 百木园
百木园目录
- 视图
- 触发器
- 存储过程
- 游标
- 异常处理句柄
- 索引
- 单列索引
- 组合索引
- 索引底层原理
- 哈希表
- 平衡二叉树
- BTree
- B+Tree
- 存储引擎
-
- MyISAM的B+Tree
- InnoDB的B+Tree
-
视图
视图(view)是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。作为一个select语句保存在数据字典中的。通过视图,可以展现基表的部分数据;视图数据来自定义视图的查询中使用的表,使用视图动态生成。
意义
- 简单:方便操作,特别是查询操作,减少复杂的SQL语句,增强可读性;
- 安全:数据库授权命令不能限定到特定行和特定列,视图可以把权限限定到行列级别;
个人建议:使用视图建议不要考虑修改视图的操作,视图的优势在于查询。
# 创建视图,视图名字不能和表名一致
create view 视图名(列名1, 列名2, ...) as (查询表达式)
# 视图要修改细节的话删除了重新创建就好了
drop view if exists 视图名
触发器
它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发。
原理: 触发器所依附的表称为基本表,当触发器表上发生
select/update/delete等操作时,会自动生成两个临时的表(new表和old表,只能由触发器使用)。发生insert操作时,新的内容会被插入到new表中;发生delete操作时,旧的内容会被移到old表中;在update操作时,旧的内容会被移到old表中,新的内容会出现在new表中。
# 创建触发器
CREATE TRIGGER 触发器名称 [BEFORE|AFTER] [INSERT|UPDATE|DELETE] ON 表名/视图名 FOR EACH ROW DELETE FROM student WHERE student.sno = new.sno
# 查看触发器
SHOW TRIGGERS
# 删除触发器
DROP TRIGGER 触发器名称
存储过程
存储过程:(PROCEDURE)是事先经过编译并存储在数据库中的一段SQL语句的集合。
DELIMITER $$
CREATE
PROCEDURE 数据库名.存储过程名([in变量名 类型,out 参数 2,inout 参数3, ...])
BEGIN
[DECLARE 变量名 类型 [DEFAULT 值];]
存储过程的语句块;
END$$
DELIMITER ;
游标
游标的作用就是用于对查询数据库所返回的记录进行遍历,以便进行相应的操作;
DECLARE 游标名 CURSOR FOR (查询语句);
异常处理句柄
DECLARE (continue/exit) HANDLE FOR 异常名称(ID) 语句
实例:
DELIMITER $$
CREATE
PROCEDURE de()
-- 存储过程体
BEGIN
-- DECLARE声明 用来声明变量的
DECLARE assignee_id INT;
DECLARE founder_id INT;
DECLARE x INT;
DECLARE cur CURSOR FOR SELECT assignee_id, founder_id FROM task_assign;
DECLARE CONTINUE HANDLER FOR 1329 SET x = 500;
OPEN cur;
WHILE TRUE DO
FETCH cur into assignee_id, founder_id;
SELECT assignee_id, founder_id;
END WHILE;
CLOSE cur;
SELECT x;
END$$
DELIMITER ;
调用存储过程
CALL demo8([in参数],@[out参数]);
所有参数默认设置为IN
搜索存储过程
# 显示所有的存储过程
SHOW PROCEDURE STATUS;
# 显示特定数据库的存储过程
SHOW PROCEDURE STATUS WHERE db = 数据库名字 AND NAME = 存储过程的名字;
# 模糊搜索存储过程
SHOW PROCEDURE STATUS WHERE NAME LIKE \'%mo%\';
获取存储过程的源码
SHOW CREATE PROCEDURE 存储过程名;
删除存储过程
DROP PROCEDURE 存储过程名;
索引
单列索引
索引类型
-
NORMAL:普通的索引类型,相当于目录。
-
UNIQUE:唯一索引,一旦建立唯一索引,那么整个列中将不允许出现重复数据。
- 每个表的主键列,有且仅有一个主键索引,是特殊的唯一索引。
- 不出现重复
- 不能为NULL
- 可以选择自动递增
- 每张表可以有多个唯一索引,但只能有一个主键索引。
- 每个表的主键列,有且仅有一个主键索引,是特殊的唯一索引。
-
SPATIAL:空间索引,空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON,不常用。
-
FULLTEXT:全文索引(MySQL 5.6 之后InnoDB才支持),它作为模糊匹配的一种优秀的解决方案,使用的效率要比使用
like %更高,并且支持多种匹配方式。只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
全文索引的使用
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (body));
INSERT INTO articles VALUES
(NULL,\'MySQL Tutorial\', \'DBMS stands for DataBase ...\'),
(NULL,\'How To Use MySQL Efficiently\', \'After you went through a ...\'),
(NULL,\'Optimising MySQL\',\'In this tutorial we will show ...\'),
(NULL,\'1001 MySQL Tricks\',\'1. Never run mysqld as root. 2. ...\'),
(NULL,\'MySQL vs. YourSQL\', \'In the following database comparison ...\'),
(NULL,\'MySQL Security\', \'When configured properly, MySQL ...\');
使用全文索引进行模糊匹配:
SELECT * FROM articles WHERE MATCH (body) AGAINST (\'database\');
它的效率远高于以下这种写法:
SELECT * FROM articles WHERE body like \'%database%\';
组合索引
将多个字段索引组合为一个索引
索引底层原理
通过数据结构(表内部的规律),降低数据库的IO成本,提高数据的检索效率;但是相应是索引会占据额外的磁盘空间,而为了维持表内部的规律,也会降低更新表的效率。
哈希表
散列表(哈希表):key的值通过哈希函数直接映射为value所在的地址。

优点:
- 查询效率非常快,能达到O(1)
缺点:
- Hash索引仅仅能满足“=”,“in”查询条件,不能使用范围查询。
- Hash碰撞问题(计算出的哈希值一致)
- 不能用部分索引键来搜索,因为组合索引必须要有全部的索引才能计算出对应的哈希值
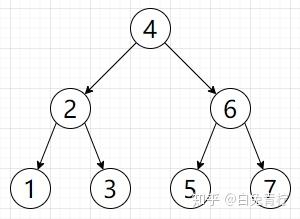
平衡二叉树
平衡二叉树查找的效率是log2N,查询节点1需要IO读取(4,2)节点。
BTree
由于InnoDB存储引擎一次可以读取一页的数据量(默认16K),而降低二叉树的高度又可以减少查询次数,这样就可以将平衡二叉树改为平衡多叉树,进而减少磁盘的IO次数。
-
树中每个结点最多含有m个孩子(m >= 2)
-
除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子。(向上取整)
-
若根结点不是叶子结点,则至少有2个孩子。
-
所有叶子结点都出现在同一层。
-
每个非终端结点中包含有n个键值信息: (P1,K1,P2,K2,P3,......,Kn,Pn+1)。其中:
- Ki (i=1...n)为键值,且键值按顺序升序排序K(i-1)< Ki。
- Pi为指向子树根的结点,且指针P(i)指向的子树中所有结点的键值均小于Ki,但都大于K(i-1)。
- 键值的个数n必须满足: [ceil(m / 2)-1] <= n <= m-1。
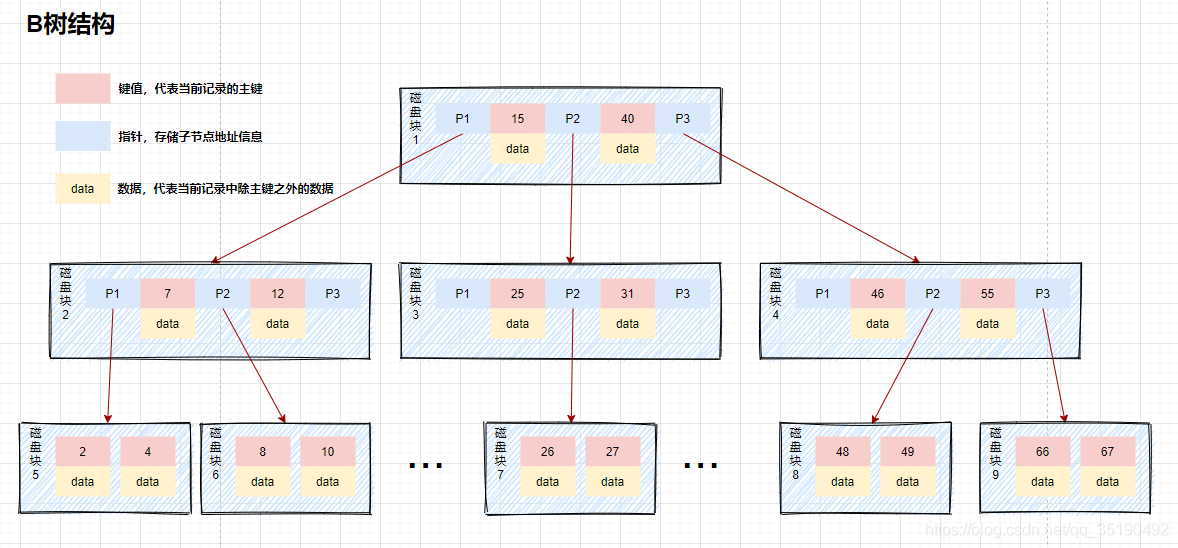
比如现在我们要对键值为10的记录进行查找,过程如下:
- 读取根节点数据(目前进行了一次IO操作)
- 根据根节点数据进行判断得到10<15,因为P1指向的子树中所有值都是小于15的,所以这时我们将P1指向的节点读取(目前进行了两次IO操作)
- 再次进行判断,得到7<10<12,因为P2指向的子树中所有的值都是小于12大于8的,所以这时读取P2指向的节点(目前进行了三次IO操作)
缺点:
-
B树不支持范围查询的快速查找,每一次范围内的查找都需要重新进行IO读取。
-
如果data存储的是行记录,行的大小随着列数的增多,所占空间会变大。这时,一个页中可存储的数据量就会变少,树相应就会变高,磁盘IO次数就会变多。
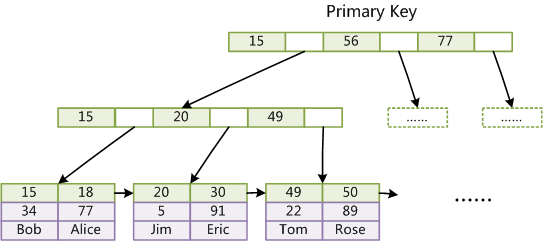
B+Tree
解决了BTree的缺点,只有叶子节点才会存储数据,非叶子节点存储键值;叶子节点之间使用双向指针连接,最底层叶子节点之间形成双向有序链表。(实现了范围查询)
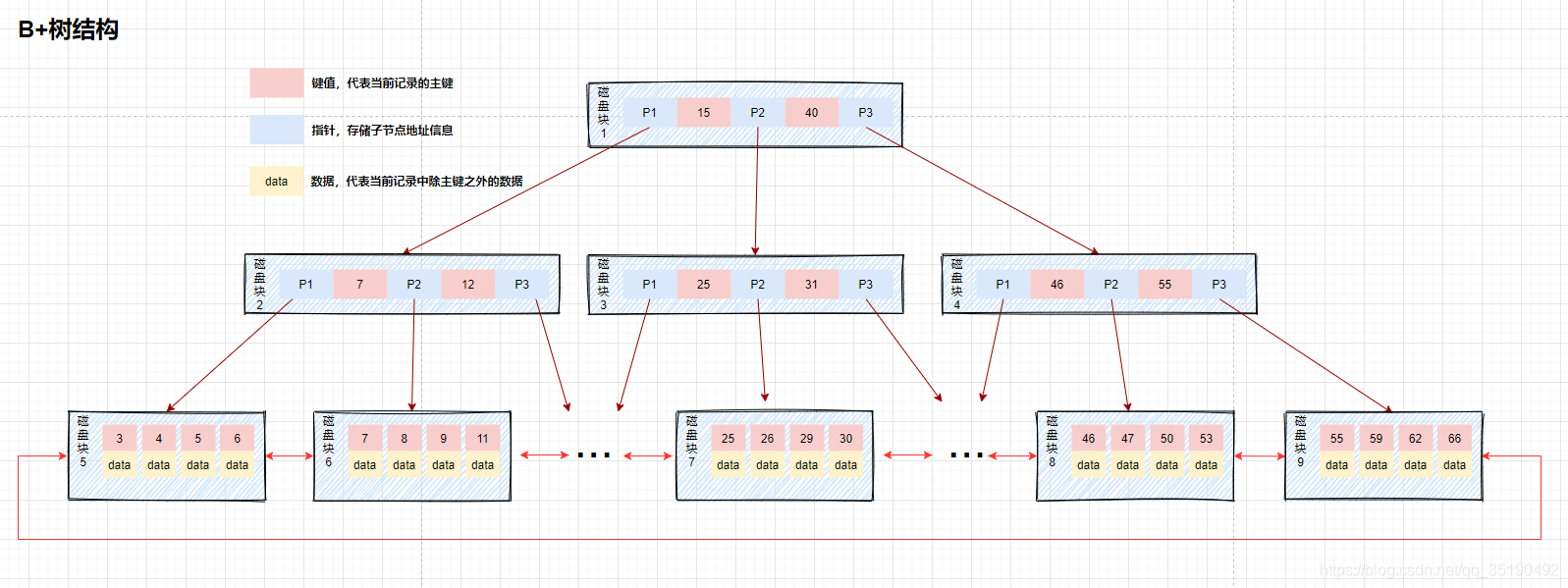
存储引擎
- MyISAM:MySQL5.5之前的默认存储引擎,在插入和查询的情况下性能很高,但是它不支持事务,只能添加表级锁。
- InnoDB:MySQL5.5之后的默认存储引擎,它支持ACID事务、行级锁、外键,但是性能比不过MyISAM,更加消耗资源。
- Memory:数据都存放在内存中,数据库重启或发生崩溃,表中的数据都将消失。

使用navicat可以方便的查看和修改存储引擎。
MyISAM的B+Tree
数据和索引分开存储,因此单次查询需要树的高度+1(记录数据检索)
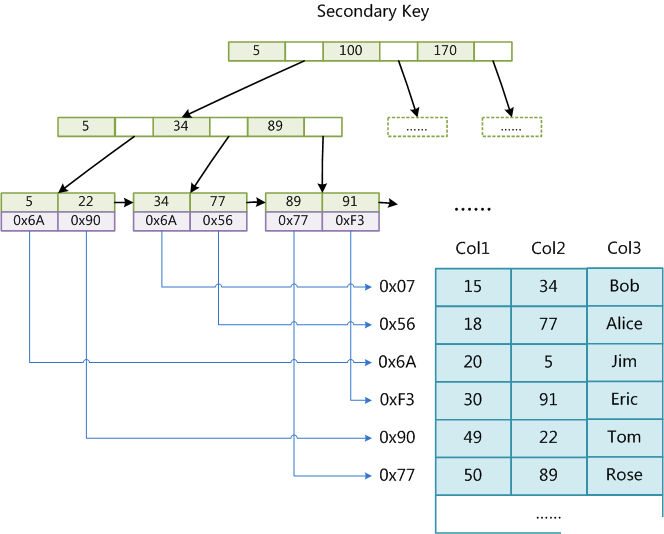
InnoDB的B+Tree
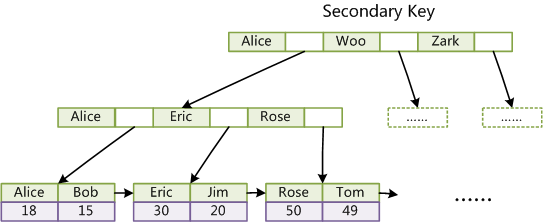
数据本身就是索引的一部分,非主键索引的数据实际上存储的是对应记录的主键值。
因此,使用主键进行查询需要树的高度次磁盘IO,但是假如非主键则需要乘2。
建议使用InnoDB引擎时,使用主键或者主键组合其他索引进行查询,这样就可以避免仅使用辅助索引而造成回表。
辅助索引:使用辅助索引需要查询+回表 = 树的高度 * 2
来源:https://www.cnblogs.com/angelMask/p/16469265.html
本站部分图文来源于网络,如有侵权请联系删除。