 百木园
百木园前言
微服务治理方案中,链路追踪是必修课,SpringCloud的组件其实使用很简单,生产环境中真正令人头疼的往往是软件维护,接口在微服务间的调用究竟哪个环节出现了问题,哪个环节耗时较长,这都是项目上线后一定会遇到的问题,为了解决这些问题链路追踪便应运而生了。
主流方案
1)、SkyWalking:这应该是目前最主流的方案了,我所在公司今年的新项目就开始使用这个,效果确实很显著,功能强大,最重要还是国产的,后面不用看了我们支持国产吧!开个玩笑哈哈,其实这个框架也有缺点,就是稍微有点重,比较适合稍大一点的项目,但可预见后面几年都是最受欢迎的方案;
2)、Zipkin:这个是老牌链路追踪方案,已经被非常多项目验证过实用性,相比较于SkyWalking,我个人更喜欢这个框架,因为更轻量级,安装也非常简单,是中小规模的微服务项目首选方案。
用法
1、zipkin环境搭建
官方提供了docker版本,十分简单。也可以下载编译好的zipkin.jar来运行,是springboot项目。
官网:https://zipkin.io/pages/quickstart.html
1)、启动
默认端口号启动zipkin服务,默认端口9411.
java -jar zipkin.jar
2)、指定端口号
java -jar zipkin.jar --server.port=8080
3)、指定访问RabbitMQ
java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=127.0.0.1
4)、启动效果
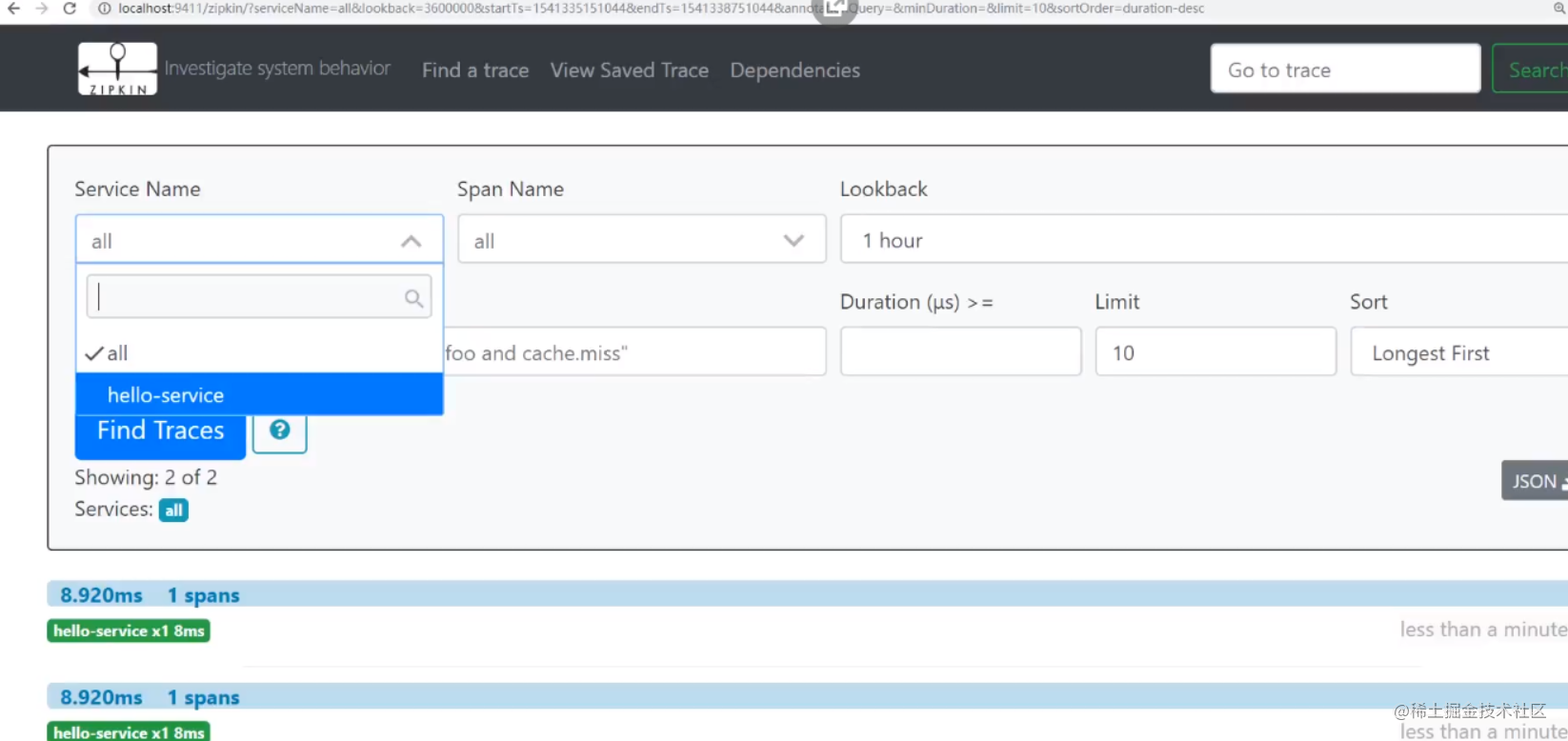
2、SpringCloud整合zipkin
springcloud其它基础依赖包引入这里省略,直接模拟场景。
会员服务:zipkin_member
订单服务:zipkin_order
消息服务:zipkin_msg
过程:会员服务调用订单服务,订单服务调用消息服务。
1)、引入依赖
<!-- zipkin -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
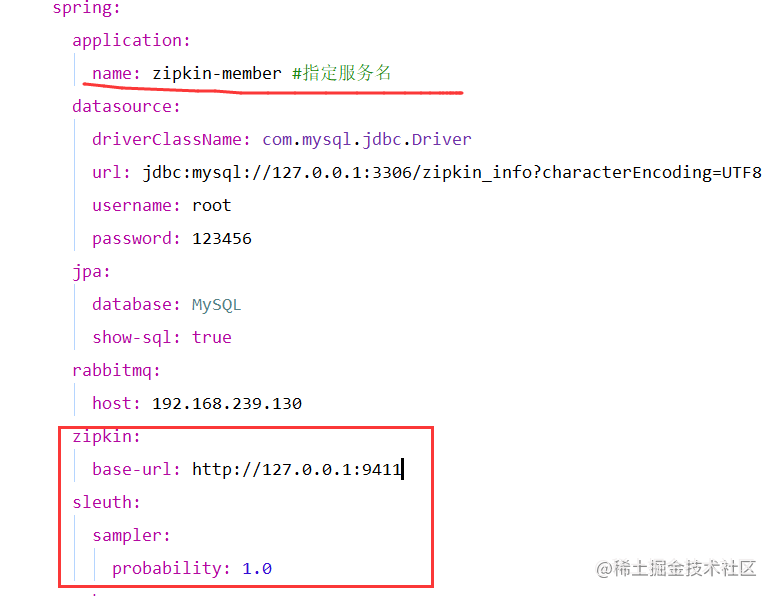
2)、application.yml配置
注意事项:
a)、加上服务名,RestTemplate调用时会用到;
b)、加上zipkin服务端地址;
c)、加上probability采集率设置,默认0.1,测试环境改为1.0保证每次都采集,生产环境适当抽样即可。(因为10000个请求抽样1000个也能发现问题了,没必要全部都采集)
3)、引入RestTemplate
这里restTemplate主要用来进行接口调用查看链路追踪是否生效
@Component
public class RestTemplateConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
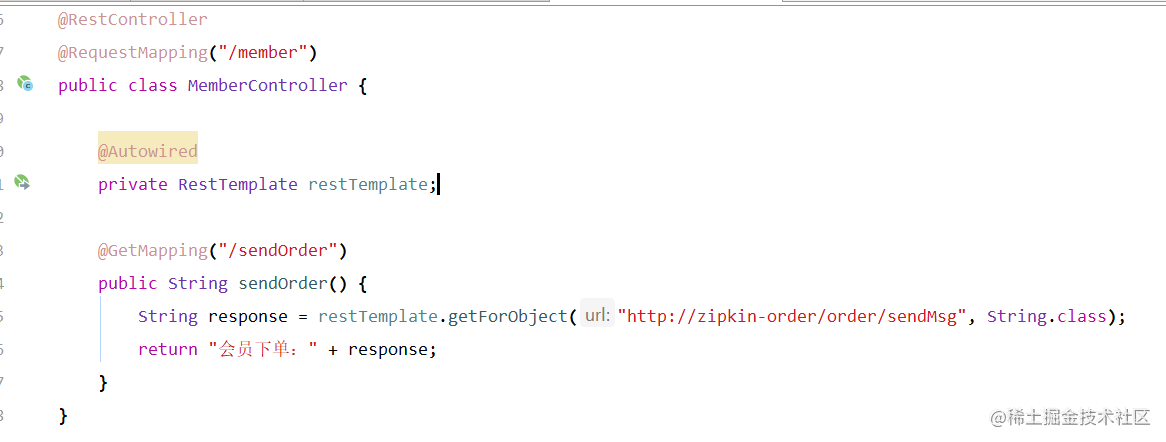
4)、controller调用
会员调用订单
订单调用消息
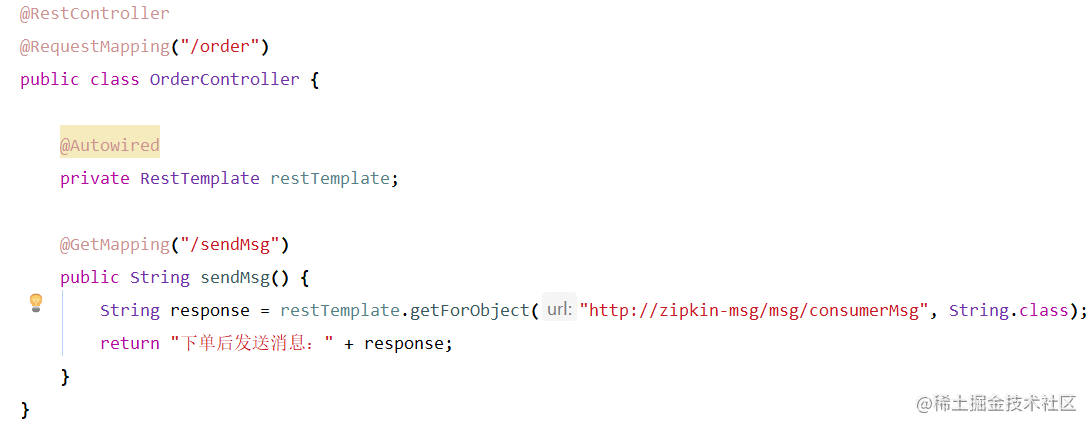
消息处理具体业务

5)、查看效果
启动Zipkin服务端,访问:http://127.0.0.1:9411
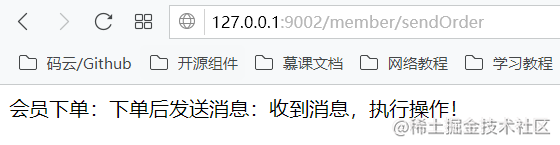
执行controller接口
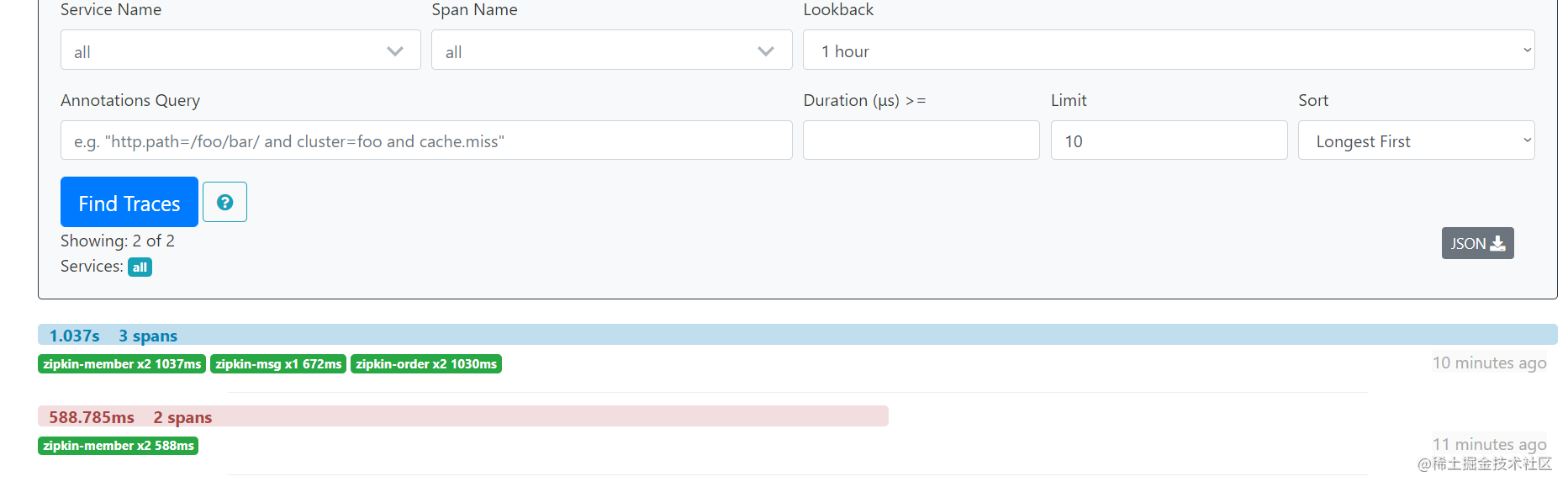
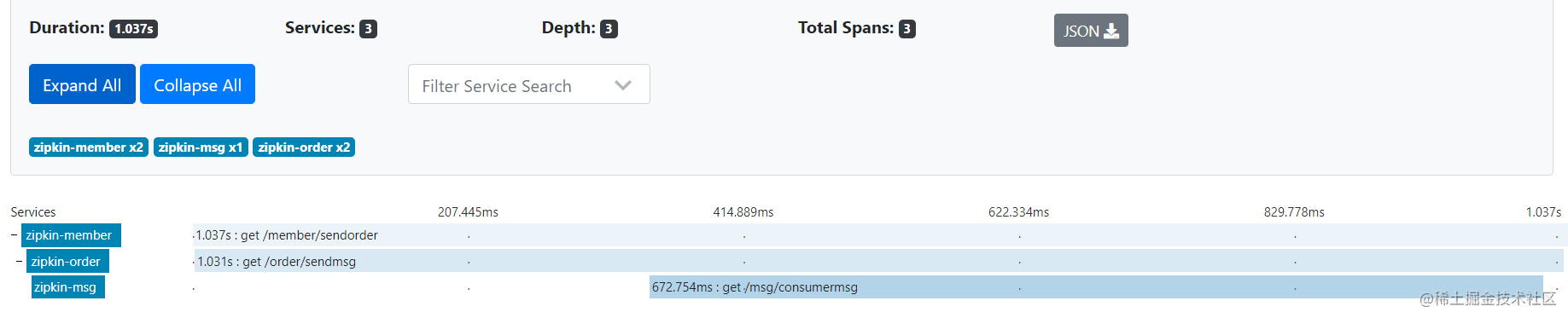
查看链路追踪,可以看到,接口调用的链路已经在zipkin显现了。
3、zipkin整合RabbitMQ异步采集
springboot2.0之后,官方不再推荐使用自建的zipkin server,而是直接使用编译好的zipkin.jar来给我们使用。
zipkin.jar中的yml配置可以参考:https://github.com/openzipkin/zipkin/blob/master/zipkin-server/src/main/resources/zipkin-server-shared.yml
1)、指定RabbitMQ为服务器
启动zipkin服务时指定rabbitmq为服务器即可,得先启动rabbitmq服务器。
java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=192.168.239.132
启动之后,可以发现rabbitmq中会自动新增一个zipkin队列,表示绑定成功。

2)、引入中间依赖
给每个微服务引入stream和rabbitmq的中间件依赖
<!-- 引入和rabbitmq的中间依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
3)、yml配置
修改每个微服务的application.yml,加上rabbitmq的配置。
rabbitmq:
host: 192.168.239.132
port: 5672
username: guest
password: guest
4)、启动和调用
启动微服务,执行调用。
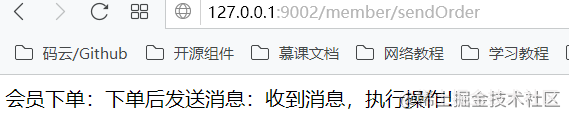
5)、MQ是否收到消息
看rabbitmq是否有收消息,队列有反应说明rabbitmq收到消息了。

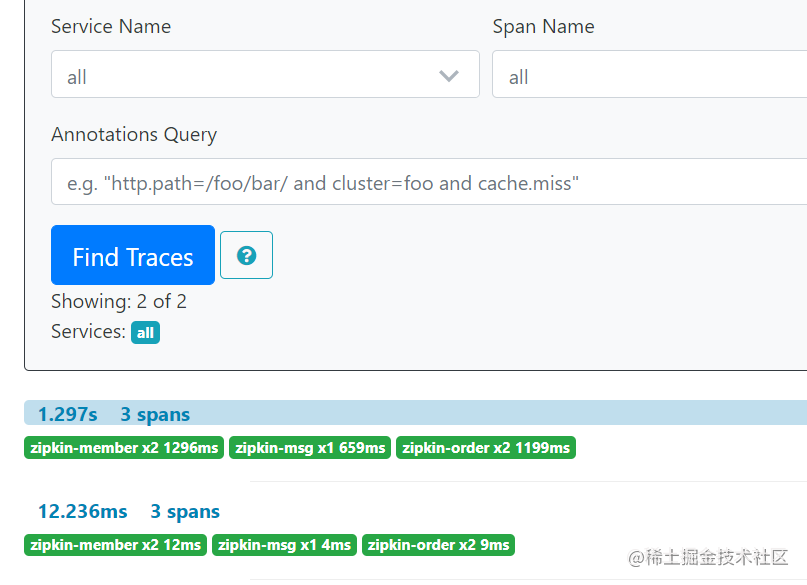
6)、Zipkin是否采集信息
看zipkin是否采集了链路信息
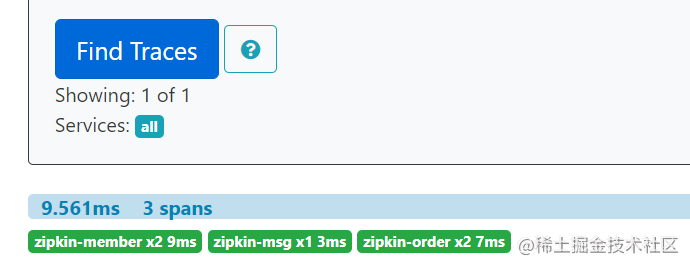
7)、验证积压消息
关掉zipkin服务,看消息是否会积压在rabbitmq,再启动zipkin服务,看消息是否会被消费并且获取到链路信息。

获取消息查看,发现获取到的就是traceId相关的json数据,证明整个过程都是正常的。

重新再启动zipkin服务,发现rabbitmq积压的消息就被消费了。

并且也能获取到链路信息
4、zipkin使用MySQL存储
zipkin.jar中的yml配置可以参考,里面有关于mysql的配置或者其他如elasticsearch的配置:
https://github.com/openzipkin/zipkin/blob/master/zipkin-server/src/main/resources/zipkin-server-shared.yml
这节我们在上一节MQ的基础上增加MySQL的启动配置项
1)、指定MySQL
命令看着很长,其实仔细看发现很简单,都是见名知义,不必死记硬背。
java -jar zipkin.jar
--zipkin.collector.rabbitmq.addresses=192.168.239.132
--zipkin.storage.type=mysql
--zipkin.storage.mysql.host=127.0.0.1
--zipkin.storage.mysql.port=3306
--zipkin.storage.mysql.username=root
--zipkin.storage.mysql.password=123456
--zipkin.storage.mysql.db=zipkin
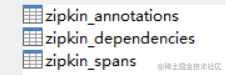
2)、创建zipkin数据库
根据1中命令配置的信息,创建zipkin数据库,并执行语句创建zipkin采集记录的三张表。
参考官网:https://github.com/apache/incubator-zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
这里我也贴出来 zipkin-mysql.sql
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT \'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit\',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`remote_service_name` VARCHAR(255),
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT \'Span.timestamp(): epoch micros used for endTs query and to implement TTL\',
`duration` BIGINT COMMENT \'Span.duration(): micros used for minDuration and maxDuration query\',
PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT \'for getTracesByIds\';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT \'for getTraces and getSpanNames\';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT \'for getTraces and getRemoteServiceNames\';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT \'for getTraces ordering and range\';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT \'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit\',
`trace_id` BIGINT NOT NULL COMMENT \'coincides with zipkin_spans.trace_id\',
`span_id` BIGINT NOT NULL COMMENT \'coincides with zipkin_spans.id\',
`a_key` VARCHAR(255) NOT NULL COMMENT \'BinaryAnnotation.key or Annotation.value if type == -1\',
`a_value` BLOB COMMENT \'BinaryAnnotation.value(), which must be smaller than 64KB\',
`a_type` INT NOT NULL COMMENT \'BinaryAnnotation.type() or -1 if Annotation\',
`a_timestamp` BIGINT COMMENT \'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp\',
`endpoint_ipv4` INT COMMENT \'Null when Binary/Annotation.endpoint is null\',
`endpoint_ipv6` BINARY(16) COMMENT \'Null when Binary/Annotation.endpoint is null, or no IPv6 address\',
`endpoint_port` SMALLINT COMMENT \'Null when Binary/Annotation.endpoint is null\',
`endpoint_service_name` VARCHAR(255) COMMENT \'Null when Binary/Annotation.endpoint is null\'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT \'Ignore insert on duplicate\';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT \'for joining with zipkin_spans\';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT \'for getTraces/ByIds\';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT \'for getTraces and getServiceNames\';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT \'for getTraces and autocomplete values\';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT \'for getTraces and autocomplete values\';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT \'for dependencies job\';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT,
PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
3)、效果
启动微服务,执行controller请求,看是否成功。
RabbitMQ
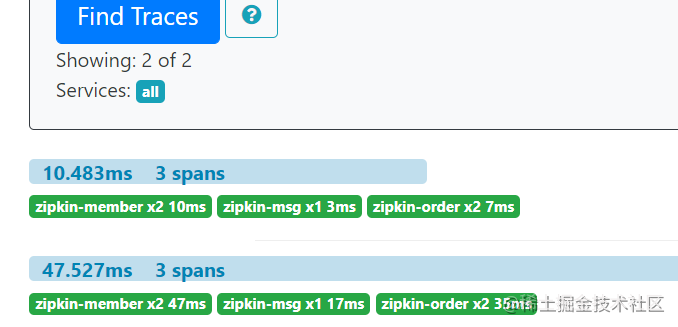
zipkin
MySQL

至此,springcloud sleuth + zipkin + rabbitmq + mysql 就全部整合成功了!
总结
微服务的治理方案有很多,学习方向根据个人喜好决定,我的经验就是不必盲目跟从这种用于辅助的方案,比如现在有SkyWalking,以后可能还有SkyFlying、SkySwimming。
走向高级软件工程师都要有一个意识,就是在层出不穷的开源框架如雨后春笋般出现的时候,你得有信心用到哪个花点时间就能自己搭建起来,这才是提升自己的最有效方法。
一个项目使用什么治理方案最重要的绝不是跟风,而是哪款最适合就用哪款,就像你找女朋友一样,不单单是找漂亮的,而是找最能一起过日子的,否则就是貌合神离。
分享
本篇实际上是我8年多工作及学习过程中在云笔记中记录的内容之一,其实还有很多我闲暇之余都做了下整理,有感兴趣的朋友可以私信我获取,什么时候用到了翻开说不定就能节省很多时间。
本人原创文章纯手打,专注于分享主流技术及实际工作经验,觉得有一滴滴帮助的话就请点个推荐吧!
喜欢就点一下推荐吧~~
来源:https://www.cnblogs.com/fulongyuanjushi/p/16292756.html
本站部分图文来源于网络,如有侵权请联系删除。