 百木园
百木园前言
其中的过程适用于静态网页(豆瓣电影信息、哔哩哔哩评论区等)、动态页面(百度图片滚轮触发页面更新、下拉框触发页面更
新等url不变但通过鼠标互动,致使信息更新等场景)的信息爬取。
基本适用于所有网页信息的爬取,但代码不够简洁,下述流程不够详细。

1 Selenium安装
Python学习交流Q群:906715085#### (1)pip install selenium (2)以edge为例,安装驱动。url:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/ (3)Selenium的网页信息定位主要使用xpath表达式,需要对其有所了解,利用edge中的扩展,可以极大的简化定位过程,但是不能取代个人工作,还是要对xpath有所了解,扩展如图1。

2 案例:以经合组织(OECD)为例,如图1
url: https://stats.oecd.org/Index.aspx?DataSetCode=CS_BAROMETER#

最终结果:
原页面数据:
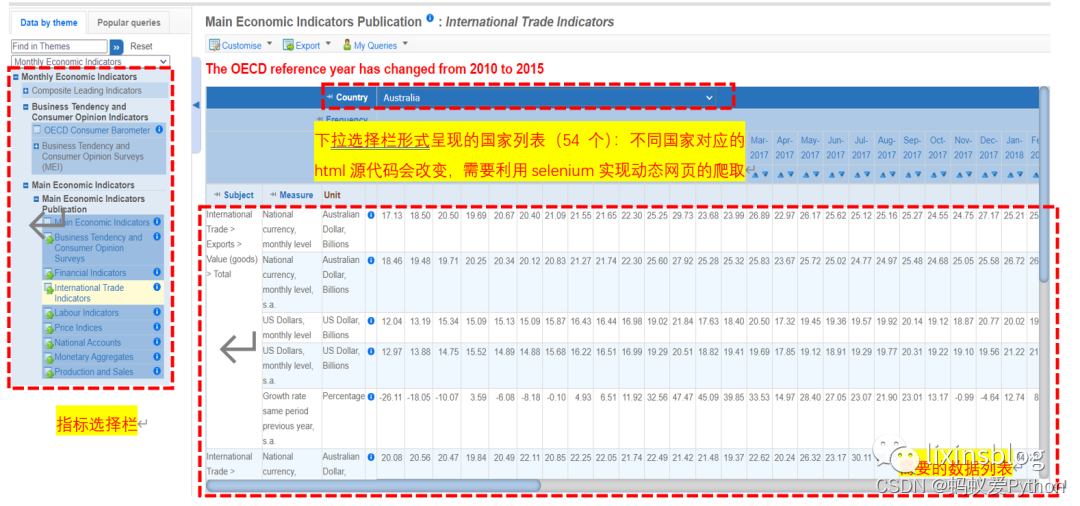
爬取到的数据(简洁起见,以international trade index为例,但是爬取的各个过程均有涉及,其他指标、数据以及网页只要做简单
推广即可,这个流程基本可以实现所有网页信息的爬取):

3 流程
(1)需要的python库;

(2)获取初始网页;

(3)展开指标栏,并选取international trade index;
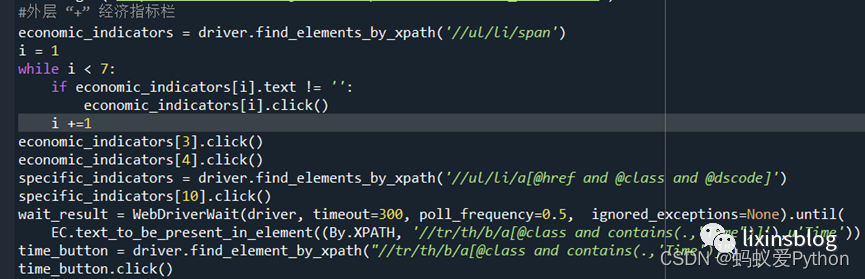

(4)将时间定位到2021年,其余时间不要;
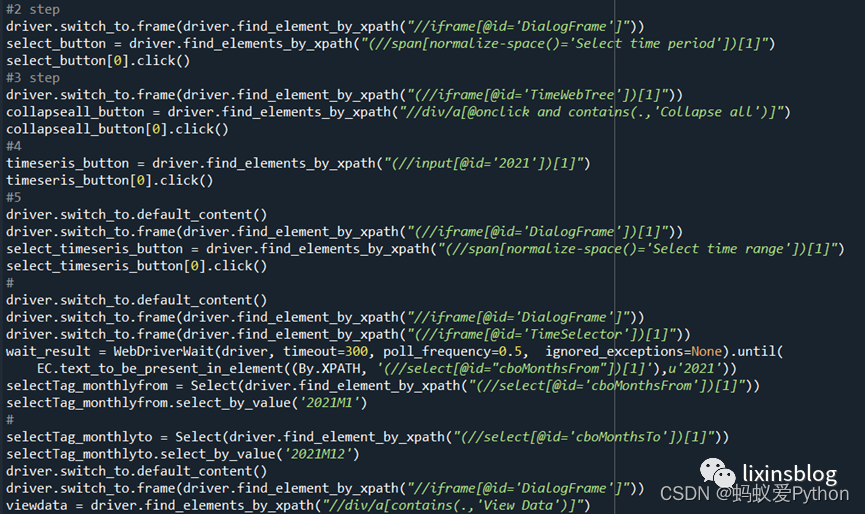
(5)获取表头:年月/国家信息;

(6)获取指标信息;
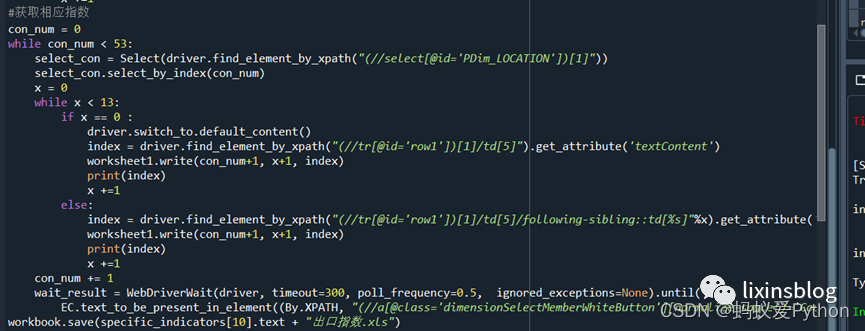
Notice:
1.注意隐藏数据。利用xpth定位源代码时,明明没有任何问题,但python报错,显示无此元素,此时应注意是否是隐藏元素,查看是否在iframe内,上述代码中对这一问题做了处理;
2.注意每个网页的刷新时间,需根据时间设置time.sleep或者WebDriverWait;
来源:https://www.cnblogs.com/123456feng/p/16119428.html
本站部分图文来源于网络,如有侵权请联系删除。