 百木园
百木园Python爬虫鲁迅先生《经典语录》保存到Excel表格(附源码)
前言
今天用Python 爬取鲁迅先生《经典语录》,直接开整~
代码运行效果展示

开发工具
Python版本: 3.6.4
相关模块
requests
lxml
pandas
以及Python自带的模块
思路分析
1、获取数据

通过“好句子迷”网站,获取网页。
http://www.shuoshuodaitupian.com/writer/128_1
利用request模块,通过URL链接,获取html网页,下一步进行网页分析。
其中,URL只有最后一部分发生改变(1-10 :代表第1页--第10页的全部内容)
# 1、获取数据
headers = {\"user-agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) \" \\
\"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36\",
}
for i in range(0, 9):
url = \"http://www.shuoshuodaitupian.com/writer/128_\" + str(i + 1) # 1-10页
result = requests.get(url, headers=headers).content.decode()
2、解析数据
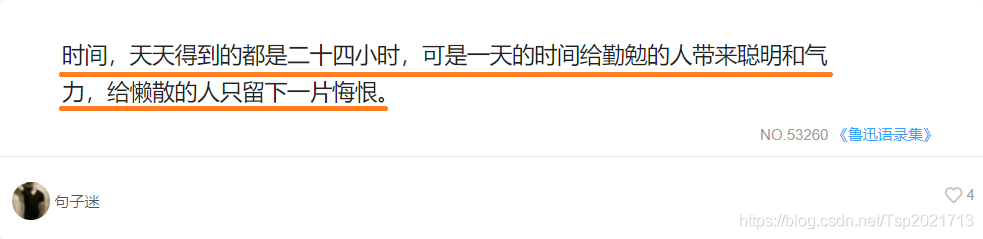
通过Xpath语句解析,分别获取句子的内容、来源和评分等,如图所示。
把获取的每一组数据,放在一个字典里,再把字典追加到一个列表中。
源码:
# 2、解析数据
html = etree.HTML(result)
div_list = html.xpath(\'//div[@class=\"item statistic_item\"]\')
div_list = div_list[1:-1]
for div in div_list:
# 遍历每一条信息
item = {}
# ./ 注意从当前节点,向下获取
item[\'content\'] = div.xpath(\'./a/text()\')[0]
item[\'source\'] = div.xpath(\'./div[@class=\"author_zuopin\"]/text()\')[0]
item[\'score\'] = div.xpath(\'.//a[@class=\"infobox zan like \"]/span/text()\')[0]
item_list.append(item)
print(\"正在爬取第{}页\".format(i + 1))
time.sleep(0.1)
保存数据:
把上述获取的数据放到一个列表中后,可通过pandas模块把数据类型转变为DataFrame,进而可以轻松地保存到excel文件中。
为防止中文乱码,注意编码格式。
3、保存数据
df = pd.DataFrame(item_list) # 把数据存成csv文件
df.to_csv(\'鲁迅经典语录.csv\', encoding=\'utf_8_sig\') # 保证不乱码
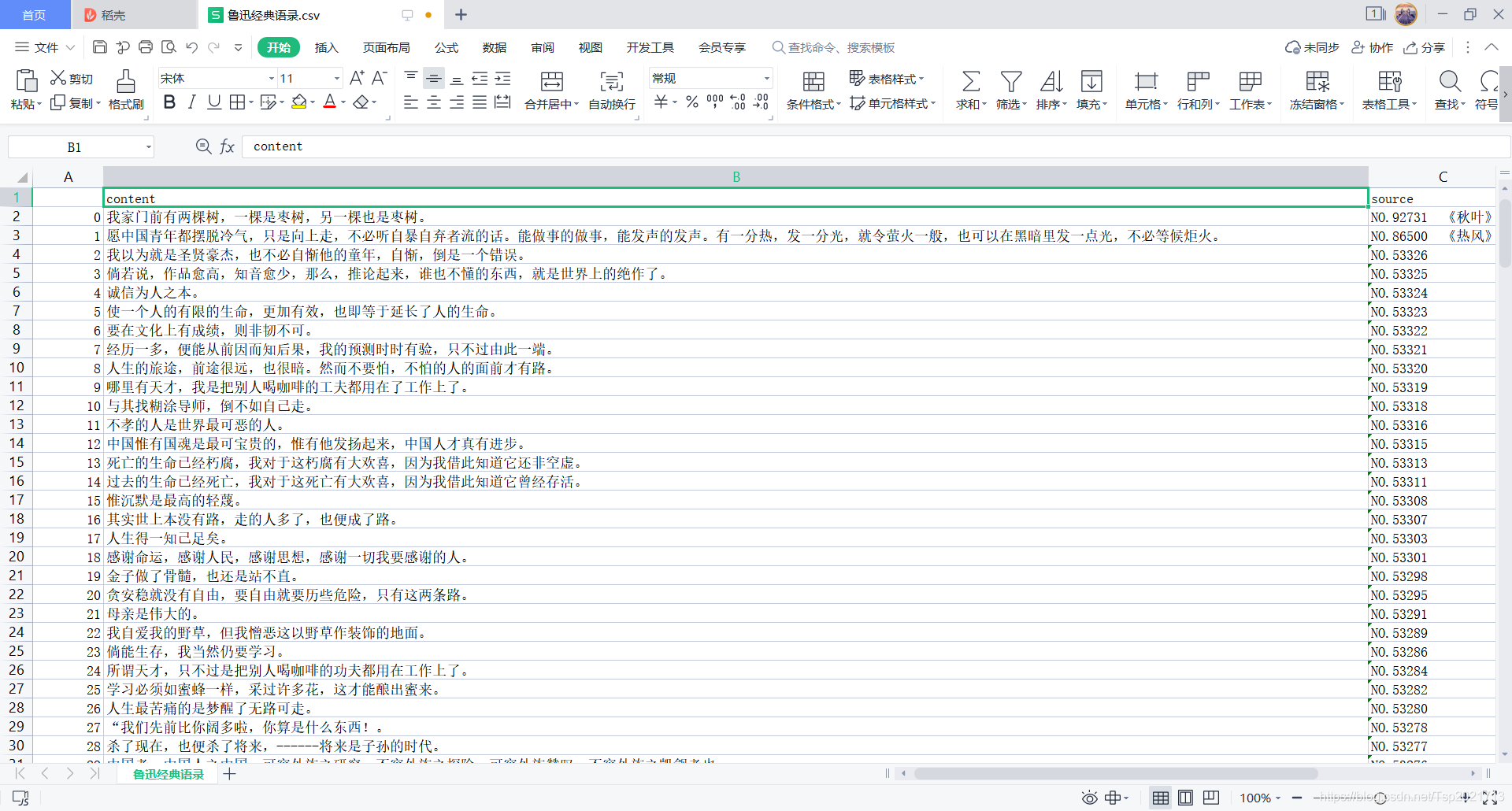
按照评分进行排序之后的结果,如下图。
如果想生成多条个人信息,可以利用for循环,把每个字典在添加到列表里,导出一个DataFrame
文章到这里就结束了,感谢你的观看,Python数据分析系列,下篇文章分享Python 爬取鲁迅先生《经典语录》
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
⑥ 两天的Python爬虫训练营直播权限
All done~详见个人简介或者私信获取完整源代码。。
往期回顾
Python实现“假”数据
来源:https://www.cnblogs.com/tsp728/p/15147877.html
图文来源于网络,如有侵权请联系删除。