 百木园
百木园1 前言
近期随着数据量的增长,数据库CPU使用率100%报警频繁起来。第一个想到的就是慢Sql,我们对未合理运用索引的表加入索引后,问题依然没有得到解决,深入排查时,发现在 order by id asc limit n时,即使where条件已经包含了覆盖索引,优化器还是选择了错误的索引导致。通过查询大量资料,问题得到了解决。这里将解决问题的思路以及排查过程分享出来,如果有错误欢迎指正。
2 正文
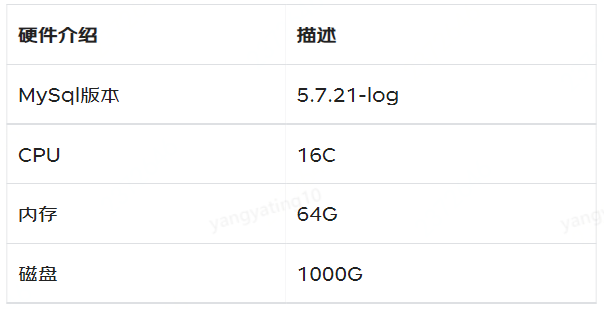
2.1 环境介绍
2.2 发现问题
22日开始,收到以下图1报警变得频繁起来,由于数据库中会有大数据推数动作,数据库CPU偶尔报警并没有引起对该问题的重视,直到通过图2对整日监控数据分析时,才发现问题的严重性,从0点开始,数据库CPU频繁被打满。

图1:报警图

图2:整日CPU监控图
2.3 排查问题
发现问题后,开始排查慢Sql,发现很多查询未添加合适的索引,经过一轮修复后,问题依然没有得到解决,在深入排查时发现了一个奇怪现象,SQL代码如下(表名已经替换),比较简单的一个单表查询语句。
SELECT * FROM test WHERE is_delete = 0 AND business_day = \'2021-12-20\' AND full_ps_code LIKE \'xxx%\' AND id > 2100 ORDER BY id LIMIT 500;
看似比较简单的查询,但执行时长平均在90s以上,并且调用频次较高。如图3所示。

图3:慢Sql平均执行时长
开始检查表信息,可以看到表数据量在2100w左右。

图4:数据表情况
排查索引情况,主键为id,并且有business_day与full_ps_code的联合索引。
PRIMARY KEY (`id`) USING BTREE, KEY `idx_business_day_full_ps_code` (`business_day`,`full_ps_code`) ==========以下索引可以忽略======== KEY `idx_erp_month_businessday` (`erp`,`month`,`business_day`), KEY `idx_business_day_erp` (`business_day`,`erp`), KEY `idx_erp_month_ps_plan_id` (`erp`,`month`,`ps_performance_plan_id`), ......
通过Explain查看执行计划时发现,possible_keys中包含上面的联合索引,而Key却选择了Primary主键索引,扫描行数Rows为1700w,几乎等于全表扫描。

图5:执行计划情况
2.4 解决问题
第一次,我们分析是,由于Where条件中包含了ID,查询分析器认为主键索引扫描行数会少,同时根据主键排序,使用主键索引会更加合理,我们试着添加以下索引,想要让查询分析器命中我们新加的索引。
ADD INDEX `idx_test`(`business_day`, `full_ps_code`, `id`) USING BTREE;
再次通过Explain语句进行分析,发现执行计划完全没变,还是走的主键索引。
explain SELECT * FROM test WHERE is_delete = 0 AND business_day = \'2021-12-20\' AND full_ps_code LIKE \'xxx%\' AND id > 2100 ORDER BY id LIMIT 500;

图6:执行计划情况
第二次,我们通过强制指定索引方式 force index (idx_test)方式,再次分析执行情况,得到图7的结果,同样的查询条件同样的结果,查询时长由90s->0.49s左右。问题得到解决

图7:强制指定索引后执行计划情况

第三次,我们怀疑是where条件中有ID导致直接走的主键索引,where条件中去掉id,Sql调整如下,然后进行分析。依然没有命中索引,扫描rows变成111342,查询时间96s
SELECT * FROM test WHERE is_delete = 0 AND business_day = \'2021-12-20\' AND full_ps_code LIKE \'xxx%\' ORDER BY id LIMIT 500


第四次,我们把order by去掉,SQL调整如下,然后进行分析。命中了idx_business_day_full_ps_code之前建立的联合索引。扫描行数变成154900,查询时长变为0.062s,但是发现结果与预想的不一致,发生了乱序
SELECT * FROM test WHERE is_delete = 0 AND business_day = \'2021-12-20\' AND full_ps_code LIKE \'xxx%\' AND id > 2100 LIMIT 500;


第五次,经过前几次的分析可以确定,order by 导致查询分析器选择了主键索引,我们在Order by中增加排序字段,将Sql调整如下,同样可以命中我们之前的联合索引,查询时长为0.034s,由于先按照主键排序,结果是一致的。相比第四种方法多了一份filesort,问题得解决。
SELECT * FROM test WHERE is_delete = 0 AND business_day = \'2021-12-20\' AND full_ps_code LIKE \'xxx%\' AND id > 2100 ORDER BY id,full_ps_code LIMIT 500;


第六次,我们考虑是不是Limit导致的问题,我们将Limit 500 调整到 1000,Sql调整如下,奇迹发生了,命中了联合索引,查询时长为0.316s,结果一致,只不过多返回来500条数据。问题得到了解决。经过多次实验Limit 大于695时就会命中联合索引,查询条件下的数据量是79963,696/79963大概占比是0.0087,猜测当获取数据比超过0.0087时,会选择联合索引,未找到源代码验证此结论。
SELECT * FROM test WHERE is_delete = 0 AND business_day = \'2021-12-20\' AND full_ps_code LIKE \'xxx%\' AND id > 2100 ORDER BY id LIMIT 1000;


经过我们的验证,其中第2、5、6三种方法都可以解决性能问题。为了不影响线上,我们立即修改代码,并选择了force index 的方式,上线观察一段时间后,数据库CPU恢复正常,问题得到了解决。

3 事后分析
上线后问题得到了解决,同时也留给我了很多疑问。
- 为什么明明where条件中包含了联合索引,却未能命中,反而选择了性能较慢的主键索引?
- 为什么在order by中增加了一个索引其他字段,就可以命中联合索引了呢?
- 为什么我仅仅是将limit限制条件由原来的500调大后,也能命中联合索引呢?
这一切的答案都来自MySQL的查询优化器。
3.1 查询优化器
查询优化器是专门负责优化查询语句的优化器模块,通过计算分析收集的各种系统统计信息,为查询给出最优的执行计划——最优的数据检索方式。
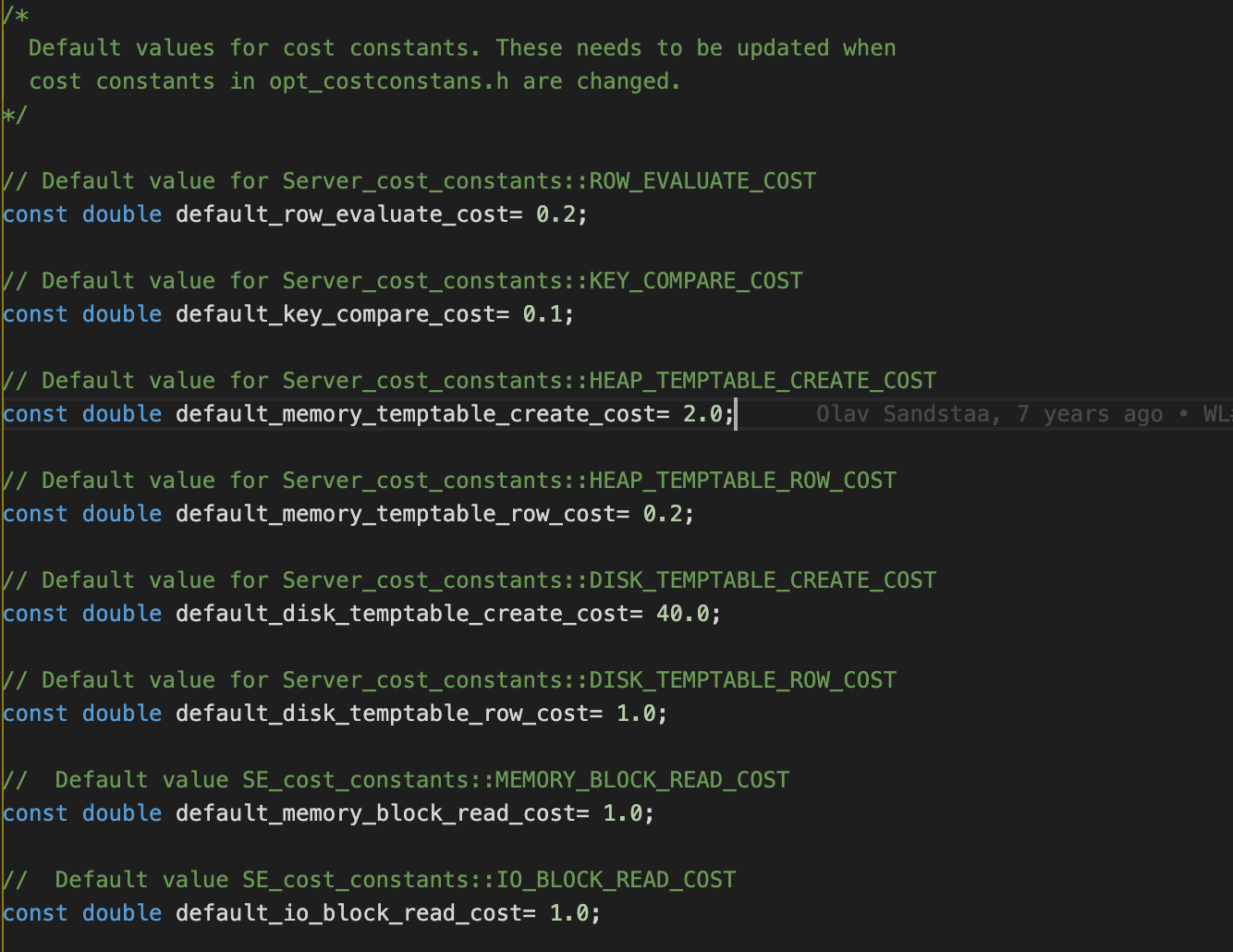
优化器决定如何执行查询的方式是基于一种称为基于代价的优化的方法。5.7在代价类型上分为IO、CPU、Memory。内存的代价收集了,但是并没有参与最终的代价计算。Mysql中引入了两个系统表,mysql.server_cost和mysql.engine_cost,server_cost对应CPU的代价,engine_cost代表IO的代价。
server_cost(CPU代价)
- row_evaluate_cost (default 0.2) 计算符合条件的行的代价,行数越多,此项代价越大
- memory_temptable_create_cost (default 2.0) 内存临时表的创建代价
- memory_temptable_row_cost (default 0.2) 内存临时表的行代价
- key_compare_cost (default 0.1) 键比较的代价,例如排序
- disk_temptable_create_cost (default 40.0) 内部myisam或innodb临时表的创建代价
- disk_temptable_row_cost (default 1.0) 内部myisam或innodb临时表的行代价
由上可以看出创建临时表的代价是很高的,尤其是内部的myisam或innodb临时表。
engine_cost(IO代价)
- io_block_read_cost (default 1.0) 从磁盘读数据的代价,对innodb来说,表示从磁盘读一个page的代价
- memory_block_read_cost (default 1.0) 从内存读数据的代价,对innodb来说,表示从buffer pool读一个page的代价
这些信息都可以在数据库中配置,当数据库中未配置时,从MySql源代码(5.7)中可以看到以上默认值情况
3.2 代价配置
--修改io_block_read_cost值为2 UPDATE mysql.engine_cost SET cost_value = 2.0 WHERE cost_name = \'io_block_read_cost\'; --FLUSH OPTIMIZER_COSTS 生效,只对新连接有效,老连接无效。 FLUSH OPTIMIZER_COSTS;
3.3 代价计算
代价是如何算出来的呢,通过读MySql的源代码,可以找到最终的答案
3.3.1 全表扫描(table_scan_cost)
以下代码摘自MySql Server(5.7分支),全表扫描时,IO与CPU的代价计算方式。
double scan_time= cost_model->row_evaluate_cost(static_cast<double>(records)) + 1; // row_evaluate_cost 核心代码 // rows * m_server_cost_constants->row_evaluate_cost() // 数据行数 * 0.2 (row_evaluate_cost默认值) + 1 = CPU代价 Cost_estimate cost_est= head->file->table_scan_cost(); //table_scan_cost 核心代码 //const double io_cost // = scan_time() * table->cost_model()->page_read_cost(1.0) // 这部分代价为IO部分 //page_read_cost 核心代码 // //const double in_mem= m_table->file->table_in_memory_estimate(); // // table_in_memory_estimate 核心逻辑 //如果表的统计信息中提供了信息,使用统计信息,如果没有则使用启发式估值计算 //pages=1.0 // //const double pages_in_mem= pages * in_mem; //const double pages_on_disk= pages - pages_in_mem; // // //计算出两部分IO的代价之和 //const double cost= buffer_block_read_cost(pages_in_mem) + // io_block_read_cost(pages_on_disk); // // //buffer_block_read_cost 核心代码 // pages_in_mem比例 * 1.0 (memory_block_read_cost的默认值) // blocks * m_se_cost_constants->memory_block_read_cost() // // //io_block_read_cost 核心代码 //pages_on_disk * 1.0 (io_block_read_cost的默认值) //blocks * m_se_cost_constants->io_block_read_cost(); //返回IO与CPU代价 //这里增加了个系数调整,原因未知 cost_est.add_io(1.1); cost_est.add_cpu(scan_time);
根据源代码分析,当表中包含100行数据时,全表扫描的成本为23.1,计算逻辑如下
//CPU代价 = 总数据行数 * 0.2 (row_evaluate_cost默认值) + 1 cpu_cost = 100 * 0.2 + 1 等于 21 io_cost = 1.1 + 1.0 等于 2.1 //总成本 = cpu_cost + io_cost = 21 + 2.1 = 23.1
验证结果如下图

3.3.2 索引扫描(index_scan_cost)
以下代码摘自MySql Server(5.7分支),当出现索引扫描时,是如何进行计算的,核心代码如下
//核心代码解析 *cost= index_scan_cost(keyno, static_cast<double>(n_ranges), static_cast<double>(total_rows)); cost->add_cpu(cost_model->row_evaluate_cost( static_cast<double>(total_rows)) + 0.01)
io代价计算核心代码
//核心代码 const double io_cost= index_only_read_time(index, rows) * table->cost_model()->page_read_cost_index(index, 1.0); // index_only_read_time(index, rows) // 估算index占page个数 //page_read_cost_index(index, 1.0) //根据buffer pool大小和索引大小来估算page in memory和in disk的比例,计算读一个page的代价
cpu代价计算核心代码
add_cpu(cost_model->row_evaluate_cost( static_cast<double>(total_rows)) + 0.01); //total_rows 等于索引过滤后的总行数 //row_evaluate_cost 与全表扫描的逻辑类似, //区别在与一个是table_in_memory_estimate一个是index_in_memory_estimate
3.3.3 其他方式
计算代价的方式有很多,其他方式请参考 MySql原代码。https://github.com/mysql/mysql-server.git
3.4 深度解析
通过查看optimizer_trace,可以了解查询优化器是如何选择的索引。
set optimizer_trace=\"enabled=on\"; --如果不设置大小,可能导致json输出不全 set OPTIMIZER_TRACE_MAX_MEM_SIZE=1000000; SELECT * FROM test WHERE is_delete = 0 AND business_day = \'2021-12-20\' AND full_ps_code LIKE \'xxx%\' AND id > 0 ORDER BY id LIMIT 500; select * FROM information_schema.optimizer_trace; set optimizer_trace=\"enabled=off\";
通过分析rows_estimation节点,可以看到通过全表扫描(table_scan)的话的代价是 8.29e6,同时也可以看到该查询可以选择到主键索引与联合索引,如下图。

上图中全表扫描的代价是8.29e6,我们转换成普通计数法为 8290000,如果使用主键索引成本是 3530000,联合索引 185881,最小的应该是185881联合索引,也可以看到第一步通过成本分析确实选择了我们的联合索引。



但是为什么还是选择了主键索引呢?
通过往下看,在reconsidering_access_paths_for_index_ordering节点下, 发现由于Order by 导致重新选择了索引,在下图中可以看到主键索引可用(usable=true),我们的联合索引为not_applicable (不适用),意味着排序只能使用主键索引。

接下来通过index_order_summary可以看出,执行计划最终被调整,由原来的联合索引改成了主键索引,就是说这个选择无视了之前的基于索引成本的选择。

为什么会有这样的一个选项呢,主要原因如下:
The short explanation is that the optimizer thinks — or should I say hopes — that scanning the whole table (which is already sorted by the id field) will find the limited rows quick enough, and that this will avoid a sort operation. So by trying to avoid a sort, the optimizer ends-up losing time scanning the table.
从这段解释可以看出主要原因是由于我们使用了order by id asc这种基于 id 的排序写法,优化器认为排序是个昂贵的操作,所以为了避免排序,并且它认为 limit n 的 n 如果很小的话即使使用全表扫描也能很快执行完,所以它选择了全表扫描,也就避免了 id 的排序。
5 总结
查询优化器会基于代价来选择最优的执行计划,但由于order by id limit n的存在,MySql可能会重新选择一个错误的索引,忽略原有的基于代价选择出来的索引,转而选择全表扫描的主键索引。这个问题在国内外有大量的用户反馈,BUG地址 https://bugs.mysql.com/bug.php?id=97001 。官方称在5.7.33以后版本可以关闭prefer_ordering_index 来解决。如下图所示。

另外在我们日常慢Sql调优时,可以通过以下两种方式,了解更多查询优化器选择过程。
--第一种 explain format=json sql语句 ------------------------------------------------------------------------- --第二种 optimizer_trace方式 set optimizer_trace=\"enabled=on\"; --如果不设置大小,可能导致json输出不全 set OPTIMIZER_TRACE_MAX_MEM_SIZE=1000000; SQL语句 select * FROM information_schema.optimizer_trace; set optimizer_trace=\"enabled=off\";
当你也出现了本篇文章碰到的问题时,可以采用以下的方法来解决
- 使用force index,强制指定索引。
- order by中增加一个联合索引的key。
- 扩大limit 返回的范围(不推荐,随着数据量的增大,可能还会走回主键索引)
- order by (id+0) asc 欺骗查询优化器,让其选择联合索引。
- MySQL 5.7.33版本以上,可以关闭prefer_ordering_index解决。
作者:陈强
来源:https://www.cnblogs.com/Jcloud/p/16642188.html
本站部分图文来源于网络,如有侵权请联系删除。