 百木园
百木园python爬虫基本概述
一、爬虫是什么
网络爬虫(Crawler)又称网络蜘蛛,或者网络机器人(Robots). 它是一种按照一定的规则, 自动地抓取万维网信息的程序或者脚本。换句话来说,它可以根据网页的链接地址自动获取网页 内容。如果把互联网比做一个大蜘蛛网,它里面有许许多多的网页,网络蜘蛛可以获取所有网页 的内容。
爬虫是一个模拟人类请求网站行为, 并批量下载网站资源的一种程序或自动化脚本。
二、爬虫可以做什么
1. 搜索引擎
2. 采集金融数据
3. 采集商品数据
4. 采集竞争对手的客户数据
5. 采集行业相关数据,进行数据分析
6. 刷流量
三、爬虫的分类
1、通用网络爬虫 又称为全网爬虫,其爬取对象由一批 URL 扩充至整个 Web,主要由搜索引擎或大型 Web 服 务商使用。
2、聚焦网络爬虫 又称为主题网络爬虫,其特点是只选择性的地爬取与预设的主题相关的页面,相比通用网 络爬虫,聚焦网络爬虫仅需要爬取与主题相关的页面,极大地节省硬件及网络资源,能更 快的更新保存页面,更好的满足特定人群对特定领域的需求。
3、增量网络爬虫 只对已下载的网页采取增量式更新,或只爬取新产生的及已经发生变化的网页,这种机制 能够在某种程度上保证所爬取的网页尽可能的新。
4、深度网络爬虫 Web 页面按照存在的方式可以分为表层页面和深层页面两类。表层页面是只传统搜索引擎 可以索引到的页面,以超链接可以达到的静态页面为主。深层页面是指大部分内容无法通 过静态链接获取,隐藏在搜索表单之后的,需要用户提交关键词后才能获得的 Web 页面, 如一些登陆后可见的网页。
四、爬虫的基本流程
1、浏览网页的流程
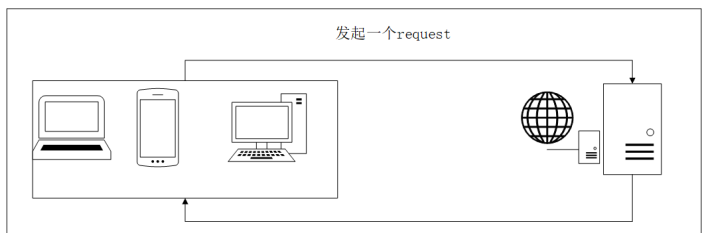
2 、爬虫的基本流程
1. 请求网页 通过 HTTP 库向目标站点发起请求,即发送一个 Request,请求可以包含额外的 headers 等 信息,等待服务器响应!
2. 获得相应内容 如果服务器能正常响应,会得到一个 Response,Response 的内容便是所要获取的页面内容, 类型可能有 HTML,Json 字符串,二进制数据(如图片视频)等类型。
3. 解析内容 得到的内容可能是 HTML,可以用正则表达式、网页解析库进行解析。可能是Json,可以 直接转为 Json 对象解析,可能是二进制数据,可以做保存或者进一步的处理。
4. 存储解析的数据 保存形式多样,可以存为文本,也可以保存至数据库,或者保存特定格式的文件
3 、爬虫的测试案例
爬取搜狗首页的页面数据
# 导包 import requests # step_1 : 指定url url =\'https://www.sogou.com/\' # step_2 : 发起请求: # 使用get 方法发起get 请求, 该方法会返回一个响应对象。参数url 表示请求对应的url response = requests.get ( url = url ) # step_3 : 获取响应数据: # 通过调用响应对象的text 属性, 返回响应对象中存储的字符串形式的响应数据( 页面源码数据) page_text = response . text # step_4 : 持久化存储 with open (\'sogou.html\',\'w\',encoding =\'utf -8\') as fp: fp.write (page_text) print (\'爬取数据完毕! ! !\')

得到sogou.html
来源:https://www.cnblogs.com/liuyebai/p/16844258.html
本站部分图文来源于网络,如有侵权请联系删除。