 百木园
百木园现在年轻人聊天,不带点表情包都不好意思说自己是年轻人, 表情包已然成为人与人聊天中不可缺少的部分。

刚认识的朋友丢几个表情包出去分分钟拉进关系,女朋友生闷气了整两个表情包开心一下,也可以化解尴尬,没时间打字整两张表情包,礼貌而不失尴尬。

一、欲扬先抑
准备工作很重要,先知道我们要干啥,用什么来做,怎么做,再去一步步实时,稳扎稳打。
开发环境配置
Python 3.6
Pycharm
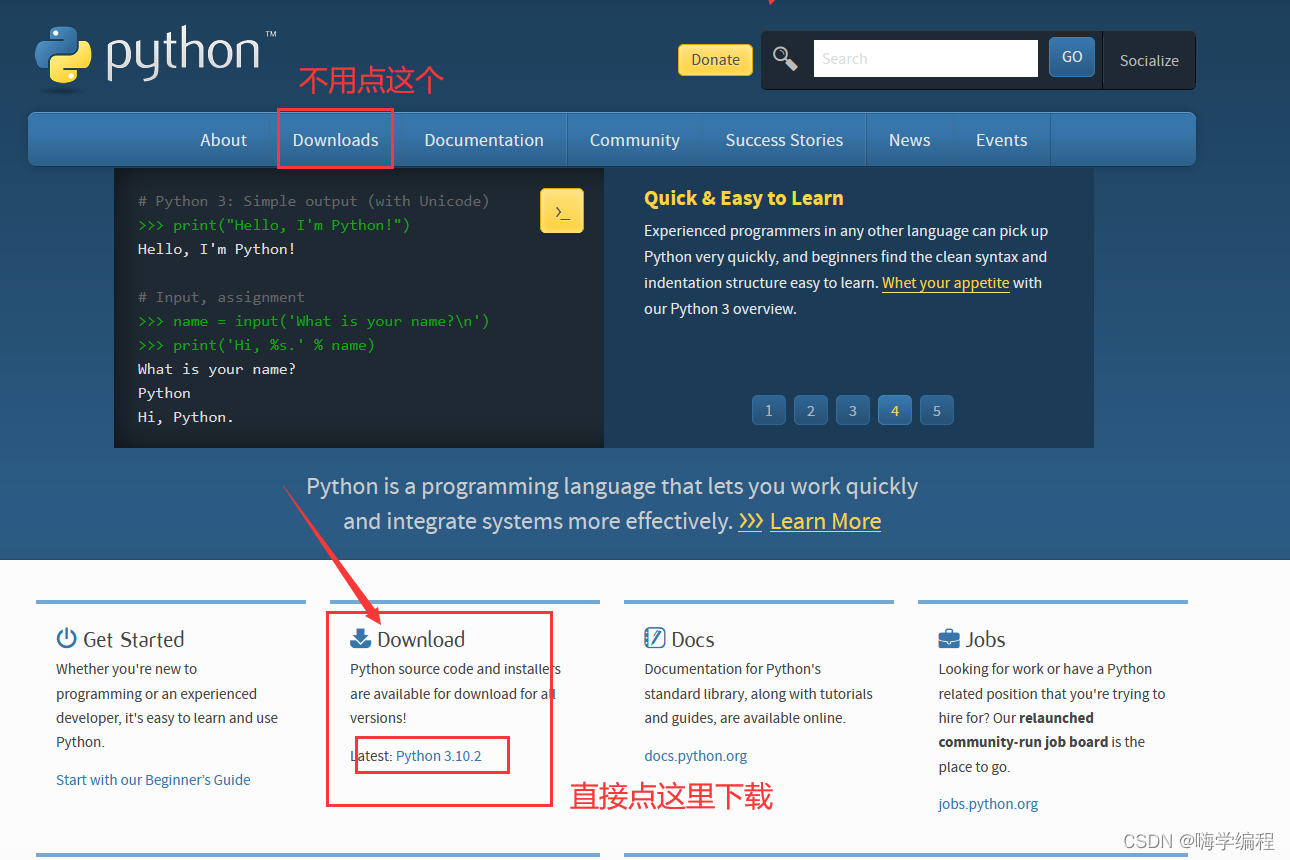
打开你的浏览器搜索你要安装的软件名字
Python
后面带官方的就是官网了,但凡名字下方带了广告二字就别点,自信点,那就是广告。

直接点下面的 Python 3.10.2 下载最新版本即可,不用点那啥 Download
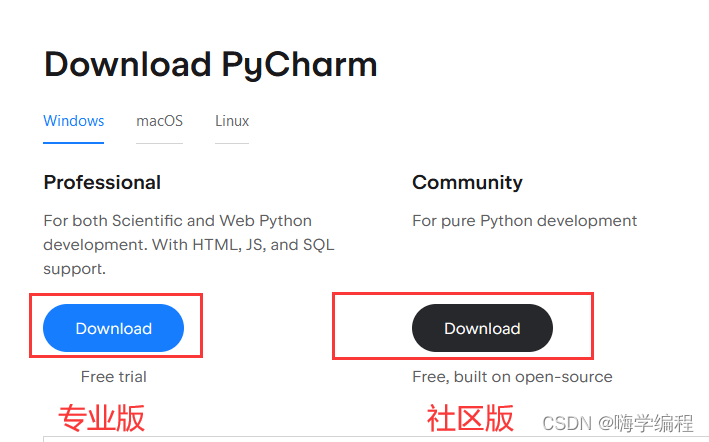
pycharm

随便点一个 Download
 专业版社区版都OK
专业版社区版都OK
# 安装方法一个个写太久了,可以加下群 # Python学习交流1群:924040232 # Python学习交流2群:815624229 # 我还给大家准备了大量的Python学习资料,直接在群里就可以免费领取了。
模块安装配置
requests
parsel
re
打开电脑,按住win+r,输入cmd,回车,输入pip install (加上要安装的模块名),回车即可安装。
二、代码
目标:fabiaoqing
地址前面后面大家自己补全一下,包括后面代码里的,这应该没有不会的吧。
导入模块
import requests import parsel import re import time
请求网址
url = f\'fabiaoqing/biaoqing/lists/page/{page}.html\'
请求头
headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36\' }
返回网页源代码
response = requests.get(url=url, headers=headers)
解析数据
selector = parsel.Selector(response.text) # 把respons.text 转换成 selector 对象
第一次提取 提取所有的div标签内容
divs = selector.css(\'#container div.tagbqppdiv\') # css 根据标签提取内容
通过标签内容提取他的图片url地址
img_url = div.css(\'img::attr(data-original)\').get()
提取标题
title = div.css(\'img::attr(title)\').get()
获取图片的后缀名
name = img_url.split(\'.\')[-1]
保存数据
new_title = change_title(title)
对表情包图片发送请求 获取它二进制数据
img_content = requests.get(url=img_url, headers=headers).content
保存数据
def save(title, img_url, name): img_content = get_response(img_url).content try: with open(\'img\\\\\' + title + \'.\' + name, mode=\'wb\') as f: # 写入图片二进制数据 f.write(img_content) print(\'正在保存:\', title) except: pass
替换标题中的特殊字符
因为文件命名不明还有特殊字符,所以我们需要通过正则表达式替换掉特殊字符。
def change_title(title): mode = re.compile(r\'[\\\\\\/\\:\\*\\?\\\"\\<\\>\\|]\') new_title = re.sub(mode, \"_\", title) return new_title
记录时间
time_2 = time.time() use_time = int(time_2) - int(time_1) print(f\'总共耗时:{use_time}秒\')
兄弟们,这里是单线程,下面是多线程,我就直接上代码了。
import requests import parsel import re import time import concurrent.futures def change_title(title): mode = re.compile(r\'[\\\\\\/\\:\\*\\?\\\"\\<\\>\\|]\') new_title = re.sub(mode, \"_\", title) return new_title def get_response(html_url): headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36\' } repsonse = requests.get(url=html_url, headers=headers) return repsonse def save(title, img_url, name): img_content = get_response(img_url).content try: with open(\'img\\\\\' + title + \'.\' + name, mode=\'wb\') as f: f.write(img_content) print(\'正在保存:\', title) except: pass def main(html_url): html_data = get_response(html_url).text selector = parsel.Selector(html_data) divs = selector.css(\'#container div.tagbqppdiv\') for div in divs: img_url = div.css(\'img::attr(data-original)\').get() title = div.css(\'img::attr(title)\').get() name = img_url.split(\'.\')[-1] new_title = change_title(title) save(new_title, img_url, name) if __name__ == \'__main__\': time_1 = time.time() exe = concurrent.futures.ThreadPoolExecutor(max_workers=10) for page in range(1, 201): url = f\'fabiaoqing/biaoqing/lists/page/{page}.html\' exe.submit(main, url) exe.shutdown() time_2 = time.time() use_time = int(time_2) - int(time_1) print(f\'总共耗时:{use_time}秒\')
兄弟们,18秒一千多张,这结束的有点快了啊

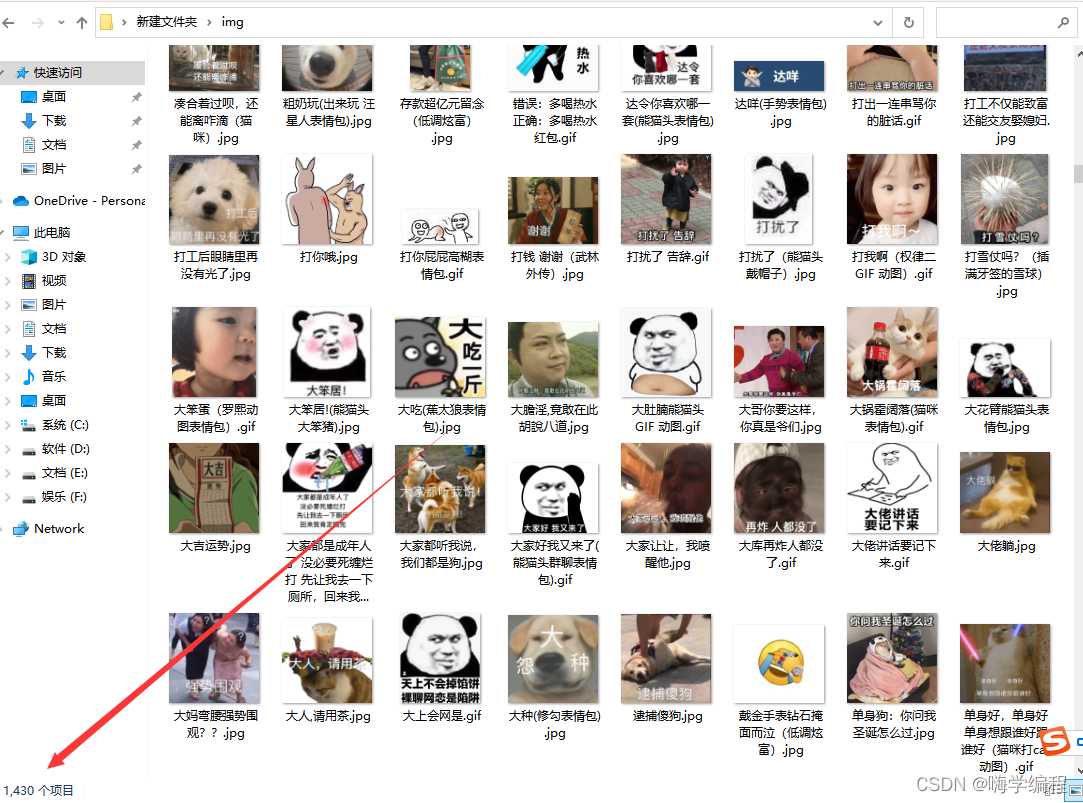
大家看完觉得有用的话,点个赞收藏一下呗,爱你摸摸大。
你看代码运行这么快,只要18秒,我可不希望大家平常生活中也这么快,嘿嘿,不太好~

来源:https://www.cnblogs.com/hahaa/p/15990045.html
本站部分图文来源于网络,如有侵权请联系删除。