 百木园
百木园一、安装Spark
检查基础环境hadoop,jdk

下载spark

配置相关文件

配置环境变量


启动spark并运行python代码
def load_file(word_freq): # 读文件到缓冲区
try: # 打开文件
f = open(intext, \'r\')
except IOError as s:
print(s)
return None
try: # 读文件到缓冲区
bvffer = f.read()
except:
print(\"ERROR!!\")
return None
f.close()
if bvffer:
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
bvffer = bvffer.lower()
for ch in \'“‘!;,.?”\':
bvffer = bvffer.lower().replace(ch, \" \") #将所有字母转换成小写,便于统计
words = bvffer.strip().split() #strip消除空白符,split以空格作为单词分界
for word in words:
word_freq[word] = word_freq.get(word, 0)+1 #读取到的单词存放到字典
return word_freq
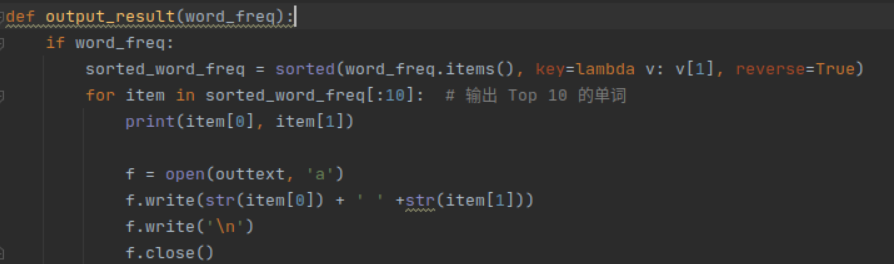
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print(item[0], item[1])
f = open(outtext, \'a\')
f.write(str(item[0]) + \' \' +str(item[1]))
f.write(\'\\n\')
f.close()
if __name__ == \"__main__\":
word_freq = {}
intext = \"text.txt\"
outtext = \'outtext.txt\'
a = load_file(word_freq)
output_result(a)
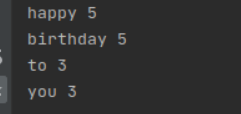
二、Python编程练习:英文文本的词频统计
1、准备文本
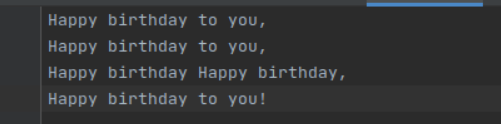
2、预处理:大小写,标点符号,停用词

3、统计每个单词出现的次数

4、结果写文件
来源:https://www.cnblogs.com/144lqf/p/15970113.html
本站部分图文来源于网络,如有侵权请联系删除。