 百木园
百木园概述
1. Mycat 是什么?
Mycat 是数据库中间件,连接 Java 应用程序和数据库,它的作用如下:
-
读写分离
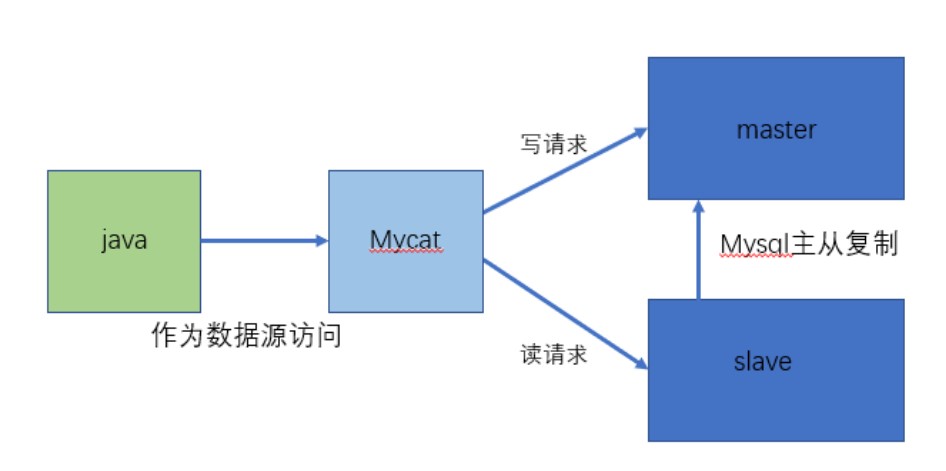
-
数据分片:垂直拆分(分库)、水平拆分(分表)、垂直+水平拆分(分库分表)
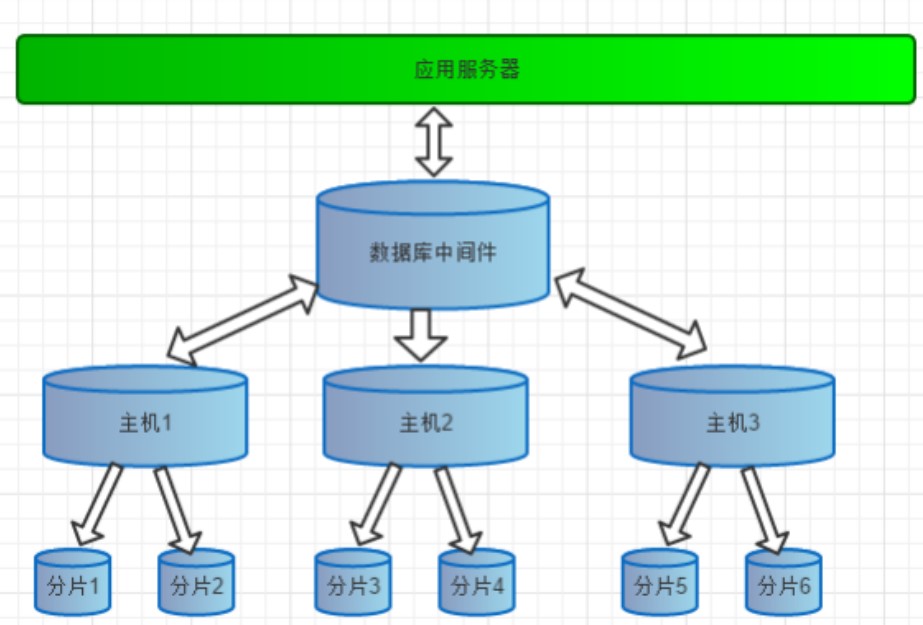
-
多数据源整合
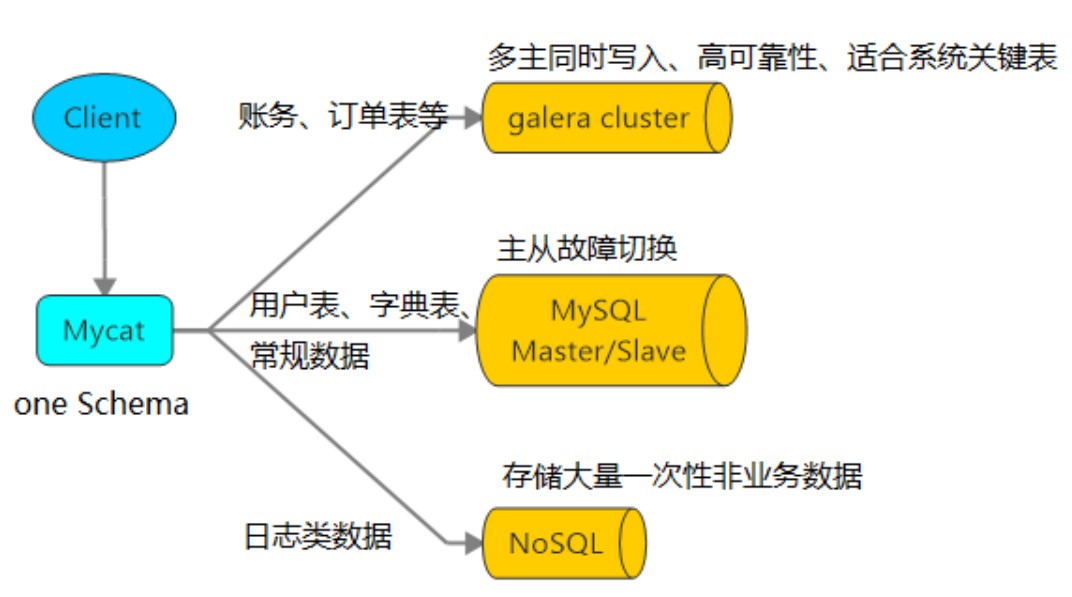



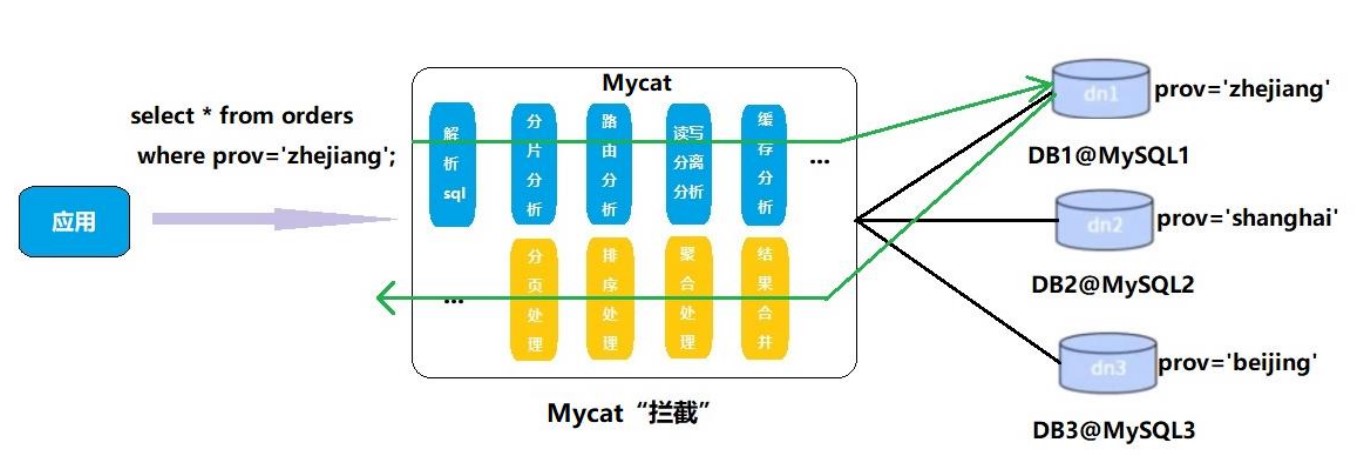
2. Mycat 原理
Mycat 拦截了用户发送过来的 SQL 语句,首先对 SQL 语句进行特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将该 SQL 发送到真实的数据库,并处理返回的结果,再返回给用户
Mycat 安装启动
1. 安装
在 Mycat官网 下载压缩包,拷贝到 Linux 并解压
tar -vxzf Mycat-server-1.6.7.6-release-20220221174943-linux.tar.gz
Mycat 有三个配置文件:
- schema.xml:定义逻辑库,表、分片节点等内容
- rule.xml:定义分片规则
- server.xml:定义用户以及系统相关变量,如端口等
修改配置文件server.xml,修改用户信息,与 MySQL 区分,如下:
…
<user name=\"mycat\">
<property name=\"password\">123456</property>
<property name=\"schemas\">TESTDB</property>
</user>
…
修改配置文件 schema.xml,如下:
<?xml version=\"1.0\"?>
<!DOCTYPE mycat:schema SYSTEM \"schema.dtd\">
<mycat:schema xmlns:mycat=\"http://io.mycat/\">
<schema name=\"MYCAT_TEST_DB\" checkSQLschema=\"true\" sqlMaxLimit=\"100\" randomDataNode=\"dn1\" dataNode=\"dn1\"></schema>
<dataNode name=\"dn1\" dataHost=\"host1\" database=\"mycat_test_db\" />
<dataHost name=\"host1\" maxCon=\"1000\" minCon=\"10\" balance=\"0\"
writeType=\"0\" dbType=\"mysql\" dbDriver=\"jdbc\" switchType=\"1\" slaveThreshold=\"100\">
<heartbeat>select user()</heartbeat>
<writeHost host=\"hostM1\" url=\"jdbc:mysql://localhost:3306\" user=\"root\" password=\"123\">
<readHost host=\"hostS1\" url=\"jdbc:mysql://localhost:3307\" user=\"root\" password=\"123\"/>
</writeHost>
</dataHost>
</mycat:schema>
接下来启动程序,有两种方式:
-
控制台启动:mycat/bin 目录下执行
./mycat console -
后台启动:mycat/bin 目录下
./mycat start
2. 登录
登录后台管理窗口,此登录方式用于管理维护 Mycat
mysql -umycat -p123456 -P 9066 -h localhost
登录数据窗口,此登录方式用于通过 Mycat 查询数据
mysql -umycat -p123456 -P 8066 -h localhost
Mycat 搭建读写分离
通过 Mycat 和 MySQL 的主从复制配合搭建数据库的读写分离,实现 MySQL 的高可用性
1. 主从复制原理
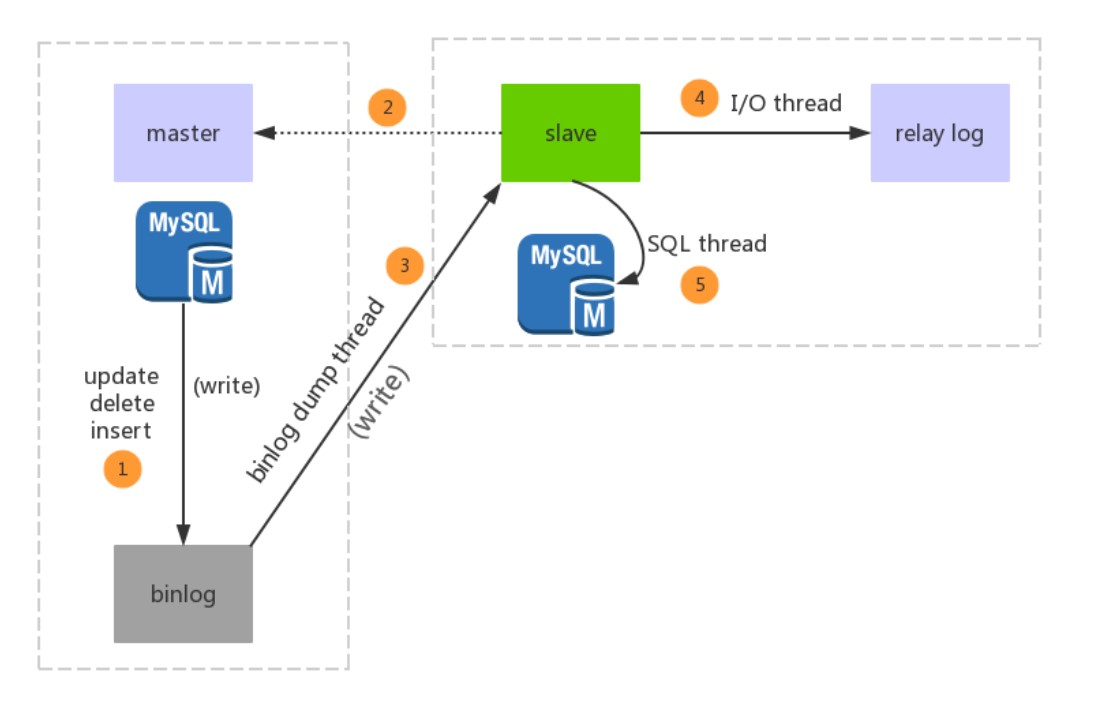
- 主库的更新事件(update、insert、delete)被写到 binlog
- 主库创建一个 binlog dump thread,把 binlog 的内容发送到从库
- 从库启动并发起连接,连接到主库
- 从库启动之后,创建一个 I/O 线程,读取主库传过来的 binlog 内容并写入到 relay log
- 从库启动之后,创建一个 SQL 线程,从 relay log 里面读取内容,从 Exec_Master_Log_Pos 位置开始执行读取到的更新事件,将更新内容写入到 slave 的 db
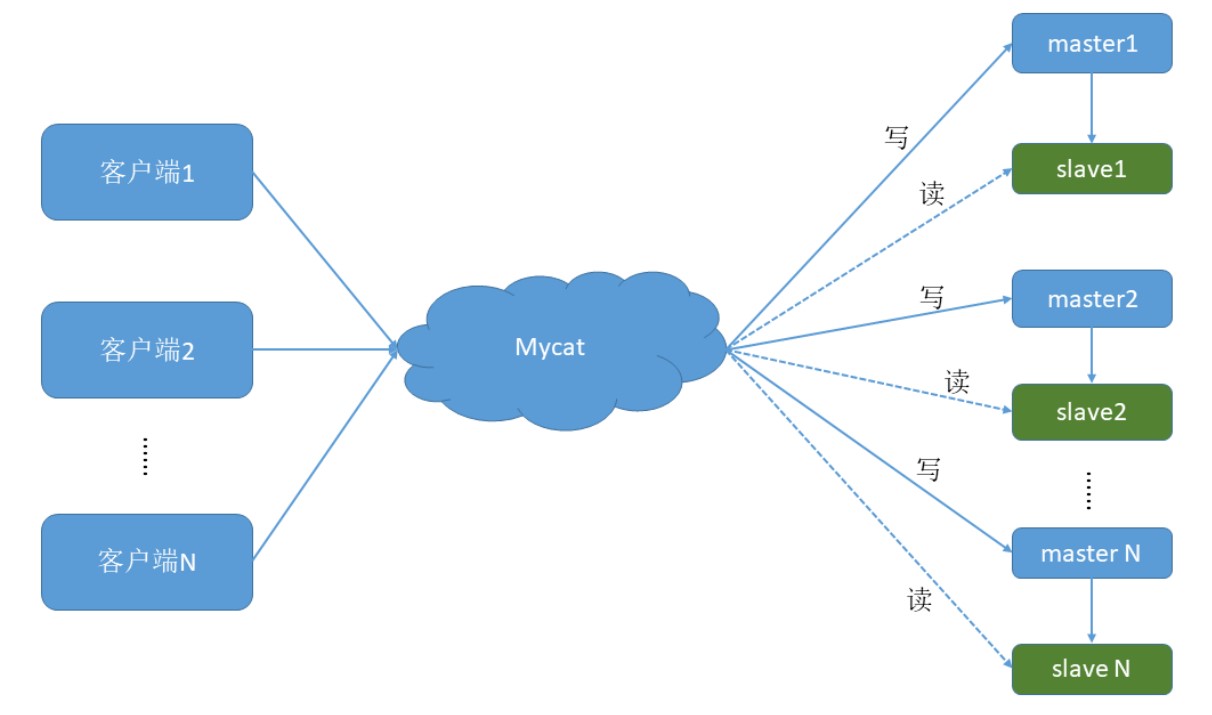
1. 一主一从
一个主机用于处理所有写请求,一台从机负责所有读请求,架构图如下:
设置主机配置,修改配置文件:vim /etc/my.cnf
# 主服务器唯一ID
server-id=1
# 启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
# 设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
# 设置logbin格式
binlog_format=STATEMENT
binlog 有三种格式:
- Statement:Statement 模式只记录执行的 SQL,不需要记录每一行数据的变化,因此极大的减少了 binlog 的日志量,避免了大量的 IO 操作,提升了系统的性能。但是,正是由于 Statement 模式只记录 SQL,而如果一些 SQL 中包含了函数,那么可能会出现执行结果不一致的情况。比如说
uuid()函数,每次执行的时候都会生成一个随机字符串,在 master 中记录了 uuid,当同步到 slave 之后,再次执行,就得到另外一个结果了 - Row:Row 格式不记录 SQL 语句上下文相关信息,仅仅只需要记录某一条记录被修改成什么样子了。Row 格式的日志内容会非常清楚地记录下每一行数据修改的细节,这样就不会出现 Statement 中存在的那种数据无法被正常复制的情况。不过 Row 格式也有一个很大的问题,那就是日志量太大了,特别是批量
update、整表delete、alter表等操作,由于要记录每一行数据的变化,此时会产生大量的日志,大量的日志也会带来 IO 性能问题 - Mixed:在 Mixed 模式下,系统会自动判断该用 Statement 还是 Row,一般的语句修改使用 Statement 格式保存 binlog;对于一些 Statement 无法准确完成主从复制的操作,则采用 Row 格式保存 binlog
设置从机配置,修改配置文件:vim /etc/my.cnf
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
主机、从机重启 MySQL 服务,并关闭防火墙
在主机上建立帐户并授权 slave
# 在主机 MySQL 里执行授权命令
GRANT REPLICATION SLAVE ON *.* TO \'slave\'@\'%\' IDENTIFIED BY \'123123\';
查询 master 的状态,记录下 File 和 Position 的值,执行完此步骤后不要再操作主服务器 MySQL,防止主服务器状态值变化
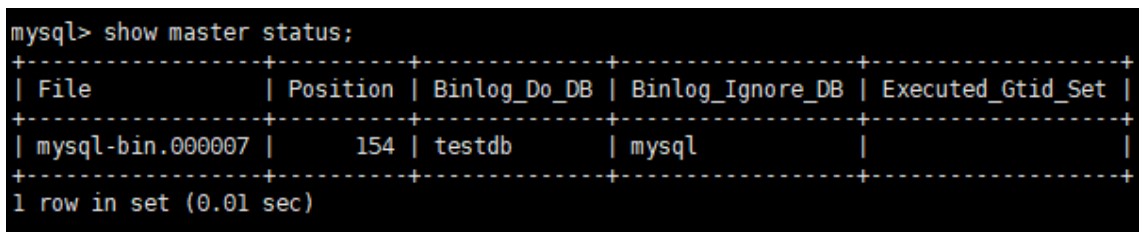
在从机上配置需要复制的主机
# 复制主机的命令
CHANGE MASTER TO MASTER_HOST=\'主机的IP地址\',
MASTER_USER=\'slave\',
MASTER_PASSWORD=\'123123\',
MASTER_LOG_FILE=\'mysql-bin.具体数字\',MASTER_LOG_POS=具体值;
# 启动从服务器复制功能
start slave;
# 查看从服务器状态
show slave status\\G;
# 停止从服务复制功能
stop slave;
# 重启主机
reset master;
下面两个参数都是 Yes,则说明主从配置成功
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
2. 双主双从
一个主机 m1 用于处理所有写请求,它的从机 s1 和另一台主机 m2 还有它的从机 s2 负责所有读请 求。当 m1 主机宕机后,m2 主机负责写请求,m1、m2 互为备机,架构图如下:
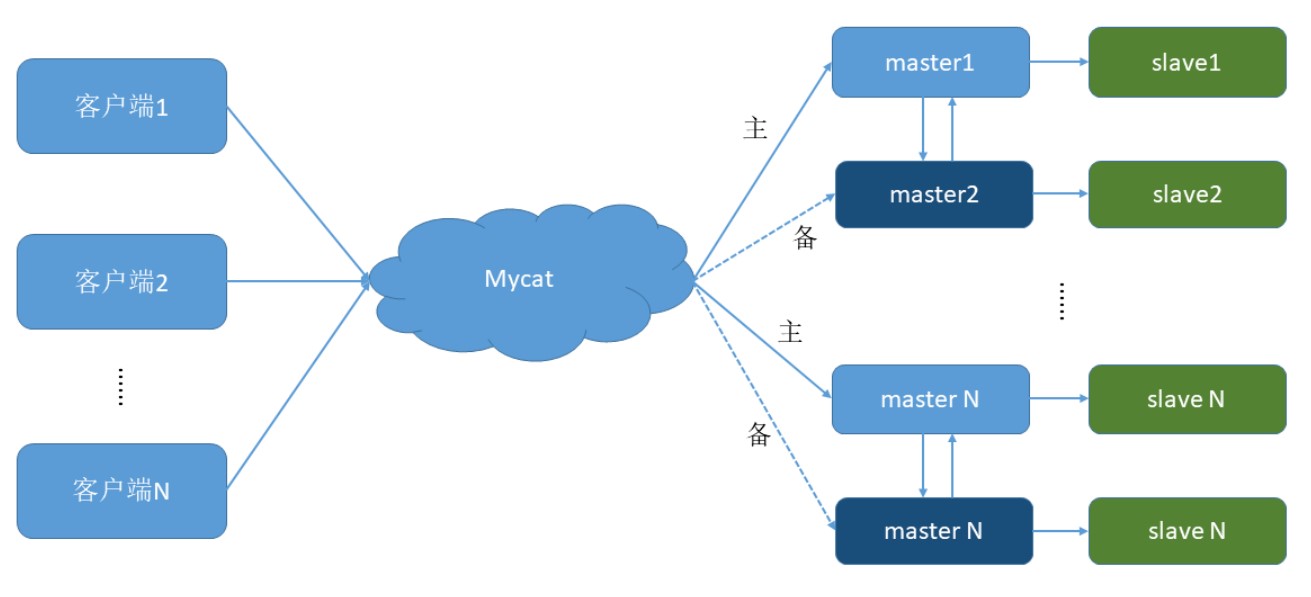
设置双主机配置:Master1 和 Master2
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
#设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=1
#主服务器唯一ID
server-id=3
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
#设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=2
双主机配置:Slave1 和 Slave2
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
#从服务器唯一ID
server-id=4
#启用中继日志
relay-log=mysql-relay
双主机、双从机重启 mysql 服务,并且关闭防火墙
在两台主机上建立帐户并授权 slave
# 在主机MySQL里执行授权命令
GRANT REPLICATION SLAVE ON *.* TO \'slave\'@\'%\' IDENTIFIED BY \'123123\';
查询 master 的状态,分别记录下 File 和 Position 的值,执行完此步骤后不要再操作主服务器 MySQL,防止主服务器状态值变化
在从机上配置需要复制的主机,Slava1 复制 Master1,Slava2 复制 Master2,以及主机 Master2 的复制 Master1
# 复制主机的命令
CHANGE MASTER TO MASTER_HOST=\'主机的IP地址\',
MASTER_USER=\'slave\',
MASTER_PASSWORD=\'123123\',
MASTER_LOG_FILE=\'mysql-bin.具体数字\',MASTER_LOG_POS=具体值;
3. 读写分离
修改 Mycat 的配置文件 schema.xml,配置对应的读写机,修改的 balance 属性,通过此属性配置读写分离的负载均衡类型,目前的取值有四种:
balance=\"0\": 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上balance=\"1\": 全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡balance=\"2\": 所有读操作都随机的在 writeHost、readhost 上分发balance=\"3\": 所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
其他配置参数如下:
writeType=\"0\":所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个writeType=\"1\":所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐
writeHost 以重新启动后以切换后的为准,切换记录在配置文件 dnindex.properties 中,设置参数switchType=\"1\":
- 1 默认值,自动切换
- -1 表示不自动切换
- 2 基于 MySQL 主从同步的状态决定是否切换
垂直分库
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同 的数据库上面,这样也就将数据或者说压力分担到不同的库上面
1. 分库原则
由于在两台主机上的两个数据库中的表不能关联查询,所以有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里
2. 分库实现
假设现有四张表
# 客户表 rows:20w
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
# 订单表 rows:600w
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
# 订单详细表 rows:600w
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
# 订单状态字典表 rows:20w
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);
客户表分在一个数据库,另外三张都需要关联查询,所有分在另外一个数据库
修改 schema 配置文件
...
<schema name=\"TESTDB\" checkSQLschema=\"false\" sqlMaxLimit=\"100\" dataNode=\"dn1\">
<table name=\"customer\" dataNode=\"dn2\" ></table>
</schema>
<dataNode name=\"dn1\" dataHost=\"host1\" database=\"orders\" />
<dataNode name=\"dn2\" dataHost=\"host2\" database=\"orders\" />
<dataHost name=\"host1\" maxCon=\"1000\" minCon=\"10\" balance=\"0\" writeType=\"0\" dbType=\"mysql\" dbDriver=\"native\" switchType=\"1\" slaveThreshold=\"100\">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host=\"hostM1\" url=\"192.168.140.128:3306\" user=\"root\" password=\"123123\"></writeHost>
</dataHost>
<dataHost name=\"host2\" maxCon=\"1000\" minCon=\"10\" balance=\"0\" writeType=\"0\" dbType=\"mysql\" dbDriver=\"native\" switchType=\"1\" slaveThreshold=\"100\">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host=\"hostM2\" url=\"192.168.140.127:3306\" user=\"root\" password=\"123123\"></writeHost>
</dataHost>
在数据节点 dn1、dn2 上分别创建数据库 orders
访问 Mycat 进行分库,切换到 TESTDB,创建对应的四张表,在对应节点查看表信息,可以看到成功分库
水平分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中
1. 分表实现
以 orders 表为例,可以根据不同的字段进行分表:
- id(主键、或创建时间):查询订单注重时效,历史订单被查询的次数少,如此分片会造成一个节点访问多,一个访问少,不平均
- customer_id(客户 id):根据客户 id 去分,两个节点访问平均,一个客户的所有订单都在同一个节点
修改配置文件 schema.xml,为 orders 表设置数据节点为 dn1、dn2,并指定分片规则为 mod_rule(自定义的名字)
...
<schema name=\"TESTDB\" checkSQLschema=\"false\" sqlMaxLimit=\"100\" dataNode=\"dn1\">
<table name=\"customer\" dataNode=\"dn2\" ></table>
<table name=\"orders\" dataNode=\"dn1,dn2\" rule=\"mod_rule\" ></table>
</schema>
...
修改配置文件 rule.xml,在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为 customer_id,指定分片算法 mod-long(对字段求模运算),customer_id 对两个节点求模,根据结果分片
<tableRule name=\"mod_rule\">
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
...
<function name=\"mod-long\" class=\"io.mycat.route.function.PartitionByMod\">
<!-- 表示有两个节点 -->
<property name=\"count\">2</property>
</function>
在数据节点 dn2 上建 orders 表,重启 Mycat,让配置生效,访问 Mycat 实现分片
# 在 mycat 里向 orders 表插入数据,INSERT 字段不能省略
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
2. 分片的关联查询
2.1 ER 表
Orders 订单表已经进行分表操作了,和它关联的 orders_detail 订单详情表如果需要进行 join 查询,那也要对 orders_detail 也要进行分片操作,原理如下:
Mycat 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路,Foundation DB 创新性的提出了 Table Group 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了 JION 的效率和性能问 题,根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上
修改 schema.xml 配置文件
<table name=\"orders\" dataNode=\"dn1,dn2\" rule=\"mod_rule\" >
<childTable name=\"orders_detail\" primaryKey=\"id\" joinKey=\"order_id\" parentKey=\"id\" />
</table>
在 dn2 创建 orders_detail 表,重启 Mycat,访问 Mycat 向 orders_detail 表插入数
INSERT INTO orders_detail(id,detail,order_id) values(1,\'detail1\',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(2,\'detail1\',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(3,\'detail1\',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(4,\'detail1\',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(5,\'detail1\',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(6,\'detail1\',6);
# 在mycat、dn1、dn2中运行两个表join语句
Select o.*,od.detail from orders o inner join orders_detail od on o.id=od.order_id;
2.2 全局表
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,考虑到字典表具有以下几个特性:
- 变动不频繁
- 数据量总体变化不大
- 数据规模不大,很少有超过数十万条记录
鉴于此,Mycat 定义了一种特殊的表,称之为全局表,全局表具有以下特性:
- 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
- 全局表的查询操作,只从一个节点获取
- 全局表可以跟任何一个表进行 JOIN 操作
将字典表或者符合字典表特性的一些表定义为全局表,可以很好的解决了数据 JOIN 的难题
修改 schema.xml 配置文件
...
<table name=\"orders\" dataNode=\"dn1,dn2\" rule=\"mod_rule\" >
<childTable name=\"orders_detail\" primaryKey=\"id\" joinKey=\"order_id\" parentKey=\"id\" />
</table>
<table name=\"dict_order_type\" dataNode=\"dn1,dn2\" type=\"global\" ></table>
...
在 dn2 创建 dict_order_type 表,重启 Mycat,访问 Mycat 向 dict_order_type 表插入数据
INSERT INTO dict_order_type(id,order_type) VALUES(101,\'type1\');
INSERT INTO dict_order_type(id,order_type) VALUES(102,\'type2\');
3. 常用的分片规则
3.1 取模
此规则为对分片字段求摸运算,也是水平分表最常用规则。上述对 orders 表就采用了此规则
3.2 分片枚举
通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则
修改 schema.xml 配置文件
<table name=\"orders_ware_info\" dataNode=\"dn1,dn2\" rule=\"sharding_by_intfile\" ></table>
修改 rule.xml 配置文件
<tableRule name=\"sharding_by_intfile\">
<rule>
<columns>areacode</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
...
<function name=\"hash-int\" class=\"io.mycat.route.function.PartitionByFileMap\">
<property name=\"mapFile\">partition-hash-int.txt</property>
<property name=\"type\">1</property>
<property name=\"defaultNode\">0</property>
</function>
参数说明如下:
- columns:分片字段
- algorithm:分片函数
- mapFile:标识配置文件名称
- type:0 为 int 型,非 0 为 String
- defaultNode:默认节点,小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错
修改 partition-hash-int.txt 配置文件
110=0
120=1
重启 Mycat,访问 Mycat 创建表
# 订单归属区域信息表
CREATE TABLE orders_ware_info
(
`id` INT AUTO_INCREMENT comment \'编号\',
`order_id` INT comment \'订单编号\',
`address` VARCHAR(200) comment \'地址\',
`areacode` VARCHAR(20) comment \'区域编号\',
PRIMARY KEY(id)
);
# 插入数据
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,\'北京\',\'110\');
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (2,2,\'天津\',\'120\');
3.3 范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片
修改 schema.xml 配置文件
<table name=\"payment_info\" dataNode=\"dn1,dn2\" rule=\"auto_sharding_long\" ></table>
修改 rule.xml 配置文件
<tableRule name=\"auto_sharding_long\">
<rule>
<columns>order_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
...
<function name=\"rang-long\" class=\"io.mycat.route.function.AutoPartitionByLong\">
<property name=\"mapFile\">autopartition-long.txt</property>
<property name=\"defaultNode\">0</property>
</function>
参数说明如下:
- columns:分片字段
- algorithm:分片函数
- mapFile:标识配置文件名称
- defaultNode:默认节点,小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错
修改 autopartition-long.txt 配置文件
0-102=0
103-200=1
重启 Mycat,访问 Mycat 创建表
# 支付信息表
CREATE TABLE payment_info
(
`id` INT AUTO_INCREMENT comment \'编号\',
`order_id` INT comment \'订单编号\',
`payment_status` INT comment \'支付状态\',
PRIMARY KEY(id)
);
# 插入数据
INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (2,102,1);
INSERT INTO payment_info (id,order_id ,payment_status) VALUES (3,103,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (4,104,1);
3.4 按日期(天)分片
此规则为按天分片,设定时间格式、范围
修改 schema.xml 配置文件
<table name=\"login_info\" dataNode=\"dn1,dn2\" rule=\"sharding_by_date\" ></table>
修改 rule.xml 配置文件
<tableRule name=\"sharding_by_date\">
<rule>
<columns>login_date</columns>
<algorithm>shardingByDate</algorithm>
</rule>
</tableRule>
...
<function name=\"shardingByDate\" class=\"io.mycat.route.function.PartitionByDate\">
<property name=\"dateFormat\">yyyy-MM-dd</property>
<property name=\"sBeginDate\">2019-01-01</property>
<property name=\"sEndDate\">2019-01-04</property>
<property name=\"sPartionDay\">2</property>
</function>
参数说明如下:
- columns:分片字段
- algorithm:分片函数
- dateFormat:日期格式
- sBeginDate:开始日期
- sEndDate:结束日期,代表数据达到了这个日期的分片后循环从开始分片插入
- sPartionDay:分区天数,即默认从开始日期算起,分隔两天一个分区
重启 Mycat,访问 Mycat 创建表
# 用户信息表
CREATE TABLE login_info
(
`id` INT AUTO_INCREMENT comment \'编号\',
`user_id` INT comment \'用户编号\',
`login_date` date comment \'登录日期\',
PRIMARY KEY(id)
);
# 插入数据
INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,\'2019-01-01\');
INSERT INTO login_info(id,user_id,login_date) VALUES (2,102,\'2019-01-02\');
INSERT INTO login_info(id,user_id,login_date) VALUES (3,103,\'2019-01-03\');
INSERT INTO login_info(id,user_id,login_date) VALUES (4,104,\'2019-01-04\');
INSERT INTO login_info(id,user_id,login_date) VALUES (5,103,\'2019-01-05\');
INSERT INTO login_info(id,user_id,login_date) VALUES (6,104,\'2019-01-06\');
4. 全局序列
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,Mycat 提供了全局 sequence,并且提供了包含本地配置和数据库配置等多种实现方式
4.1 本地文件
此方式 Mycat 将 sequence 配置到文件中,当使用到 sequence 中的配置后,Mycat 会取 classpath 中的 sequence_conf.properties 文件中 sequence 当前的值
- 优点:本地加载,读取速度较快
- 缺点:抗风险能力差,Mycat 所在主机宕机后,无法读取本地文件
4.2 数据库方式
利用数据库一个表来进行计数累加。但是并不是每次生成序列都读写数据库,这样效率太低。Mycat 会预加载一部分号段到 Mycat 的内存中,这样大部分读写序列都是在内存中完成的。如果内存中的号段用完了 Mycat 会再向数据库要一次
建库序列脚本如下:
#在 dn1 上创建全局序列表
CREATE TABLE MYCAT_SEQUENCE (NAME VARCHAR(50) NOT NULL,current_value INT NOT
NULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(NAME)) ENGINE=INNODB;
# 创建全局序列所需函数
DELIMITER $$
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval=\"-999999999,null\";
SELECT CONCAT(CAST(current_value AS CHAR),\",\",CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval;
END $$
DELIMITER ;
DELIMITER $$
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS
VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;
DELIMITER $$
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;
# 初始化序列表记录
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES (\'ORDERS\', 400000,
100);
修改 sequence_db_conf.properties 的配置:vim sequence_db_conf.properties
# 意思是 ORDERS 这个序列在 dn1 这个节点上
ORDERS=dn1
修改 server.xml
<property name=\"sequnceHandlerType\">1</property>
全局序列类型:
- 0:本地文件
- 1:数据库方式
- 2:时间戳方式
重启 Mycat,登录 Mycat,插入数据
insert into orders(id,amount,customer_id,order_type) values(next value for MYCATSEQ_ORDERS,1000,101,102);
4.3 时间戳方式
全局序列 ID = 64 位二进制(42(毫秒) + 5(机器 ID) + 5(业务编码) + 12(重复累加) 换算成十进制为 18 位数的 long 类型,每毫秒可以并发 12 位二进制的累加
- 优点:配置简单
- 缺点:18 位 ID 过长
4.4 自主生成全局序列
在 Java 项目里自己生成全局序列,可以利用 redis 的单线程原子性 incr 来生成序列
Mycat 高可用
在实际项目中,Mycat 服务也需要考虑高可用性,如果 Mycat 所在服务器出现宕机,或 Mycat 服务故障,需要有备机提供服务,需要考虑 Mycat 集群
1. 高可用方案
我们可以使用 HAProxy + Keepalived 配合两台 Mycat 搭起 Mycat 集群,实现高可用性。HAProxy 实现了 MyCat 多节点的集群高可用和负载均衡,而 HAProxy 自身的高可用则可以通过 Keepalived 来实现
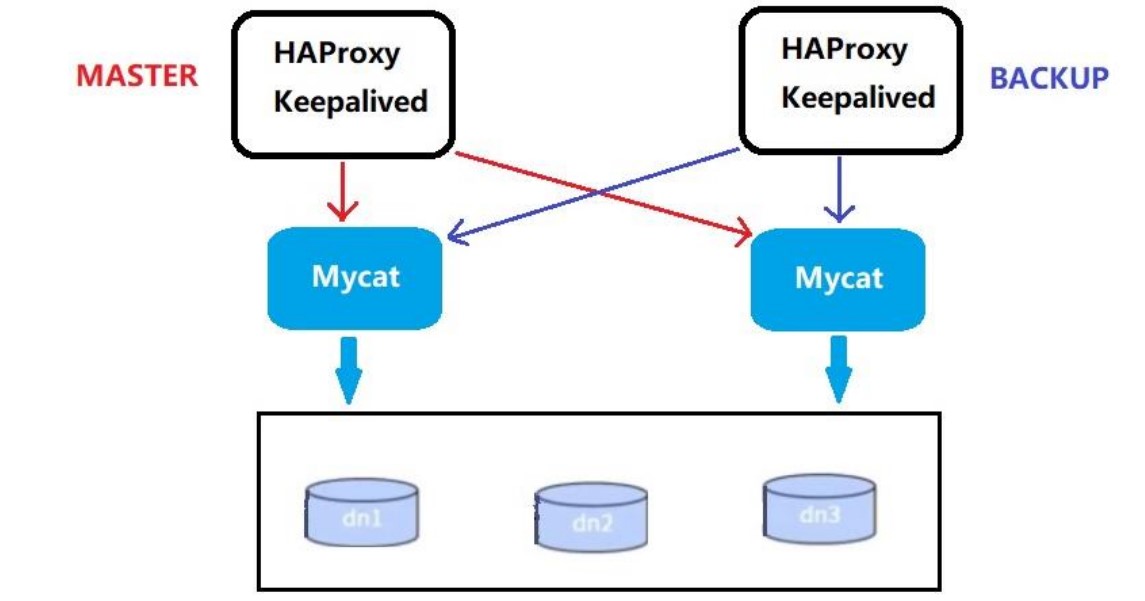
| 编号 | 角色 | IP 地址 | 机器名 |
|---|---|---|---|
| 1 | Mycat1 | 192.168.140.128 | host79 |
| 2 | Mycat2 | 192.168.140.127 | host80 |
| 3 | HAProxy(master) | 192.168.140.126 | host81 |
| 4 | Keepalived(master) | 192.168.140.125 | host82 |
| 5 | HAProxy(backup) | 192.168.140.124 | host83 |
| 6 | Keepalived(backup) | 192.168.140.123 | host84 |
2. HAProxy 安装配置
下载 HAProxy 安装包并解压,进入解压后的目录,查看内核版本,进行编译
# 查看内核版本
uname -r
# 进行编译
# ARGET=linux310 内核版本,如:3.10.0-514.el7,此时该参数就为linux310
# ARCH=x86_64,系统位数;
# PREFIX=/usr/local/haprpxy 为 haprpxy 安装路径
make TARGET=linux310 PREFIX=/usr/local/haproxy ARCH=x86_64
# 编译完成后进行安装
make install PREFIX=/usr/local/haproxy
# 安装完成后,创建目录和 HAProxy 配置文件
mkdir -p /usr/data/haproxy/
vim /usr/local/haproxy/haproxy.conf
向配置文件中插入以下配置信息并保存
global
log 127.0.0.1 local0
#log 127.0.0.1 local1 notice
#log loghost local0 info
maxconn 4096
chroot /usr/local/haproxy
pidfile /usr/data/haproxy/haproxy.pid
uid 99
gid 99
daemon
#debug
#quiet
defaults
log global
mode tcp
option abortonclose
option redispatch
retries 3
maxconn 2000
timeout connect 5000
timeout client 50000
timeout server 50000
listen proxy_status
bind :48066
mode tcp
balance roundrobin
server mycat_1 192.168.140.128:8066 check inter 10s
server mycat_2 192.168.140.127:8066 check inter 10s
frontend admin_stats
bind :7777
mode http
stats enable
option httplog
maxconn 10
stats refresh 30s
stats uri /admin
stats auth admin:123123
stats hide-version
stats admin if TRUE
启动验证
# 启动HAProxy
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.conf
# 查看 HAProxy 进程
ps -ef|grep haproxy
打开浏览器访问 http://192.168.140.125:7777/admin,在弹出框输入用户名:admin,密码:123123
通过 HAProxy 访问 Mycat
mysql -umycat -p123456 -h 192.168.140.126 -P 48066
3. KeepAlive 安装配置
下载 KeepAlive 安装包并解压,进入解压后的目录
# 安装依赖插件
yum install -y gcc openssl-devel popt-devel
# 进入解压后的目录进行配置和编译
cd /usr/local/src/keepalived-1.4.2
./configure --prefix=/usr/local/keepalived
# 编译完成后进行安装
make && make install
# 运行前配置
cp /usr/local/src/keepalived-1.4.2/keepalived/etc/init.d/keepalived /etc/init.d/
mkdir /etc/keepalived
cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
cp /usr/local/src/keepalived-1.4.2/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
修改配置文件:vim /etc/keepalived/keepalived.conf
# 修改内容如下
! Configuration File for keepalived
global_defs {
notification_email {
xlcocoon@foxmail.com
}
notification_email_from keepalived@showjoy.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
# 主机配 MASTER,备机配 BACKUP
state MASTER
# 所在机器网卡
interface ens33
virtual_router_id 51
# 数值越大优先级越高
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# 虚拟IP
192.168.140.200
}
}
virtual_server 192.168.140.200 48066 {
delay_loop 6
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
real_server 192.168.140.125 48066 {
weight 1
TCP_CHECK {
connect_timeout 3
retry 3
delay_before_retry 3
}
}
real_server 192.168.140.126 48600 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
启动验证
service keepalived start
登录验证
mysql -umycat -p123456 -h 192.168.140.200 -P 48066
Mycat 安全设置
1. 权限配置
1.1 user 标签权限控制
Mycat 对于中间件的连接控制并没有做太复杂的控制,只做了中间件逻辑库级别的读写权限控制,通过 server.xml 的 user 标签进行配置
# server.xml配置文件user部分
<user name=\"mycat\">
<property name=\"password\">123456</property>
<property name=\"schemas\">TESTDB</property>
</user>
<user name=\"user\">
<property name=\"password\">user</property>
<property name=\"schemas\">TESTDB</property>
<property name=\"readOnly\">true</property>
</user>
配置说明:
- name:应用连接中间件逻辑库的用户名
- password:该用户对应的密码
- TESTDB:应用当前连接的逻辑库中所对应的逻辑表,schemas 中可以配置一个或多个
- readOnly:应用连接中间件逻辑库所具有的权限,true 为只读,false 为读写都有,默认为 false
1.2 privileges 标签权限控制
在 user 标签下的 privileges 标签可以对逻辑库(schema)、表(table)进行精细化的 DML 权限控制
privileges 标签下的 check 属性,如为 true 开启权限检查,为 false 不开启,默认为 false。由于 Mycat 一个用户的 schemas 属性可配置多个逻辑库(schema),所以 privileges 的下级节点 schema 节点同样可配置多个,对多库多表进行细粒度的 DML 权限控制
# server.xml配置文件privileges部分
# 配置orders表没有增删改查权限
<user name=\"mycat\">
<property name=\"password\">123456</property>
<property name=\"schemas\">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<privileges check=\"true\">
<schema name=\"TESTDB\" dml=\"1111\" >
<table name=\"orders\" dml=\"0000\"></table>
<!--<table name=\"tb02\" dml=\"1111\"></table>-->
</schema>
</privileges>
</user>
配置说明:
| DML 权限 | 增加(insert) | 更新(update) | 查询(select) | 删除(select) |
|---|---|---|---|---|
| 0000 | 禁止 | 禁止 | 禁止 | 禁止 |
| 0010 | 禁止 | 禁止 | 可以 | 禁止 |
| 1110 | 可以 | 禁止 | 禁止 | 禁止 |
| 1111 | 可以 | 可以 | 可以 | 可以 |
2. SQL 拦截
firewall 标签用来定义防火墙,firewall 下 whitehost 标签用来定义 IP 白名单 ,blacklist 用来定义 SQL 黑名单
2.1 白名单
# 配置只有 192.168.140.128 主机可以通过 mycat 用户访问
<firewall>
<whitehost>
<host host=\"192.168.140.128\" user=\"mycat\"/>
</whitehost>
</firewall>
2.2 黑名单
可以通过设置黑名单,实现 Mycat 对具体 SQL 操作的拦截,如增删改查等操作的拦截
# 配置禁止mycat用户进行删除操作
<firewall>
<whitehost>
<host host=\"192.168.140.128\" user=\"mycat\"/>
</whitehost>
<blacklist check=\"true\">
<property name=\"deleteAllow\">false</property>
</blacklist>
</firewall>
可以设置的黑名单 SQL 拦截功能列表
| 配置项 | 缺省值 | 描述 |
|---|---|---|
| selelctAllow | true | 是否允许执行 SELECT 语句 |
| deleteAllow | true | 是否允许执行 DELETE 语句 |
| updateAllow | true | 是否允许执行 UPDATE 语句 |
| insertAllow | true | 是否允许执行 INSERT 语句 |
| createTableAllow | true | 是否允许创建表 |
| setAllow | true | 是否允许使用 SET 语法 |
| alterTableAllow | true | 是否允许执行 Alter Table 语句 |
| dropTableAllow | true | 是否允许修改表 |
| commitAllow | true | 是否允许执行 commit 操作 |
| rollbackAllow | true | 是否允许执行 roll back 操作 |
Mycat 监控工具
1. Mycat-web 简介
Mycat-web 是 Mycat 可视化运维的管理和监控平台,弥补了 Mycat 在监控上的空白。帮 Mycat 分担统计任务和配置管理任务。Mycat-web 引入了 ZooKeeper 作为配置中心,可以管理多个节点。 Mycat-web 主要管理和监控 Mycat 的流量、连接、活动线程和内存等,具备 IP 白名单、邮件告警等模块,还可以统计 SQL 并分析慢 SQL 和高频 SQL 等。为优化 SQL 提供依据。
2. Mycat-web 配置使用
首先安装 Zookeeper,下载安装包并解压,进入 ZooKeeper 解压后的配置目录(conf),复制配置文件并改名
cp zoo_sample.cfg zoo.cfg
进入 ZooKeeper 的命令目录(bin),运行启动命令
./zkServer.sh start
ZooKeeper 服务端口为 2181,查看服务已经启动
netstat -ant | grep 2181
3. Mycat-web 安装
下载安装包并解压,进入解压目录下运行启动命令
./start.sh &
Mycat-web 服务端口为 8082,查看服务已经启动
netstat -ant | grep 8082
通过地址访问服务:http://192.168.140.127:8082/mycat/
先在注册中心配置 ZooKeeper 地址,配置后刷新页面,可以看到配置页面
来源:https://www.cnblogs.com/Yee-Q/p/16065340.html
本站部分图文来源于网络,如有侵权请联系删除。