线程可打开表缓存的数量, 而在执行SQL语句时,每一个SQL执行线程至少要打开 1 个表缓存。该参数的值应该根据设置的最大连接数 max_connections 以及每个连接执行关联查询中涉及的表的最大数量来设定 :
max_connections x N ;
4) thread_cache_size
缓存客户服务线程的数量
为了加快连接数据库的速度,MySQL 会缓存一定数量的客户服务线程以备重用,通过参数 thread_cache_size 可控制 MySQL 缓存客户服务线程的数量。
5)lock_wait_timeout
innodb_lock_wait_timeout
事务等待行锁的时间
该参数是用来设置InnoDB 事务等待行锁的时间,默认值是50ms , 可以根据需要进行动态设置。对于需要快速反馈的业务系统来说,可以将行锁的等待时间调小,以避免事务长时间挂起; 对于后台运行的批量处理程序来说, 可以将行锁的等待时间调大, 以避免发生大的回滚操作。
本文由传智教育博学谷 - 狂野架构师教研团队发布
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力
转载请注明出处!
来源:https://www.cnblogs.com/jiagooushi/p/16493746.html
本站部分图文来源于网络,如有侵权请联系删除。