 百木园
百木园Pandas 可以对 Series 与 DataFrame 进行快速的描述性统计,方便快速了解数据的集中趋势和分布差异。源Excel文件descriptive_statistics.xlsx:
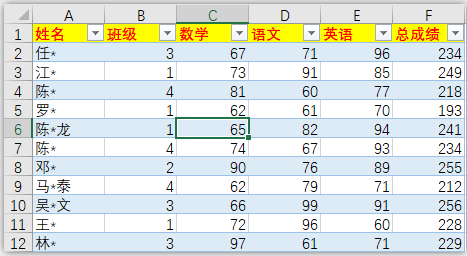
一、描述性统计汇总df.describe()
df.describe(percentiles=None, include=None, exclude=None)
参数说明:
- percentiles,百分位数,默认为[.25, .5, .75],即上下四分位数和中位数,其中,中位数一定输出;
- include,控制描述性统计输出包含的内容。
数值型和离散型特征数据(定序数据和定类数据)
默认值:None,即只输出数值型数据列的统计信息(count、mean、std、min、百分位数、max)。
\'all\':输入的所有列的统计信息。
\'O\':只输出 object(字符、定类数据)的统计信息:count、unique(分类分组数量)、top(出现次数最多的类别)、freq(top出现的频数) - exclude,和参数include是相反的,表示不输出哪些内容。
df.describe() # 默认:数值型数据,上下四分位和中位数
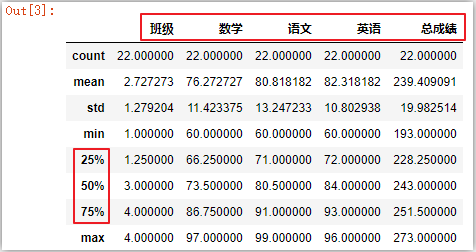
df.describe([]) # 只输出中位数
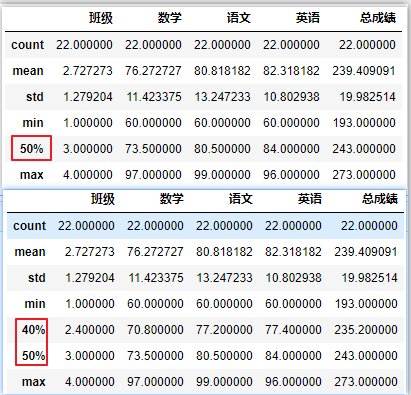
df.describe([.4]) # 中位数和40%分位数
# 指定类型:只输出字符型离散数据统计特征
df.describe(include=\'O\')
# df.describe(include=[np.object])
# 排除类型
df.describe(exclude=[np.number])

二、其他数学统计方法
DataFrame 计算后一般为一个 Series或df,Series 计算后为一个定值。
df.mean() # 返回所有列的均值
df.mean(1) # 返回所有行的均值,下同
df.corr() # 返回列与列之间的相关系数
df.count() # 返回每一列中的非空值的个数
df.max() # 返回每一列的最大值
df.min() # 返回每一列的最小值
df.abs() # 绝对值
df.median() # 返回每一列的中位数
df.std() # 返回每一列的标准差, 贝塞尔校正的样本标准偏差
df.var() # 无偏方差
df.sem() # 平均值的标准误差
df.mode() # 众数
df.prod() # 连乘
df.mad() # 平均绝对偏差
df.cumprod() # 累积连乘,累乘
df.cumsum(axis=0) # 累积连加,累加
df.nunique() # 去重数量,不同值的量
df.idxmax() # 每列最大的值的索引名
df.idxmin() # 最小
df.cummax() # 累积最大值
df.cummin() # 累积最小值
df.skew() # 样本偏度 (第三阶)
df.kurt() # 样本峰度 (第四阶)
df.quantile() # 样本分位数 (不同 % 的值)
特殊说明:
- 很多方法支持行列指定,默认为列axis=0;
- 是否排除缺失值,默认排除skipna=False;
- 假若索引为多层索引,支持索引层次选择,level参数控制;
- 是否排除bool值,numeric_only,默认为False,不排除;
- 如果有空值总共算几,min_count,默认为0,一个不算。
来源:https://www.cnblogs.com/xiaoshun-mjj/p/14682621.html
图文来源于网络,如有侵权请联系删除。