 百木园
百木园前言
嗨喽~大家好呀,这里是魔王呐 !
又是学习的一天,让我们开始叭~

环境使用:
-
Python 3.8
-
Pycharm
模块使用:
-
requests >>> pip install requests
-
re
-
csv
如果安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令

基本流程思路: <通用>
一. 数据来源分析
-
抓包分析我们想要数据内容, 请求的那个网站 url地址得到
-
F12 或者 鼠标右键点击检查选择network, 点击第二页
-
选中xhr 第一个数据包就是我们想要的内容
用到开发者工具搜索功能
二. 代码实现步骤过程: 固定四大步骤
-
发送请求, 对于刚刚分析得到url地址发送请求
-
获取数据, 获取服务器返回响应数据 ---> 开发者工具里面response
-
解析数据, 提取我们想要数据内容 ---> 店铺基本信息
-
保存数据, 保存数据, 保存表格里面
-
多页数据采集
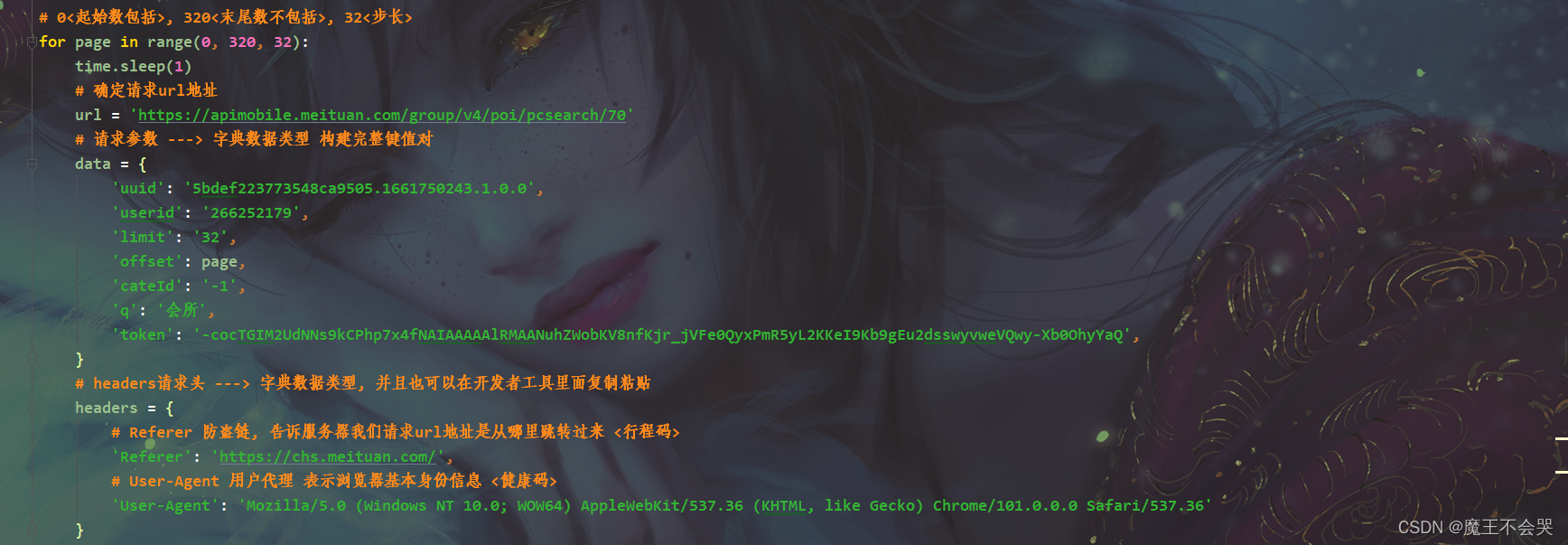
多页数据采集 ---> 循环 for <目的>
分析请求url地址参数变化

采集代码
# 导入数据请求模块 ---> 第三方模块 需要 pip install requests
import requests
# 导入格式化输出模块 --> 内置模块 不需要安装
from pprint import pprint
# 导入csv模块 --> 内置模块 不需要安装
import csv
# 导入时间模块 --> 内置模块 不需要安装
import time
# 导入正则模块 --> 内置模块 不需要安装
import re

# 3. 发送请求
html_data = requests.get(url=link, headers=headers).text
# 4. 获取数据print(html_data)
\"\"\"
5. 解析数据, re正则 会用 1 不会 2
re.findall() 找到所有我们想要数据
告诉程序: 从什么地方 去找什么数据
从 html_data 去找 \"address\":\"(.*?)\",\"phone\":\"(.*?)\",\"openTime\":\"(.*?)\", 这段内容
其中 (.*?) 就是我们要的数据
\"\"\"
shop_info = re.findall(\'\"address\":\"(.*?)\",\"phone\":\"(.*?)\",\"openTime\":\"(.*?)\",\', html_data)[0]
print(shop_info)
# shop_info 元组 ---> [0] 根据索引位置取值 / 计数从0开始计数
address = shop_info[0]
# [1] 什么意思?
phone = shop_info[1]
# replace 是什么 字符串替换方法 把 \\\\n 替换 空的 \\<转义字符串> \\n 还换行符
openTime = shop_info[2].replace(\'\\\\n\', \'\')
print(address, phone, openTime)
# 创建文件 相对路径 你代码在哪里 文件就写在哪里
f = open(\'男人的小秘密多页.csv\', mode=\'a\', encoding=\'utf-8\', newline=\'\')
# 字典写入 f ---> 文件对象 fieldnames 字段名 表头表格第一行内容
csv_writer = csv.DictWriter(f, fieldnames=[
\'店铺\',
\'店铺类型\',
\'商圈\',
\'人均消费\',
\'最低消费\',
\'评分\',
\'评论\',
\'纬度\',
\'经度\',
\'详情页\',
])
# 写入表头
csv_writer.writeheader()
- 发送请求, 模拟浏览器发送请求
代码都是可以复制粘贴
-
长链接可以分段写入
-
批量替换 ---> 批量添加引号和逗号
1.选中替换内容
2.按 ctrl + R
3.勾选上.* 输入正则命令
(.*?): (.*)
\'$1\': \'$2\',
- 如果当你请求网站, 被反爬的时候
一种最简单反反爬手段, 用headers请求头伪装成浏览器去发送请求
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
# <Response [403]>: 整体表示响应对象 403状态码 表示 没有访问权限
# <Response [200]> 200 状态码表示请求成功 print(response)
# 2. 获取数据, 获取服务器返回响应数据 ---> 开发者工具里面response --> response.json() 获取响应对象json字典数据 print(response.json())
# 3. 解析数据, 提取我们想要的数据内容 ---> 字典取值: 键值对取值 <根据冒号左边的内容[键], 提取冒号右边的内容[值]>
for index in response.json()[\'data\'][\'searchResult\']: # for循环遍历, 把列表里面元素一个一个提取出来

# 写入数据
csv_writer.writerow(dit)
print(dit)
可视化代码
import pandas as pd
import numpy as np
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType #引入主题
df = pd.read_csv(\'武汉桌游多页.csv\',encoding=\'utf-8\',engine=\"python\")
df.sample(5)
df.info()
df = df.fillna(\'暂无数据\')
cut = lambda x : \'一般\' if x <= 3.5 else (\'不错\' if x <= 4.0 else(\'好\' if x <= 4.5 else \'很好\'))
df[\'评分类型\'] = df[\'评分\'].map(cut)
df.describe()
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 设置加载的字体名
plt.rcParams[\'axes.unicode_minus\'] = False # 解决保存图像是负号\'-\'显示为方块的问题
fig,axes=plt.subplots(2,1,figsize=(12,12))
sns.regplot(x=\'人均消费\',y=\'评分\',data=df,color=\'r\',marker=\'+\',ax=axes[0])
sns.regplot(x=\'评论\',y=\'评分\',data=df,color=\'g\',marker=\'*\',ax=axes[1])
df2 = df.groupby(\'商圈\')[\'店名\'].count()
df2 = df2.sort_values(ascending=True)[-10:]
df2 = df2.round(2)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df2.index.tolist())
.add_yaxis(\"\",df2.tolist()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title=\"武汉桌游商圈数量top10\",subtitle=\"数据来源:美团\",pos_left = \'center\'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position=\'right\'))
)
c.render_notebook()
df4 = df.groupby(\'评分\')[\'店名\'].count()
df4 = df4.sort_values(ascending=False)
regions = df4.index.tolist()
values = df4.tolist()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add(\"\", [z for z in zip(regions,values)])
.set_global_opts(title_opts=opts.TitleOpts(title=\"不同评分类型店铺数量\",subtitle=\"数据来源:美团\",pos_top=\"-1%\",pos_left = \'center\'))
.set_series_opts(label_opts=opts.LabelOpts(formatter=\"{b}:{d}%\",font_size=18))
)
c.render_notebook()
df6 = df.groupby(\'店铺类型\')[\'店名\'].count()
df6 = df6.sort_values(ascending=False)[:10]
df6 = df6.round(2)
regions = df6.index.tolist()
values = df6.tolist()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add(\"\", [i for i in zip(regions,values)],radius=[\"40%\", \"75%\"])
.set_global_opts(title_opts=opts.TitleOpts(title=\"不同店铺类型店铺数量\",pos_top=\"-1%\",pos_left = \'center\'))
.set_series_opts(label_opts=opts.LabelOpts(formatter=\"{b}: {c}\",font_size=18))
)
c.render_notebook()
df6 = df.groupby(\'店铺类型\')[\'评分\'].mean()
df6 = df6.sort_values(ascending=True)
df6 = df6.round(2)
df6 = df6.tail(10)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df6.index.tolist())
.add_yaxis(\"\",df6.tolist()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title=\"不同店铺类型评分\",subtitle=\"数据来源:美团\",pos_left = \'center\'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position=\'right\'))
)
c.render_notebook()
df7 = df.groupby(\'店铺类型\')[\'评论\'].sum()
df7 = df7.sort_values(ascending=True)
df7 = df7.tail(10)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND))
.add_xaxis(df7.index.tolist())
.add_yaxis(\"\",df7.tolist()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title=\"不同店铺类型评论人数\",subtitle=\"数据来源:美团\",pos_left = \'center\'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position=\'right\'))
)
c.render_notebook()
尾语
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝
对啦!!记得三连哦~ 💕 另外,欢迎大家阅读我往期的文章呀~

来源:https://www.cnblogs.com/Qqun261823976/p/16647527.html
本站部分图文来源于网络,如有侵权请联系删除。