 百木园
百木园数据清洗
数据清洗是对一些没有用的数据进行处理的过程。
很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。
在这个教程中,我们将利用 Pandas包来进行数据清洗。
处理丢失数据
-
有两种丢失数据:
- None
- np.nan(NaN)
-
两种丢失数据的区别

-
为什么在数据分析中需要用到的是浮点类型的空而不是对象类型?
- 数据分析中会常常使用某些形式的运算来处理原始数据,如果原数数据中的空值为NAN的形式,则不会干扰或者中断运算。
- NAN可以参与运算的
- None是不可以参与运算
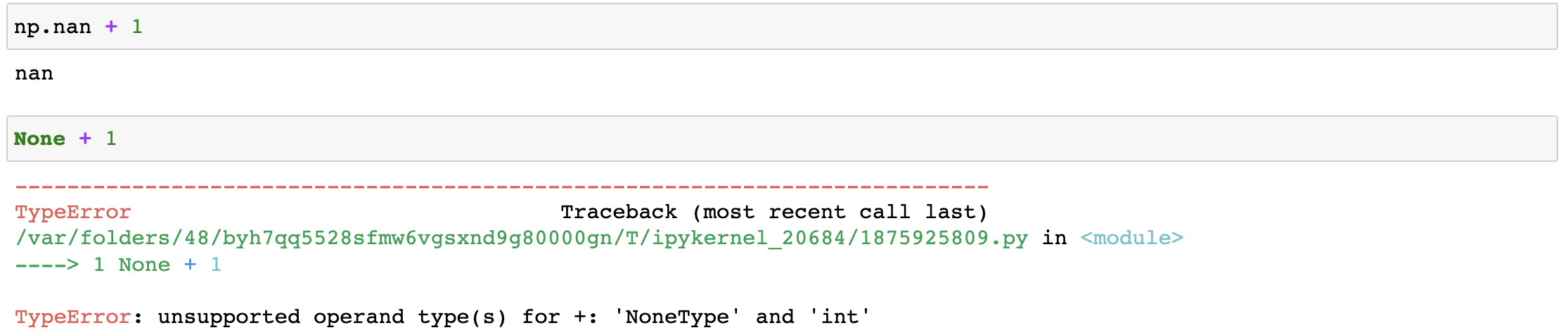
-
在pandas中如果遇到了None形式的空值则pandas会将其强转成NAN的形式。
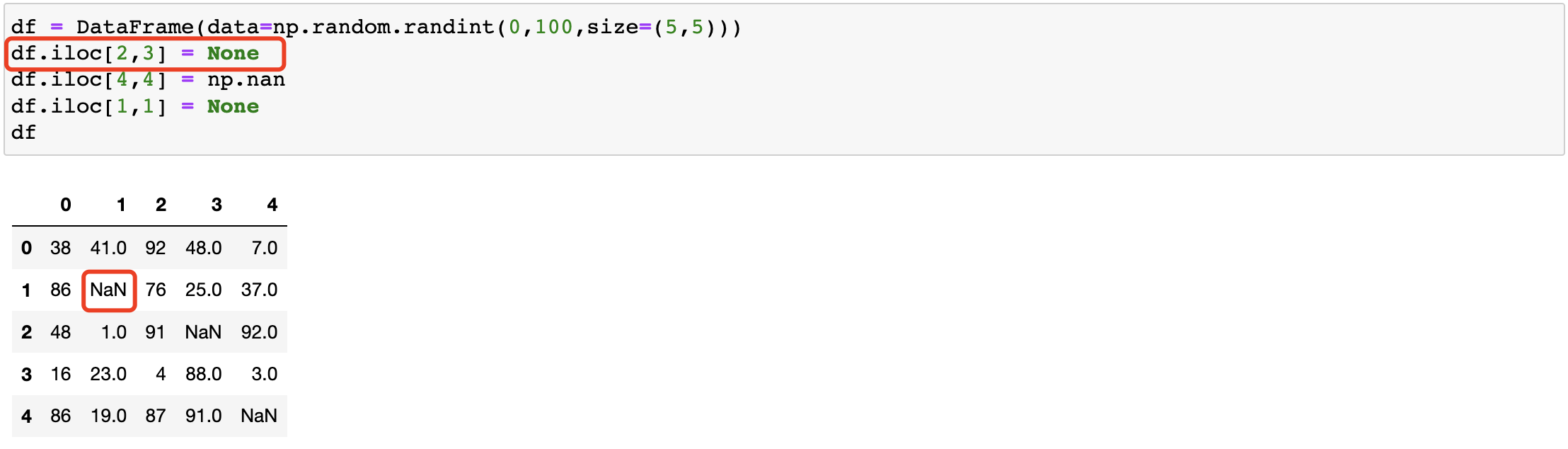



pandas处理空值操作
- isnull
- notnull
- any
- all
- dropna
- fillna
-
方式1:对空值进行过滤(删除空所在的行数据)
- 技术:isnull,notnull,any,all
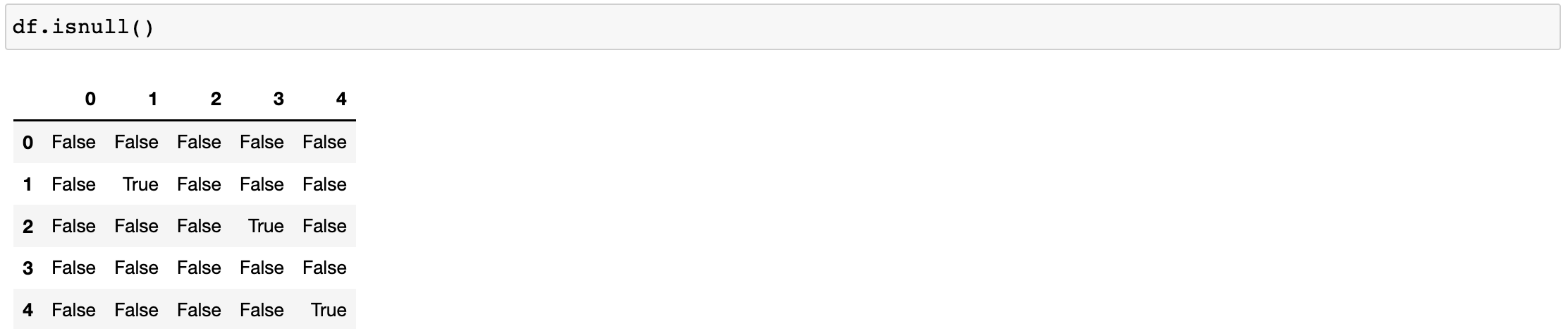
#哪些行中有空值 #any(axis=1)检测哪些行中存有空值 df.isnull().any(axis=1) #any会作用isnull返回结果的每一行 #true对应的行就是存有缺失数据的行
df.notnull()
df.notnull().all(axis=0) #all 只要有false,则整体就是false
#将布尔值作为源数据的行索引 df.loc[df.notnull().all(axis=1)]
-
方式2:
-
dropna:可以直接将缺失的行或者列进行删除

-
对缺失值进行覆盖
- fillna
df.fillna(value=999) #使用指定值将源数据中所有的空值进行填充
#使用空的近邻值进行填充 #method=ffill向前填充,bfill向后填充 df.fillna(axis=0,method=\'bfill\')
-
-
什么时候用dropna什么时候用fillna
- 尽量使用dropna,如果删除成本比较高,则使用fillna
-
使用空值对应列的均值进行空值填充
for col in df.columns: #检测哪些列中存有空值 if df[col].isnull().sum() > 0:#说明df[col]中存有空值 mean_value = df[col].mean() df[col] = df[col].fillna(value=mean_value)









面试题
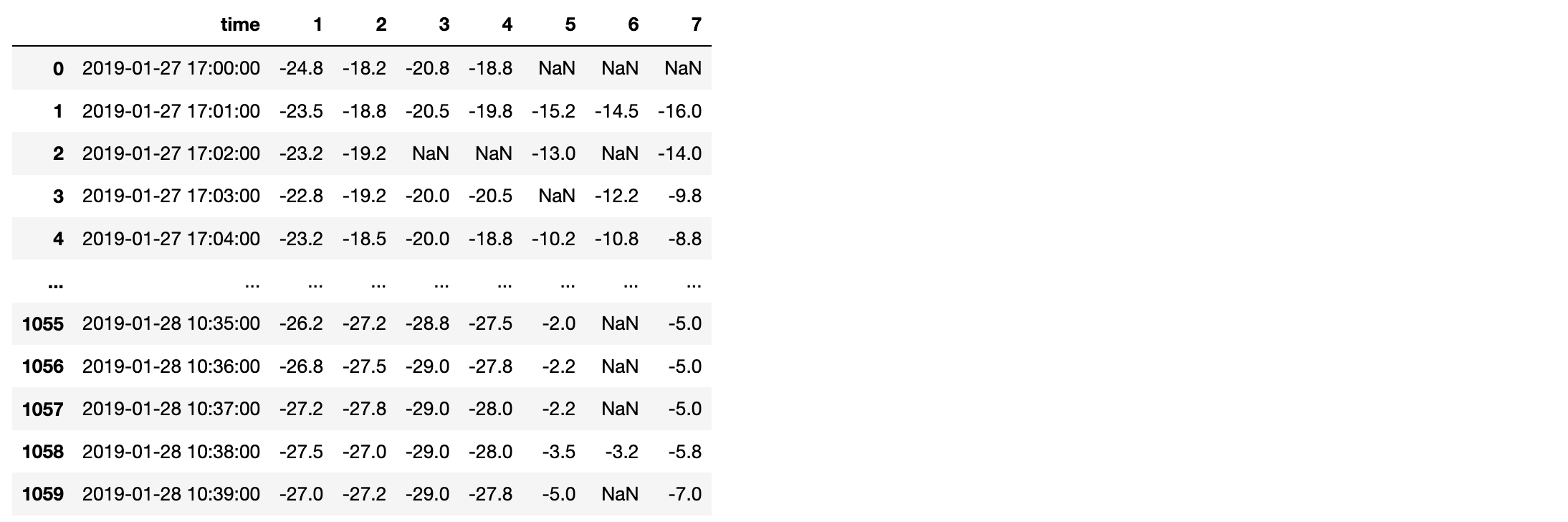
- 数据说明:
- 数据是1个冷库的温度数据,1-7对应7个温度采集设备,1分钟采集一次。
- 数据处理目标:
- 用1-4对应的4个必须设备,通过建立冷库的温度场关系模型,预估出5-7对应的数据。
- 最后每个冷库中仅需放置4个设备,取代放置7个设备。
- f(1-4) --> y(5-7)
- 数据处理过程:
- 1、原始数据中有丢帧现象,需要做预处理;
- 2、matplotlib 绘图;
- 3、建立逻辑回归模型。
- 无标准答案,按个人理解操作即可,请把自己的操作过程以文字形式简单描述一下,谢谢配合。
- 测试数据为testData.xlsx
Data:
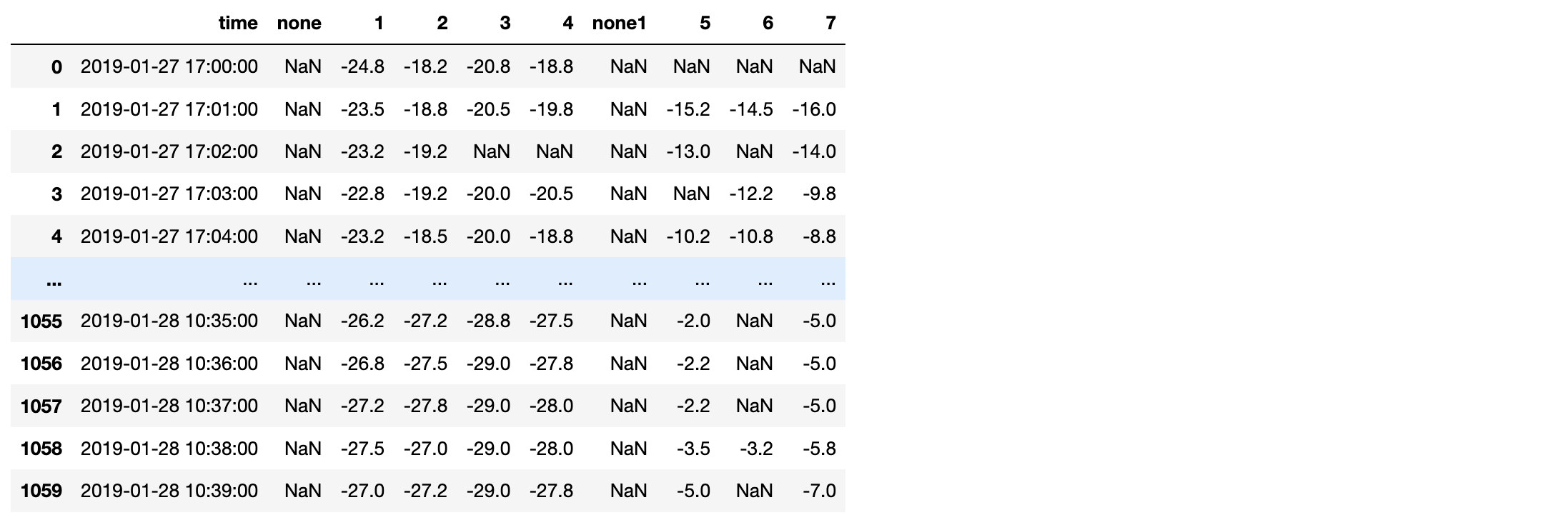
- 丢帧预处理:
清洗掉none,none1列df.drop(label=[\'none\',\'none1\'],axis=1)
-
删掉空值所在的行
#删除空对应的行数据 data.dropna(axis=0)
处理重复数据

#检测哪些行存有重复的数据
df.duplicated(keep=\'first\')

第1行之所以是false,是因为keep保留了第一个出现的数据,但是3,5行就不保留了。如果keep=last,则保留最后一行数据;keep=false则删除所有数据
df.drop_duplicates(keep=\'first\')删除重复数据

处理异常数据
-
自定义一个1000行3列(A,B,C)取值范围为0-1的数据源,然后将C列中的值大于其两倍标准差的异常值进行清洗
df = DataFrame(data=np.random.random(size=(1000,3)),columns=[\'A\',\'B\',\'C\'])
-
判定条件:c值大于本列的方差的2倍,则为异常数据
#制定判定异常值的条件 twice_std = df[\'C\'].std() * 2 twice_stddf[\'C\'] > twice_std --> 异常值所在列 ~df[\'C\'] > twice_std --> 取反操作 df.loc[~(df[\'C\'] > twice_std)] --> 通过定位非异常值索引来获取正常值


本文来自博客园,作者:ivanlee717,转载请注明原文链接:https://www.cnblogs.com/ivanlee717/p/16993650.html
来源:https://www.cnblogs.com/ivanlee717/p/16993650.html
本站部分图文来源于网络,如有侵权请联系删除。